Materi ini diproduksi oleh tim dari Algoritma untuk Correspondence Analysis for Brand Personalities. Materi berikut hanya ditujukan untuk kalangan terbatas, meliputi individu/personal yang menerima materi ini secara langsung dari lembaga pelatihan. Materi ini dilarang untuk direproduksi, didistribusikan, diterjemahkan, atau diadaptasikan dalam bentuk apapun di luar izin dari individu dan organisasi yang berkepentingan.
Algoritma adalah pusat pendidikan Data Science di Jakarta. Kami mengadakan workshop dan program pelatihan untuk membantu para profesional dan pelajar untuk mendapatkan keahlian dalam berbagai bidang dalam ruang lingkup Data Science: data visualization, machine learning, data modeling, statistical inference, dan lain-lainnya.
Sebelum masuk ke dalam materi dan menjalankan kode-kode di dalam materi ini, silakan Anda melihat bagian Library and Setup untuk melihat dan memastikan semua persyaratan dasar untuk mengikuti materi ini sudah terpenuhi termasuk package-package yang diperlukan. Pada bagian Tujuan Pembelajaran Anda dapat melihat secara umum apa saja yang akan dipelajari dalam modul materi ini. Kami harap materi ini akan bermanfaat bagi karir ataupun menambah keahlian peserta.
Preface
Pendahuluan
Istilah “Brand Personality” merujuk pada karakteristik sifat manusia yang dikaitkan dengan nama suatu brand. Perusahaan akan berusaha meningkatkan keuntungannya dengan cara memiliki seperangkat sifat konsisten yang disukai oleh target segmen konsumennya. Seperangkat sifat inilah yang disebut sebagai brand personality. Brand Personality merupakan aspek penting dari branding karena konsumen sering membuat keputusan pembelian berdasarkan seberapa cocok Brand Personality suatu produk dengan kepribadian mereka.
Perusahaan sebaiknya mendefinisikan Brand Personality mereka sehingga dapat menyasar konsumen atau pasar yang tepat untuk memaksimumkan profitnya. Brand personality juga menjadi sangat penting di tengah era digital ini dengan adanya Artificial Intelligence dan otomatisasi. Dengan demikian, pemetaan untuk brand personality dari tiap perusahaan dapat digunakan untuk mengembangkan strategi branding yang lebih efektif dan lebih sesuai dengan kebutuhan serta preferensi konsumen.
Correspondence Analysis adalah teknik statistik yang telah banyak digunakan dalam market research untuk memahami hubungan antara Brand Personality dan persepsi konsumen. Dengan analisis korespondensi, diperoleh plot yang menunjukkan interaksi dua variabel kategorik bersama yaitu variabel nama brand dan variabel brand personality. Sehingga dapat diketahui personality yang melekat dari masing-masing brand.
Materi ini bertujuan untuk memberikan pemahaman kepada peserta workshop terkait penggunaan Correspondence Analysis dalam mengidentifikasi Brand Personality dari suatu brand. Adapun setelah mempelajari materi ini peserta diharapkan dapat memahami kegunaan dan potensi Correspondence Analysis sesuai dengan proses bisnis pada bidang industri yang dijalani oleh peserta.

Library dan Setup
Untuk dapat mengikuti materi ini, peserta diharapkan sudah menginstall beberapa packages di bawah ini. Apabila package tersebut belum terinstall, silahkan jalankan chunk atau baris kode di bawah ini. Apabila sudah ter-install, lewati chunk tersebut dan muat package yang dibutuhkan dengan menjalankan chunk selanjutnya.
1
|
# install.packages(c("FactoMineR","factoextra", "dplyr", "ggpubr", "graphics", "ggplot2", "datasets"))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#data wrangling
library("dplyr")
#data analysis
library("FactoMineR")
library("factoextra")
#data visualization
library("ggpubr") #untuk balloonplot
library("graphics") #untuk mosaicplot
library("ggplot2")
#data reference
library("datasets")
|
Tujuan Pembelajaran
Tujuan utama dari workshop ini adalah untuk memberikan pengenalan yang komprehensif mengenai tools dan perangkat lunak yang digunakan untuk melakukan correspondence analysis, yakni sebuah open-source populer: R. Adapun materi ini akan mencakup:
Dasar Pemrograman di R
Import Data
Analisa data di R dimulai dengan membaca data yang sudah tersedia. Terdapat banyak format penyimpanan data mulai dari yang terstruktur hingga yang tidak terstruktur. Salah satu format data yang sering digunakan yaitu .csv. Untuk membaca data dengan format .csv bisa menggunakan fungsi read.csv().
1
2
|
brand_df <- read.csv("data/brand.csv")
brand_df
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#> Brand charming cheerful daring down_to_earth honest
#> 1 AmericanExpress 20 9 15 10 14
#> 2 Applecomputers 25 27 23 14 27
#> 3 Avoncosmetics 33 33 7 26 25
#> 4 CalvinKleinPerfume 59 25 50 7 13
#> 5 Campbell’sSoup 22 30 8 62 50
#> 6 ColgateToothpaste 20 45 13 51 56
#> 7 DietCoke 13 43 20 21 20
#> 8 GuessJeans 20 18 36 8 6
#> 9 HallmarkCards 58 57 6 28 51
#> 10 IBMComputers 11 10 16 12 26
#> 11 Kmart 12 48 12 68 45
#> 12 KodakFilm 19 42 8 35 50
#> 13 LeeJeans 12 22 24 40 14
#> 14 Lego 9 51 9 45 49
#> 15 Levi’sJeans 27 35 49 47 31
#> 16 Lexus 40 10 32 7 23
#> 17 MattelToys 15 62 7 24 28
#> 18 McDonald’s 10 64 10 33 15
#> 19 Mercedes 52 23 39 6 35
#> 20 MichelinTires 7 12 23 31 38
#> 21 NikeAthleticShoes 9 24 48 17 12
#> 22 OilofOlayLotion 46 20 11 29 33
#> 23 PepsiCola 11 53 29 24 18
#> 24 Porsche 50 24 76 5 35
#> 25 ReebokAthleticShoes 13 31 44 21 22
#> 26 RevlonCosmetics 45 27 18 19 11
#> 27 SonyTelevisions 22 24 27 18 35
#> 28 Toyota 19 26 19 41 39
#> 29 Visa 18 18 24 20 24
#> imaginative intelligent outdoorsy reliable spirited successful tough
#> 1 17 44 14 26 14 63 20
#> 2 54 71 4 32 34 43 13
#> 3 20 10 6 23 7 23 6
#> 4 31 16 11 21 38 44 5
#> 5 11 11 16 53 14 31 12
#> 6 17 32 12 82 19 56 23
#> 7 26 9 35 31 29 48 10
#> 8 14 7 22 9 18 21 18
#> 9 54 24 4 50 24 44 5
#> 10 51 75 2 56 18 65 31
#> 11 17 17 30 46 13 45 12
#> 12 33 38 54 67 16 50 12
#> 13 12 5 59 19 23 17 44
#> 14 58 32 6 41 17 37 32
#> 15 23 16 72 52 47 54 71
#> 16 29 49 32 42 24 50 25
#> 17 62 18 14 24 17 29 22
#> 18 25 15 18 30 16 59 14
#> 19 28 61 36 66 35 79 43
#> 20 14 41 66 55 31 40 79
#> 21 43 21 80 38 54 50 58
#> 22 16 21 11 37 14 28 4
#> 23 33 6 37 29 36 37 11
#> 24 49 64 48 52 64 83 36
#> 25 41 27 87 41 55 50 54
#> 26 30 13 9 31 14 42 6
#> 27 59 69 5 64 30 61 12
#> 28 33 41 64 66 36 56 59
#> 29 18 44 22 61 26 69 28
#> up_to_date upper_class wholesome
#> 1 30 69 8
#> 2 53 33 24
#> 3 20 6 26
#> 4 30 81 10
#> 5 19 11 80
#> 6 37 9 52
#> 7 43 6 17
#> 8 27 36 6
#> 9 23 35 49
#> 10 55 38 26
#> 11 29 3 45
#> 12 33 17 29
#> 13 24 11 10
#> 14 20 5 39
#> 15 46 30 26
#> 16 48 76 13
#> 17 30 6 23
#> 18 39 4 16
#> 19 55 94 27
#> 20 29 33 17
#> 21 54 40 16
#> 22 19 39 43
#> 23 38 7 13
#> 24 54 89 12
#> 25 51 30 17
#> 26 32 38 25
#> 27 78 41 21
#> 28 48 15 36
#> 29 52 40 18
|
Deskripsi Data
brand_df merupakan data yang akan digunakan pada implementasi Correspondence Analysis for Brand Personalities, diperoleh dari paper milik Jack Hoare & Tim Bock (2019). Data tersebut terdiri dari 29 brand (baris) dan 15 atribut personality (kolom). Data dikumpulkan menggunakan metode nonprobability sampling dari 3173 orang dewasa di Australia pada tahun 2005. Responden diminta untuk menentukan tiga atribut personality untuk setiap brand yang ditunjukkan.

Salah satu cara untuk melihat data adalah menggunakan fungsi head()
1
2
|
#your code here
head(brand_df, n = 10)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#> Brand charming cheerful daring down_to_earth honest imaginative
#> 1 AmericanExpress 20 9 15 10 14 17
#> 2 Applecomputers 25 27 23 14 27 54
#> 3 Avoncosmetics 33 33 7 26 25 20
#> 4 CalvinKleinPerfume 59 25 50 7 13 31
#> 5 Campbell’sSoup 22 30 8 62 50 11
#> 6 ColgateToothpaste 20 45 13 51 56 17
#> 7 DietCoke 13 43 20 21 20 26
#> 8 GuessJeans 20 18 36 8 6 14
#> 9 HallmarkCards 58 57 6 28 51 54
#> 10 IBMComputers 11 10 16 12 26 51
#> intelligent outdoorsy reliable spirited successful tough up_to_date
#> 1 44 14 26 14 63 20 30
#> 2 71 4 32 34 43 13 53
#> 3 10 6 23 7 23 6 20
#> 4 16 11 21 38 44 5 30
#> 5 11 16 53 14 31 12 19
#> 6 32 12 82 19 56 23 37
#> 7 9 35 31 29 48 10 43
#> 8 7 22 9 18 21 18 27
#> 9 24 4 50 24 44 5 23
#> 10 75 2 56 18 65 31 55
#> upper_class wholesome
#> 1 69 8
#> 2 33 24
#> 3 6 26
#> 4 81 10
#> 5 11 80
#> 6 9 52
#> 7 6 17
#> 8 36 6
#> 9 35 49
#> 10 38 26
|
Data di atas merupakan data brand dengan deskripsi dari setiap kolom sebagai berikut:
Brand : nama brandcharming : skor atribut/personality “menarik”cheerful : skor atribut/personality “ceria”daring : skor atribut/personality “berani”down_to_earth : skor atribut/personality “bersahaja”honest : skor atribut/personality “jujur”imaginative : skor atribut/personality “imajinatif”intelligent : skor atribut/personality “cerdas”outdoorsy : skor atribut/personality “tipe luar ruangan”reliable : skor atribut/personality “dapat diandalkan”spirited : skor atribut/personality “bersemangat”successful : skor atribut/personality “sukses”tough : skor atribut/personality “tangguh”up_to_date : skor atribut/personality “terkini”upper_class : skor atribut/personality “kelas sosial atas”wholesome : skor atribut/personality “sehat/baik”
Untuk mengetahui 10 baris terakhir pada data, kita dapat menggunakan fungsi tail().
1
2
|
#your code here
tail(brand_df, n=10)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#> Brand charming cheerful daring down_to_earth honest
#> 20 MichelinTires 7 12 23 31 38
#> 21 NikeAthleticShoes 9 24 48 17 12
#> 22 OilofOlayLotion 46 20 11 29 33
#> 23 PepsiCola 11 53 29 24 18
#> 24 Porsche 50 24 76 5 35
#> 25 ReebokAthleticShoes 13 31 44 21 22
#> 26 RevlonCosmetics 45 27 18 19 11
#> 27 SonyTelevisions 22 24 27 18 35
#> 28 Toyota 19 26 19 41 39
#> 29 Visa 18 18 24 20 24
#> imaginative intelligent outdoorsy reliable spirited successful tough
#> 20 14 41 66 55 31 40 79
#> 21 43 21 80 38 54 50 58
#> 22 16 21 11 37 14 28 4
#> 23 33 6 37 29 36 37 11
#> 24 49 64 48 52 64 83 36
#> 25 41 27 87 41 55 50 54
#> 26 30 13 9 31 14 42 6
#> 27 59 69 5 64 30 61 12
#> 28 33 41 64 66 36 56 59
#> 29 18 44 22 61 26 69 28
#> up_to_date upper_class wholesome
#> 20 29 33 17
#> 21 54 40 16
#> 22 19 39 43
#> 23 38 7 13
#> 24 54 89 12
#> 25 51 30 17
#> 26 32 38 25
#> 27 78 41 21
#> 28 48 15 36
#> 29 52 40 18
|
Data Type and Structure
Kita sudah mempelajari bagaimana mengecek sampel dari data, sekarang kita perlu mengetahui tipe data dari masing masing kolom yang ada. Kita bisa menggunakan fungsi glimpse() untuk melihat struktur serta dimensi dari data.
1
2
3
|
#your code here
library(dplyr)
glimpse(brand_df)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#> Rows: 29
#> Columns: 16
#> $ Brand <chr> "AmericanExpress", "Applecomputers", "Avoncosmetics", "C…
#> $ charming <int> 20, 25, 33, 59, 22, 20, 13, 20, 58, 11, 12, 19, 12, 9, 2…
#> $ cheerful <int> 9, 27, 33, 25, 30, 45, 43, 18, 57, 10, 48, 42, 22, 51, 3…
#> $ daring <int> 15, 23, 7, 50, 8, 13, 20, 36, 6, 16, 12, 8, 24, 9, 49, 3…
#> $ down_to_earth <int> 10, 14, 26, 7, 62, 51, 21, 8, 28, 12, 68, 35, 40, 45, 47…
#> $ honest <int> 14, 27, 25, 13, 50, 56, 20, 6, 51, 26, 45, 50, 14, 49, 3…
#> $ imaginative <int> 17, 54, 20, 31, 11, 17, 26, 14, 54, 51, 17, 33, 12, 58, …
#> $ intelligent <int> 44, 71, 10, 16, 11, 32, 9, 7, 24, 75, 17, 38, 5, 32, 16,…
#> $ outdoorsy <int> 14, 4, 6, 11, 16, 12, 35, 22, 4, 2, 30, 54, 59, 6, 72, 3…
#> $ reliable <int> 26, 32, 23, 21, 53, 82, 31, 9, 50, 56, 46, 67, 19, 41, 5…
#> $ spirited <int> 14, 34, 7, 38, 14, 19, 29, 18, 24, 18, 13, 16, 23, 17, 4…
#> $ successful <int> 63, 43, 23, 44, 31, 56, 48, 21, 44, 65, 45, 50, 17, 37, …
#> $ tough <int> 20, 13, 6, 5, 12, 23, 10, 18, 5, 31, 12, 12, 44, 32, 71,…
#> $ up_to_date <int> 30, 53, 20, 30, 19, 37, 43, 27, 23, 55, 29, 33, 24, 20, …
#> $ upper_class <int> 69, 33, 6, 81, 11, 9, 6, 36, 35, 38, 3, 17, 11, 5, 30, 7…
#> $ wholesome <int> 8, 24, 26, 10, 80, 52, 17, 6, 49, 26, 45, 29, 10, 39, 26…
|
brand_df merupakan sebuah ‘data.frame’ atau tabel dengan 29 baris dan 16 kolom. Nama dari setiap kolom tertera di sebelah kanan (Brand, charming, dll). Teks chr, int menunjukkan tipe data dari masing - masing kolom.
Data Type in R
Terdapat berbagai macam tipe data di R, berikut intuisi dari setiap tipe data tersebut.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# character
a_char <- c("Algoritma", "Indonesia", "e-Commerce", "marketing")
# factor (data categorical)
a_factor <- factor(c("AB", "O", "B", "A", "B", "AB", "O"))
# numeric
a_num <- c(-1, 1, 2, 3/4, 0.5)
# integer
an_int <- c(1L, 2L)
# date
a_date <- c("24/Jan/2019", "10-12-1994")
# logical
a_log <- c(TRUE, TRUE, FALSE)
|
Cara untuk mengetahui tipe data dari suatu objek, Anda dapat menggunakan fungsi class()
Lalu, apa yang akan terjadi jika dalam satu vector memiliki beberapa tipe data yang berbeda seperti chunk dibawah ini?
1
2
|
mix <- c("Algoritma", 2021, TRUE)
mix
|
1
|
#> [1] "Algoritma" "2021" "TRUE"
|
Bila Anda perhatikan setiap nilai pada vector mix memiliki petik dua, artinya nilai tersebut merupakan sebuah objek dengan tipe character. Proses perubahan paksa dari suatu vector bisa disebut sebagai implicit coercion. Ilustrasi terjadinya implicit coercion dapat dilihat pada gambar di bawah ini:

1
2
|
#your code here
class(mix)
|
Data Preprocessing
Ketika melakukan analisis pada suatu data tidak jarang data yang dimiliki tidak dapat langsung digunakan. Beberapa tahapan perlu dilakukan seperti subseting data, membuat kolom baru, sampai melakukan aggregasi data. Hal tersebut penting dilakukan agar seorang analis paham betul dengan data yang diolah dan sesuai dengan analisis yang diinginkan.
Data Aggregation: Create Contingency Table
Tabel kontingensi atau cross-tabulation adalah tabel yang berisi nilai frekuensi/kemunculan suatu kategori data.
Correspondence Analysis memerlukan input yang disebut sebagai tabel kontingensi. Tabel kontingensi terdiri dari baris dan kolom, dengan setiap baris mewakili kategori dari variabel pertama, dan setiap kolom mewakili kategori dari variabel kedua.

Jika kita memiliki dataframe biasa dimana terdapat beberapa kolom dengan tipe data yang berbeda-beda (biasanya tipe kategorik dan numerik), perlu dilakukan data aggregation untuk membentuk tabel kontingensi.
Untuk pembelajaran pembuatan tabel kontingensi dari dataframe, perhatikan dataframe buit in di R dari package datasets yang dapat dipanggil dengan nama esoph berikut.
1
2
3
|
# Memanggil data esoph
library(datasets)
esoph
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
#> agegp alcgp tobgp ncases ncontrols
#> 1 25-34 0-39g/day 0-9g/day 0 40
#> 2 25-34 0-39g/day 10-19 0 10
#> 3 25-34 0-39g/day 20-29 0 6
#> 4 25-34 0-39g/day 30+ 0 5
#> 5 25-34 40-79 0-9g/day 0 27
#> 6 25-34 40-79 10-19 0 7
#> 7 25-34 40-79 20-29 0 4
#> 8 25-34 40-79 30+ 0 7
#> 9 25-34 80-119 0-9g/day 0 2
#> 10 25-34 80-119 10-19 0 1
#> 11 25-34 80-119 30+ 0 2
#> 12 25-34 120+ 0-9g/day 0 1
#> 13 25-34 120+ 10-19 1 0
#> 14 25-34 120+ 20-29 0 1
#> 15 25-34 120+ 30+ 0 2
#> 16 35-44 0-39g/day 0-9g/day 0 60
#> 17 35-44 0-39g/day 10-19 1 13
#> 18 35-44 0-39g/day 20-29 0 7
#> 19 35-44 0-39g/day 30+ 0 8
#> 20 35-44 40-79 0-9g/day 0 35
#> 21 35-44 40-79 10-19 3 20
#> 22 35-44 40-79 20-29 1 13
#> 23 35-44 40-79 30+ 0 8
#> 24 35-44 80-119 0-9g/day 0 11
#> 25 35-44 80-119 10-19 0 6
#> 26 35-44 80-119 20-29 0 2
#> 27 35-44 80-119 30+ 0 1
#> 28 35-44 120+ 0-9g/day 2 1
#> 29 35-44 120+ 10-19 0 3
#> 30 35-44 120+ 20-29 2 2
#> 31 45-54 0-39g/day 0-9g/day 1 45
#> 32 45-54 0-39g/day 10-19 0 18
#> 33 45-54 0-39g/day 20-29 0 10
#> 34 45-54 0-39g/day 30+ 0 4
#> 35 45-54 40-79 0-9g/day 6 32
#> 36 45-54 40-79 10-19 4 17
#> 37 45-54 40-79 20-29 5 10
#> 38 45-54 40-79 30+ 5 2
#> 39 45-54 80-119 0-9g/day 3 13
#> 40 45-54 80-119 10-19 6 8
#> 41 45-54 80-119 20-29 1 4
#> 42 45-54 80-119 30+ 2 2
#> 43 45-54 120+ 0-9g/day 4 0
#> 44 45-54 120+ 10-19 3 1
#> 45 45-54 120+ 20-29 2 1
#> 46 45-54 120+ 30+ 4 0
#> 47 55-64 0-39g/day 0-9g/day 2 47
#> 48 55-64 0-39g/day 10-19 3 19
#> 49 55-64 0-39g/day 20-29 3 9
#> 50 55-64 0-39g/day 30+ 4 2
#> 51 55-64 40-79 0-9g/day 9 31
#> 52 55-64 40-79 10-19 6 15
#> 53 55-64 40-79 20-29 4 13
#> 54 55-64 40-79 30+ 3 3
#> 55 55-64 80-119 0-9g/day 9 9
#> 56 55-64 80-119 10-19 8 7
#> 57 55-64 80-119 20-29 3 3
#> 58 55-64 80-119 30+ 4 0
#> 59 55-64 120+ 0-9g/day 5 5
#> 60 55-64 120+ 10-19 6 1
#> 61 55-64 120+ 20-29 2 1
#> 62 55-64 120+ 30+ 5 1
#> 63 65-74 0-39g/day 0-9g/day 5 43
#> 64 65-74 0-39g/day 10-19 4 10
#> 65 65-74 0-39g/day 20-29 2 5
#> 66 65-74 0-39g/day 30+ 0 2
#> 67 65-74 40-79 0-9g/day 17 17
#> 68 65-74 40-79 10-19 3 7
#> 69 65-74 40-79 20-29 5 4
#> 70 65-74 80-119 0-9g/day 6 7
#> 71 65-74 80-119 10-19 4 8
#> 72 65-74 80-119 20-29 2 1
#> 73 65-74 80-119 30+ 1 0
#> 74 65-74 120+ 0-9g/day 3 1
#> 75 65-74 120+ 10-19 1 1
#> 76 65-74 120+ 20-29 1 0
#> 77 65-74 120+ 30+ 1 0
#> 78 75+ 0-39g/day 0-9g/day 1 17
#> 79 75+ 0-39g/day 10-19 2 4
#> 80 75+ 0-39g/day 30+ 1 2
#> 81 75+ 40-79 0-9g/day 2 3
#> 82 75+ 40-79 10-19 1 2
#> 83 75+ 40-79 20-29 0 3
#> 84 75+ 40-79 30+ 1 0
#> 85 75+ 80-119 0-9g/day 1 0
#> 86 75+ 80-119 10-19 1 0
#> 87 75+ 120+ 0-9g/day 2 0
#> 88 75+ 120+ 10-19 1 0
|
Data esoph adalah data dari studi kasus-kontrol kanker esofagus di Ille-et-Vilaine, Prancis. Terdiri dari 88 observasi dan 5 kolom, dengan deskripsi sebagai berikut.
agegp : Kelompok usia (25-34, 35-44, 45-54, 55-64, 65-74, 75+)alcgp : Konsumsi alkohol (0-39g/day, 40-79, 80-119, 120+)tobgp : Konsumsi tembakau (0-9g/day, 10-19, 20-29, 30+)ncases : Jumlah kasus kankerncontrols : Jumlah kontrol
Data esoph di atas dapat kita bentuk menjadi tabel kontingensi menggunakan fungsi table() di R.
Fungsi table() adalah untuk menampilkan frekuensi tiap kategori dari dua variabel
Untuk membuat tabel kontingensi, pertama-tama kita harus mengidentifikasi variabel kategorik mana yang ingin dianalisis. Misalkan kita ingin menganalisis hubungan dari kelompok usia seseorang dengan konsumsi tembakau. Berikut akan dibuat tabel kontingensi dari variabel agegp dan tobgp.
1
2
|
#your code here
table(esoph$agegp, esoph$tobgp)
|
1
2
3
4
5
6
7
8
|
#>
#> 0-9g/day 10-19 20-29 30+
#> 25-34 4 4 3 4
#> 35-44 4 4 4 3
#> 45-54 4 4 4 4
#> 55-64 4 4 4 4
#> 65-74 4 4 4 3
#> 75+ 4 4 1 2
|
Tabel kontingensi di atas menunjukkan jumlah orang-orang di Ille-et-Vilaine yang berusia kategori usia tertentu dengan ketegori konsumsi tembakau tertentu.
Insight:
- Baris akan mewakili kategori dari variable agegp (kelompok usia)
- Kolom akan mewakili kategori dari variable tobgp (kelompok konsumsi tembakau)
- Setiap sel dalam tabel akan menunjukkan frekuensi dari variabel agegp dan tobgp. Misalnya angka 1 di baris ke-6 dan kolom ke-3 itu menunjukkan frekuensi orang yang punya kelompok usia 75+ dengan konsumsi tembakau 20-29 g/hari.
Untuk menginterpretasikan tabel kontingensi, Anda dapat melihat frekuensi di setiap sel, dan membandingkannya dengan frekuensi di sel lain melintasi baris dan kolom. Anda juga dapat menghitung persentase atau proporsi untuk lebih memahami distribusi pengamatan. Correspondence Analysis yang akan kita bahas merupakan salah satu teknik advance untuk interpretasi tabel kontingensi.
Question?
Apakah data brand_df merupakan tabel kontingensi?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#> Brand charming cheerful daring down_to_earth honest
#> 1 AmericanExpress 20 9 15 10 14
#> 2 Applecomputers 25 27 23 14 27
#> 3 Avoncosmetics 33 33 7 26 25
#> 4 CalvinKleinPerfume 59 25 50 7 13
#> 5 Campbell’sSoup 22 30 8 62 50
#> 6 ColgateToothpaste 20 45 13 51 56
#> 7 DietCoke 13 43 20 21 20
#> 8 GuessJeans 20 18 36 8 6
#> 9 HallmarkCards 58 57 6 28 51
#> 10 IBMComputers 11 10 16 12 26
#> 11 Kmart 12 48 12 68 45
#> 12 KodakFilm 19 42 8 35 50
#> 13 LeeJeans 12 22 24 40 14
#> 14 Lego 9 51 9 45 49
#> 15 Levi’sJeans 27 35 49 47 31
#> 16 Lexus 40 10 32 7 23
#> 17 MattelToys 15 62 7 24 28
#> 18 McDonald’s 10 64 10 33 15
#> 19 Mercedes 52 23 39 6 35
#> 20 MichelinTires 7 12 23 31 38
#> 21 NikeAthleticShoes 9 24 48 17 12
#> 22 OilofOlayLotion 46 20 11 29 33
#> 23 PepsiCola 11 53 29 24 18
#> 24 Porsche 50 24 76 5 35
#> 25 ReebokAthleticShoes 13 31 44 21 22
#> 26 RevlonCosmetics 45 27 18 19 11
#> 27 SonyTelevisions 22 24 27 18 35
#> 28 Toyota 19 26 19 41 39
#> 29 Visa 18 18 24 20 24
#> imaginative intelligent outdoorsy reliable spirited successful tough
#> 1 17 44 14 26 14 63 20
#> 2 54 71 4 32 34 43 13
#> 3 20 10 6 23 7 23 6
#> 4 31 16 11 21 38 44 5
#> 5 11 11 16 53 14 31 12
#> 6 17 32 12 82 19 56 23
#> 7 26 9 35 31 29 48 10
#> 8 14 7 22 9 18 21 18
#> 9 54 24 4 50 24 44 5
#> 10 51 75 2 56 18 65 31
#> 11 17 17 30 46 13 45 12
#> 12 33 38 54 67 16 50 12
#> 13 12 5 59 19 23 17 44
#> 14 58 32 6 41 17 37 32
#> 15 23 16 72 52 47 54 71
#> 16 29 49 32 42 24 50 25
#> 17 62 18 14 24 17 29 22
#> 18 25 15 18 30 16 59 14
#> 19 28 61 36 66 35 79 43
#> 20 14 41 66 55 31 40 79
#> 21 43 21 80 38 54 50 58
#> 22 16 21 11 37 14 28 4
#> 23 33 6 37 29 36 37 11
#> 24 49 64 48 52 64 83 36
#> 25 41 27 87 41 55 50 54
#> 26 30 13 9 31 14 42 6
#> 27 59 69 5 64 30 61 12
#> 28 33 41 64 66 36 56 59
#> 29 18 44 22 61 26 69 28
#> up_to_date upper_class wholesome
#> 1 30 69 8
#> 2 53 33 24
#> 3 20 6 26
#> 4 30 81 10
#> 5 19 11 80
#> 6 37 9 52
#> 7 43 6 17
#> 8 27 36 6
#> 9 23 35 49
#> 10 55 38 26
#> 11 29 3 45
#> 12 33 17 29
#> 13 24 11 10
#> 14 20 5 39
#> 15 46 30 26
#> 16 48 76 13
#> 17 30 6 23
#> 18 39 4 16
#> 19 55 94 27
#> 20 29 33 17
#> 21 54 40 16
#> 22 19 39 43
#> 23 38 7 13
#> 24 54 89 12
#> 25 51 30 17
#> 26 32 38 25
#> 27 78 41 21
#> 28 48 15 36
#> 29 52 40 18
|
Jawaban: brand_df bukan merupakan tabel kontingensi, karena tabel kontingensi seharusnya punya index kolom dan index baris, sementara brand_df belum memiliki index baris (index baris menjadi isi dari suatu kolom)
Feature Engineering
Untuk membuat databrand_df menjadi tabel kontingensi, kolom Brand akan dijadikan indeks baris. Sehingga index baris pada tabel menunjukkan variabel brand dan index kolom menunjukkan atribut personality.
1
2
3
|
# Assign nilai dari kolom brand menjadi index baris
rownames(brand_df) <- brand_df$Brand
brand_df
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#> Brand charming cheerful daring down_to_earth
#> AmericanExpress AmericanExpress 20 9 15 10
#> Applecomputers Applecomputers 25 27 23 14
#> Avoncosmetics Avoncosmetics 33 33 7 26
#> CalvinKleinPerfume CalvinKleinPerfume 59 25 50 7
#> Campbell’sSoup Campbell’sSoup 22 30 8 62
#> ColgateToothpaste ColgateToothpaste 20 45 13 51
#> DietCoke DietCoke 13 43 20 21
#> GuessJeans GuessJeans 20 18 36 8
#> HallmarkCards HallmarkCards 58 57 6 28
#> IBMComputers IBMComputers 11 10 16 12
#> Kmart Kmart 12 48 12 68
#> KodakFilm KodakFilm 19 42 8 35
#> LeeJeans LeeJeans 12 22 24 40
#> Lego Lego 9 51 9 45
#> Levi’sJeans Levi’sJeans 27 35 49 47
#> Lexus Lexus 40 10 32 7
#> MattelToys MattelToys 15 62 7 24
#> McDonald’s McDonald’s 10 64 10 33
#> Mercedes Mercedes 52 23 39 6
#> MichelinTires MichelinTires 7 12 23 31
#> NikeAthleticShoes NikeAthleticShoes 9 24 48 17
#> OilofOlayLotion OilofOlayLotion 46 20 11 29
#> PepsiCola PepsiCola 11 53 29 24
#> Porsche Porsche 50 24 76 5
#> ReebokAthleticShoes ReebokAthleticShoes 13 31 44 21
#> RevlonCosmetics RevlonCosmetics 45 27 18 19
#> SonyTelevisions SonyTelevisions 22 24 27 18
#> Toyota Toyota 19 26 19 41
#> Visa Visa 18 18 24 20
#> honest imaginative intelligent outdoorsy reliable spirited
#> AmericanExpress 14 17 44 14 26 14
#> Applecomputers 27 54 71 4 32 34
#> Avoncosmetics 25 20 10 6 23 7
#> CalvinKleinPerfume 13 31 16 11 21 38
#> Campbell’sSoup 50 11 11 16 53 14
#> ColgateToothpaste 56 17 32 12 82 19
#> DietCoke 20 26 9 35 31 29
#> GuessJeans 6 14 7 22 9 18
#> HallmarkCards 51 54 24 4 50 24
#> IBMComputers 26 51 75 2 56 18
#> Kmart 45 17 17 30 46 13
#> KodakFilm 50 33 38 54 67 16
#> LeeJeans 14 12 5 59 19 23
#> Lego 49 58 32 6 41 17
#> Levi’sJeans 31 23 16 72 52 47
#> Lexus 23 29 49 32 42 24
#> MattelToys 28 62 18 14 24 17
#> McDonald’s 15 25 15 18 30 16
#> Mercedes 35 28 61 36 66 35
#> MichelinTires 38 14 41 66 55 31
#> NikeAthleticShoes 12 43 21 80 38 54
#> OilofOlayLotion 33 16 21 11 37 14
#> PepsiCola 18 33 6 37 29 36
#> Porsche 35 49 64 48 52 64
#> ReebokAthleticShoes 22 41 27 87 41 55
#> RevlonCosmetics 11 30 13 9 31 14
#> SonyTelevisions 35 59 69 5 64 30
#> Toyota 39 33 41 64 66 36
#> Visa 24 18 44 22 61 26
#> successful tough up_to_date upper_class wholesome
#> AmericanExpress 63 20 30 69 8
#> Applecomputers 43 13 53 33 24
#> Avoncosmetics 23 6 20 6 26
#> CalvinKleinPerfume 44 5 30 81 10
#> Campbell’sSoup 31 12 19 11 80
#> ColgateToothpaste 56 23 37 9 52
#> DietCoke 48 10 43 6 17
#> GuessJeans 21 18 27 36 6
#> HallmarkCards 44 5 23 35 49
#> IBMComputers 65 31 55 38 26
#> Kmart 45 12 29 3 45
#> KodakFilm 50 12 33 17 29
#> LeeJeans 17 44 24 11 10
#> Lego 37 32 20 5 39
#> Levi’sJeans 54 71 46 30 26
#> Lexus 50 25 48 76 13
#> MattelToys 29 22 30 6 23
#> McDonald’s 59 14 39 4 16
#> Mercedes 79 43 55 94 27
#> MichelinTires 40 79 29 33 17
#> NikeAthleticShoes 50 58 54 40 16
#> OilofOlayLotion 28 4 19 39 43
#> PepsiCola 37 11 38 7 13
#> Porsche 83 36 54 89 12
#> ReebokAthleticShoes 50 54 51 30 17
#> RevlonCosmetics 42 6 32 38 25
#> SonyTelevisions 61 12 78 41 21
#> Toyota 56 59 48 15 36
#> Visa 69 28 52 40 18
|
1
2
3
4
5
|
# Membuang kolom yang tidak digunakan
brand_table <- brand_df %>%
select(-Brand)
brand_table
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#> charming cheerful daring down_to_earth honest imaginative
#> AmericanExpress 20 9 15 10 14 17
#> Applecomputers 25 27 23 14 27 54
#> Avoncosmetics 33 33 7 26 25 20
#> CalvinKleinPerfume 59 25 50 7 13 31
#> Campbell’sSoup 22 30 8 62 50 11
#> ColgateToothpaste 20 45 13 51 56 17
#> DietCoke 13 43 20 21 20 26
#> GuessJeans 20 18 36 8 6 14
#> HallmarkCards 58 57 6 28 51 54
#> IBMComputers 11 10 16 12 26 51
#> Kmart 12 48 12 68 45 17
#> KodakFilm 19 42 8 35 50 33
#> LeeJeans 12 22 24 40 14 12
#> Lego 9 51 9 45 49 58
#> Levi’sJeans 27 35 49 47 31 23
#> Lexus 40 10 32 7 23 29
#> MattelToys 15 62 7 24 28 62
#> McDonald’s 10 64 10 33 15 25
#> Mercedes 52 23 39 6 35 28
#> MichelinTires 7 12 23 31 38 14
#> NikeAthleticShoes 9 24 48 17 12 43
#> OilofOlayLotion 46 20 11 29 33 16
#> PepsiCola 11 53 29 24 18 33
#> Porsche 50 24 76 5 35 49
#> ReebokAthleticShoes 13 31 44 21 22 41
#> RevlonCosmetics 45 27 18 19 11 30
#> SonyTelevisions 22 24 27 18 35 59
#> Toyota 19 26 19 41 39 33
#> Visa 18 18 24 20 24 18
#> intelligent outdoorsy reliable spirited successful tough
#> AmericanExpress 44 14 26 14 63 20
#> Applecomputers 71 4 32 34 43 13
#> Avoncosmetics 10 6 23 7 23 6
#> CalvinKleinPerfume 16 11 21 38 44 5
#> Campbell’sSoup 11 16 53 14 31 12
#> ColgateToothpaste 32 12 82 19 56 23
#> DietCoke 9 35 31 29 48 10
#> GuessJeans 7 22 9 18 21 18
#> HallmarkCards 24 4 50 24 44 5
#> IBMComputers 75 2 56 18 65 31
#> Kmart 17 30 46 13 45 12
#> KodakFilm 38 54 67 16 50 12
#> LeeJeans 5 59 19 23 17 44
#> Lego 32 6 41 17 37 32
#> Levi’sJeans 16 72 52 47 54 71
#> Lexus 49 32 42 24 50 25
#> MattelToys 18 14 24 17 29 22
#> McDonald’s 15 18 30 16 59 14
#> Mercedes 61 36 66 35 79 43
#> MichelinTires 41 66 55 31 40 79
#> NikeAthleticShoes 21 80 38 54 50 58
#> OilofOlayLotion 21 11 37 14 28 4
#> PepsiCola 6 37 29 36 37 11
#> Porsche 64 48 52 64 83 36
#> ReebokAthleticShoes 27 87 41 55 50 54
#> RevlonCosmetics 13 9 31 14 42 6
#> SonyTelevisions 69 5 64 30 61 12
#> Toyota 41 64 66 36 56 59
#> Visa 44 22 61 26 69 28
#> up_to_date upper_class wholesome
#> AmericanExpress 30 69 8
#> Applecomputers 53 33 24
#> Avoncosmetics 20 6 26
#> CalvinKleinPerfume 30 81 10
#> Campbell’sSoup 19 11 80
#> ColgateToothpaste 37 9 52
#> DietCoke 43 6 17
#> GuessJeans 27 36 6
#> HallmarkCards 23 35 49
#> IBMComputers 55 38 26
#> Kmart 29 3 45
#> KodakFilm 33 17 29
#> LeeJeans 24 11 10
#> Lego 20 5 39
#> Levi’sJeans 46 30 26
#> Lexus 48 76 13
#> MattelToys 30 6 23
#> McDonald’s 39 4 16
#> Mercedes 55 94 27
#> MichelinTires 29 33 17
#> NikeAthleticShoes 54 40 16
#> OilofOlayLotion 19 39 43
#> PepsiCola 38 7 13
#> Porsche 54 89 12
#> ReebokAthleticShoes 51 30 17
#> RevlonCosmetics 32 38 25
#> SonyTelevisions 78 41 21
#> Toyota 48 15 36
#> Visa 52 40 18
|
1
2
|
#Alternative cara buat index baris utk contingency table (Pak Alif Aziz)
read.csv("data/brand.csv", row.names = 'Brand')
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
#> charming cheerful daring down_to_earth honest imaginative
#> AmericanExpress 20 9 15 10 14 17
#> Applecomputers 25 27 23 14 27 54
#> Avoncosmetics 33 33 7 26 25 20
#> CalvinKleinPerfume 59 25 50 7 13 31
#> Campbell’sSoup 22 30 8 62 50 11
#> ColgateToothpaste 20 45 13 51 56 17
#> DietCoke 13 43 20 21 20 26
#> GuessJeans 20 18 36 8 6 14
#> HallmarkCards 58 57 6 28 51 54
#> IBMComputers 11 10 16 12 26 51
#> Kmart 12 48 12 68 45 17
#> KodakFilm 19 42 8 35 50 33
#> LeeJeans 12 22 24 40 14 12
#> Lego 9 51 9 45 49 58
#> Levi’sJeans 27 35 49 47 31 23
#> Lexus 40 10 32 7 23 29
#> MattelToys 15 62 7 24 28 62
#> McDonald’s 10 64 10 33 15 25
#> Mercedes 52 23 39 6 35 28
#> MichelinTires 7 12 23 31 38 14
#> NikeAthleticShoes 9 24 48 17 12 43
#> OilofOlayLotion 46 20 11 29 33 16
#> PepsiCola 11 53 29 24 18 33
#> Porsche 50 24 76 5 35 49
#> ReebokAthleticShoes 13 31 44 21 22 41
#> RevlonCosmetics 45 27 18 19 11 30
#> SonyTelevisions 22 24 27 18 35 59
#> Toyota 19 26 19 41 39 33
#> Visa 18 18 24 20 24 18
#> intelligent outdoorsy reliable spirited successful tough
#> AmericanExpress 44 14 26 14 63 20
#> Applecomputers 71 4 32 34 43 13
#> Avoncosmetics 10 6 23 7 23 6
#> CalvinKleinPerfume 16 11 21 38 44 5
#> Campbell’sSoup 11 16 53 14 31 12
#> ColgateToothpaste 32 12 82 19 56 23
#> DietCoke 9 35 31 29 48 10
#> GuessJeans 7 22 9 18 21 18
#> HallmarkCards 24 4 50 24 44 5
#> IBMComputers 75 2 56 18 65 31
#> Kmart 17 30 46 13 45 12
#> KodakFilm 38 54 67 16 50 12
#> LeeJeans 5 59 19 23 17 44
#> Lego 32 6 41 17 37 32
#> Levi’sJeans 16 72 52 47 54 71
#> Lexus 49 32 42 24 50 25
#> MattelToys 18 14 24 17 29 22
#> McDonald’s 15 18 30 16 59 14
#> Mercedes 61 36 66 35 79 43
#> MichelinTires 41 66 55 31 40 79
#> NikeAthleticShoes 21 80 38 54 50 58
#> OilofOlayLotion 21 11 37 14 28 4
#> PepsiCola 6 37 29 36 37 11
#> Porsche 64 48 52 64 83 36
#> ReebokAthleticShoes 27 87 41 55 50 54
#> RevlonCosmetics 13 9 31 14 42 6
#> SonyTelevisions 69 5 64 30 61 12
#> Toyota 41 64 66 36 56 59
#> Visa 44 22 61 26 69 28
#> up_to_date upper_class wholesome
#> AmericanExpress 30 69 8
#> Applecomputers 53 33 24
#> Avoncosmetics 20 6 26
#> CalvinKleinPerfume 30 81 10
#> Campbell’sSoup 19 11 80
#> ColgateToothpaste 37 9 52
#> DietCoke 43 6 17
#> GuessJeans 27 36 6
#> HallmarkCards 23 35 49
#> IBMComputers 55 38 26
#> Kmart 29 3 45
#> KodakFilm 33 17 29
#> LeeJeans 24 11 10
#> Lego 20 5 39
#> Levi’sJeans 46 30 26
#> Lexus 48 76 13
#> MattelToys 30 6 23
#> McDonald’s 39 4 16
#> Mercedes 55 94 27
#> MichelinTires 29 33 17
#> NikeAthleticShoes 54 40 16
#> OilofOlayLotion 19 39 43
#> PepsiCola 38 7 13
#> Porsche 54 89 12
#> ReebokAthleticShoes 51 30 17
#> RevlonCosmetics 32 38 25
#> SonyTelevisions 78 41 21
#> Toyota 48 15 36
#> Visa 52 40 18
|
Data Visualization
EDA for Contingency Table
Sebelum melakukan analisis, kita harus mengenali data yang akan kita gunakan yaitu brand_table yang merupakan contingency table dengan baris adalah nama brand dan kolom adalah atribut-atribut personality. Kita dapat dengan cepat memperoleh rangkuman dari data kita yang berisi five number summary menggunakan fungsi summary() di R.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#> charming cheerful daring down_to_earth
#> Min. : 7.00 Min. : 9.00 Min. : 6.00 Min. : 5.00
#> 1st Qu.:12.00 1st Qu.:22.00 1st Qu.:11.00 1st Qu.:14.00
#> Median :20.00 Median :27.00 Median :20.00 Median :24.00
#> Mean :24.72 Mean :31.48 Mean :24.24 Mean :26.52
#> 3rd Qu.:33.00 3rd Qu.:43.00 3rd Qu.:32.00 3rd Qu.:35.00
#> Max. :59.00 Max. :64.00 Max. :76.00 Max. :68.00
#> honest imaginative intelligent outdoorsy reliable
#> Min. : 6.00 Min. :11.00 Min. : 5.00 Min. : 2.00 Min. : 9.0
#> 1st Qu.:18.00 1st Qu.:17.00 1st Qu.:15.00 1st Qu.:11.00 1st Qu.:30.0
#> Median :27.00 Median :29.00 Median :24.00 Median :22.00 Median :41.0
#> Mean :29.14 Mean :31.66 Mean :30.93 Mean :30.21 Mean :42.9
#> 3rd Qu.:38.00 3rd Qu.:43.00 3rd Qu.:44.00 3rd Qu.:48.00 3rd Qu.:55.0
#> Max. :56.00 Max. :62.00 Max. :75.00 Max. :87.00 Max. :82.0
#> spirited successful tough up_to_date upper_class
#> Min. : 7 Min. :17.00 Min. : 4.00 Min. :19.00 Min. : 3.00
#> 1st Qu.:16 1st Qu.:37.00 1st Qu.:12.00 1st Qu.:29.00 1st Qu.: 9.00
#> Median :24 Median :48.00 Median :20.00 Median :37.00 Median :33.00
#> Mean :27 Mean :47.38 Mean :26.38 Mean :38.48 Mean :32.48
#> 3rd Qu.:35 3rd Qu.:56.00 3rd Qu.:36.00 3rd Qu.:51.00 3rd Qu.:40.00
#> Max. :64 Max. :83.00 Max. :79.00 Max. :78.00 Max. :94.00
#> wholesome
#> Min. : 6.00
#> 1st Qu.:16.00
#> Median :23.00
#> Mean :25.66
#> 3rd Qu.:29.00
#> Max. :80.00
|
Nama brand sudah kita jadikan index row sehingga summary hanya ditampilkan untuk setiap kolom yang ada pada data yang merupakan atribut personality. Dikarenakan tujuan analisis kali ini adalah ingin mengidentifikasi atribut personality yang melekat pada tiap brand, maka nilai statistik yang menarik untuk diperhatikan adalah nilai maksimum.
Insight:
- terdapat brand yang dikenal “charming” dengan perolehan suara maksimum sebanyak 59
- terdapat brand yang dikenal “cheerful” dengan perolehan suara maksimum sebanyak 64
- terdapat brand yang dikenal “upper_class” dengan perolehan suara maksimum sebanyak 94
- terdapat brand yang dikenal “wholesome” dengan perolehan suara maksimum sebanyak 80
Dari summary, kita bisa mendapatkan bahwa terdapat beberapa atribut personality yang nilai maksimumnya sangat tinggi dibanding atribut lainnya. Sepertinya, semakin tinggi nilai maksimum untuk suatu atribut personality pada suatu brand maka semakin yakin suara dari para responden. Karena nilai yang maksimum dihasilkan dari suara banyak responden yang memberikan skor tinggi..
Meskipun fungsi summary memberikan rangkuman data, kita tetap kesulitan untuk menginterpretasikan data. Sehingga kita perlu suatu visualisasi untuk membantu kita menjelaskan data. Dikarenakan data input kita spesial yaitu merupakan tabel kontingensi, maka akan dikenalkan visualisasi khusus untuk tabel kontingensi.
Balloon plot
Balloon plot adalah salah satu jenis plot untuk memvisualisasikan data kategorik yang berukuran besar.
Fungsi balloon plot adalah membuat tabel grafis dimana setiap sel menampilkan lingkaran berwarna yang ukurannya mencerminkan besar nilainya.
Secara visual, plot ini dapat menghighlight poin data yang nilainya menonjol ditunjukkan semakin besarnya lingkaran. Prinsip dasar pada ballon plot, semakin besar ukuran lingkaran maka semakin besar pula nilai datanya.
1
2
3
|
ggballoonplot(brand_table) +
labs(title = "Balloonplot for Brand Personalites") +
theme(plot.title = element_text(hjust = 0.5))
|
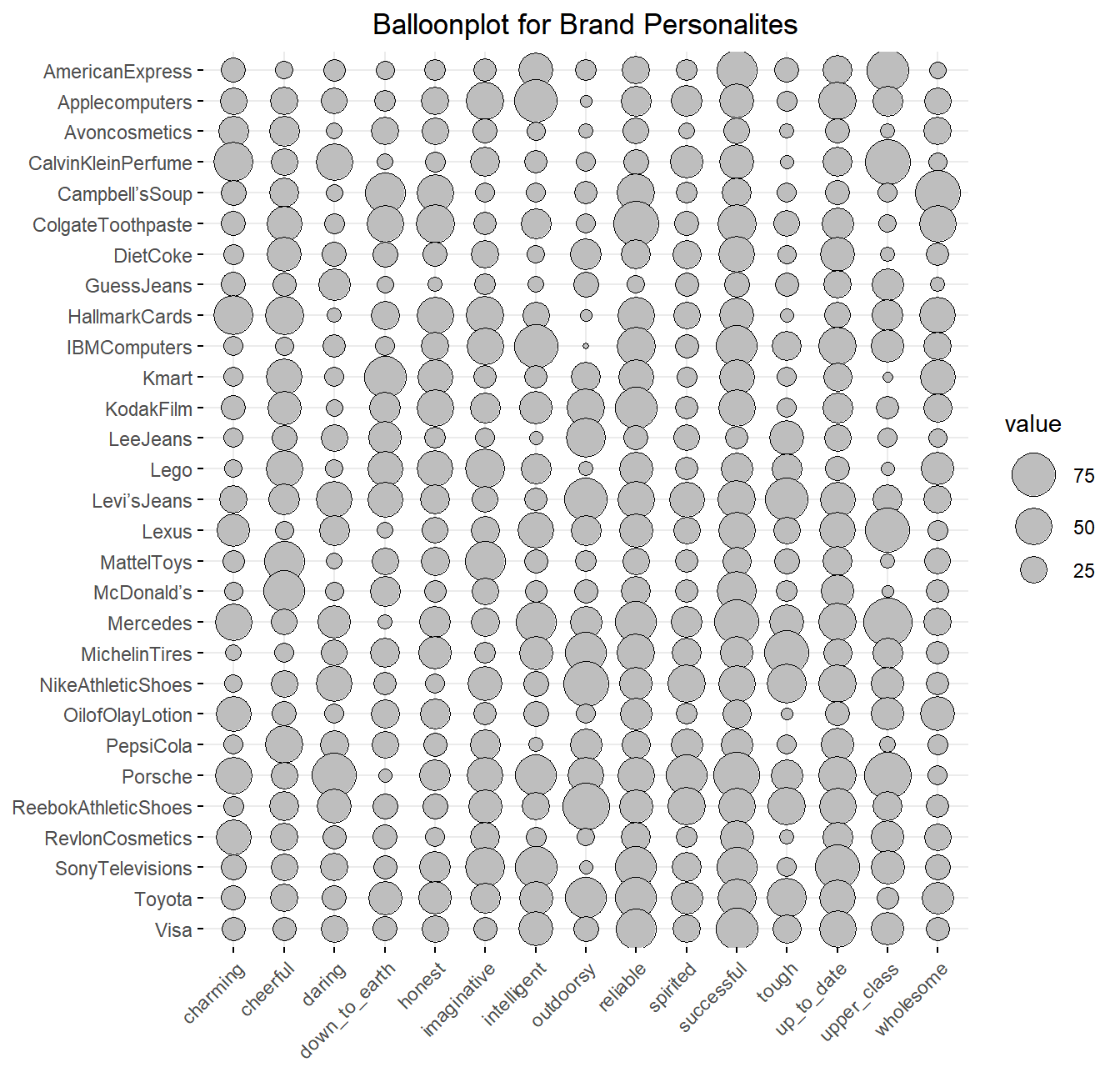
Untuk memudahkan kita dalam membaca ballon plot, kita dapat memberikan warna untuk perbedaan ukuran lingkaran pada ballon plot seperti sebagai berikut.
1
2
3
4
5
|
my_cols <- c("#0D0887FF", "#6A00A8FF", "#B12A90FF","#E16462FF", "#FCA636FF", "#F0F921FF")
ggballoonplot(brand_table, fill = "value") +
scale_fill_gradientn(colours = my_cols) +
labs(title = "Balloonplot for Brand Personalites") +
theme(plot.title = element_text(hjust = 0.5))
|
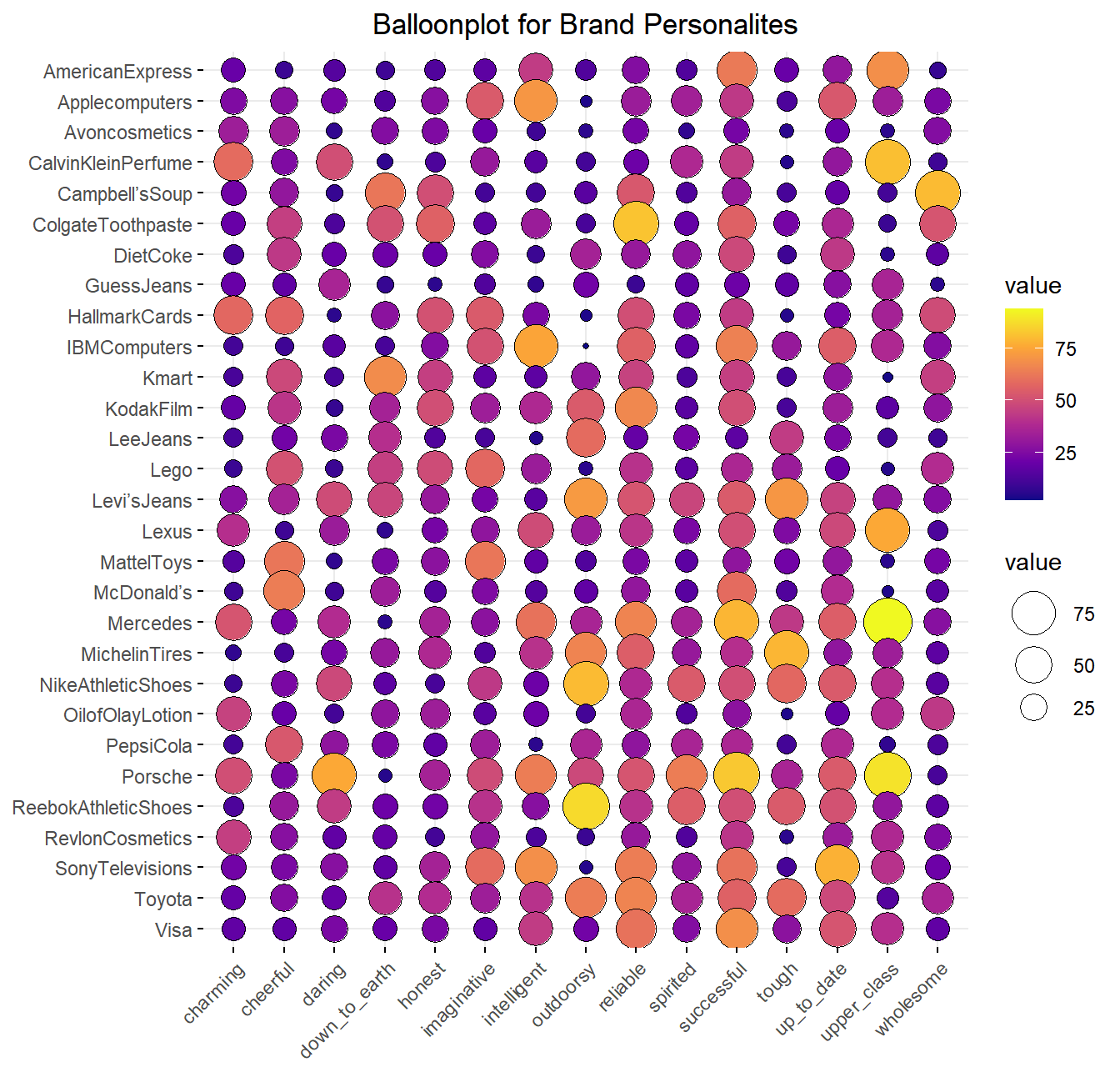
Plot di atas sudah dimodifikasi agar warna lingkaran juga dapat menunjukkan besarnya nilai, yaitu warna kuning menunjukkan nilai yang semakin besar sementara warna navy menunjukkan nilai semakin kecil. Pada ballon plot di atas, dapat diketahui bahwa terdapat beberapa brand dengan nilai frekuensi atribut yang tinggi dibanding brand lainnya.
Dari balloon plot di atas, kita dapat melihat bahwa:
- Jika menyebut brand yang outdoorsy atau brand yang biasa digunakan untuk kegiatan di luar ruangan, berdasarkan plot maka brand yang langsung dipikirkan adalah Nike dan Reebok.
- Brand yang memiliki atribut personality upper class adalah Porsche, Mercedes, dan Calvin Klein
- Porsche sangat tidak down to earth, artinya harganya tidak murah
- Avoncosmetics perlu rebranding produknya, brandnya tidak punya kecenderungan tertentu di salah satu personalities kak
Dengan menggunakan balloon plot kita dapat dengan cepat menginterpretasikan data kategorik meskipun kita memiliki data yang berukuran besar.
Balloonplot interactive:
1
2
3
4
5
6
7
8
|
library(plotly)
plot1 <- ggballoonplot(brand_table, fill = "value") +
scale_fill_gradientn(colours = my_cols) +
labs(title = "Balloonplot for Brand Personalites") +
theme(plot.title = element_text(hjust = 0.5))
# Catatan: perlu disesuaikan tinggi & lebar plot
# ggplotly(plot1, height = 800, width = 800)
|
Mosaic Plot
Mosaic plot digunakan untuk memvisualisasikan tabel kontingensi dan untuk memeriksa hubungan antara variabel kategori. Untuk setiap sel, tinggi batang sebanding dengan frekuensi relatif yang diamati yang dikandungnya:
$$ \frac{cell.value}{column.sum}$$
Warna pada plot menunjukkan standardized residuals, yang memberikan intuisi signifikansi hubungan. Standardized residuals adalah akar dari statistik Chi-square yang akan dibahas pada section selanjutnya.
Mosaic plot dapat diinterpresaikan sebagai berikut:
- Sebuah sel diarsir biru jika kita yakin bahwa sel tersebut lebih tinggi dari sel lain dalam baris yang sama
- Sebuah sel diarsir dengan warna merah jika kita yakin bahwa sel tersebut lebih rendah dari sel lain pada baris yang sama
Formula: mosaicplot() dengan parameter:
datalas: style of axis label (1/2)shade = T -> colour gradientoff: spacing of cellmain: title of plot
1
2
3
4
5
6
|
# Mosaic plot of observed values
mosaicplot(brand_table,
las = 2,
shade = T,
off = 25,
main = "Mosaic plot for brand personalities")
|
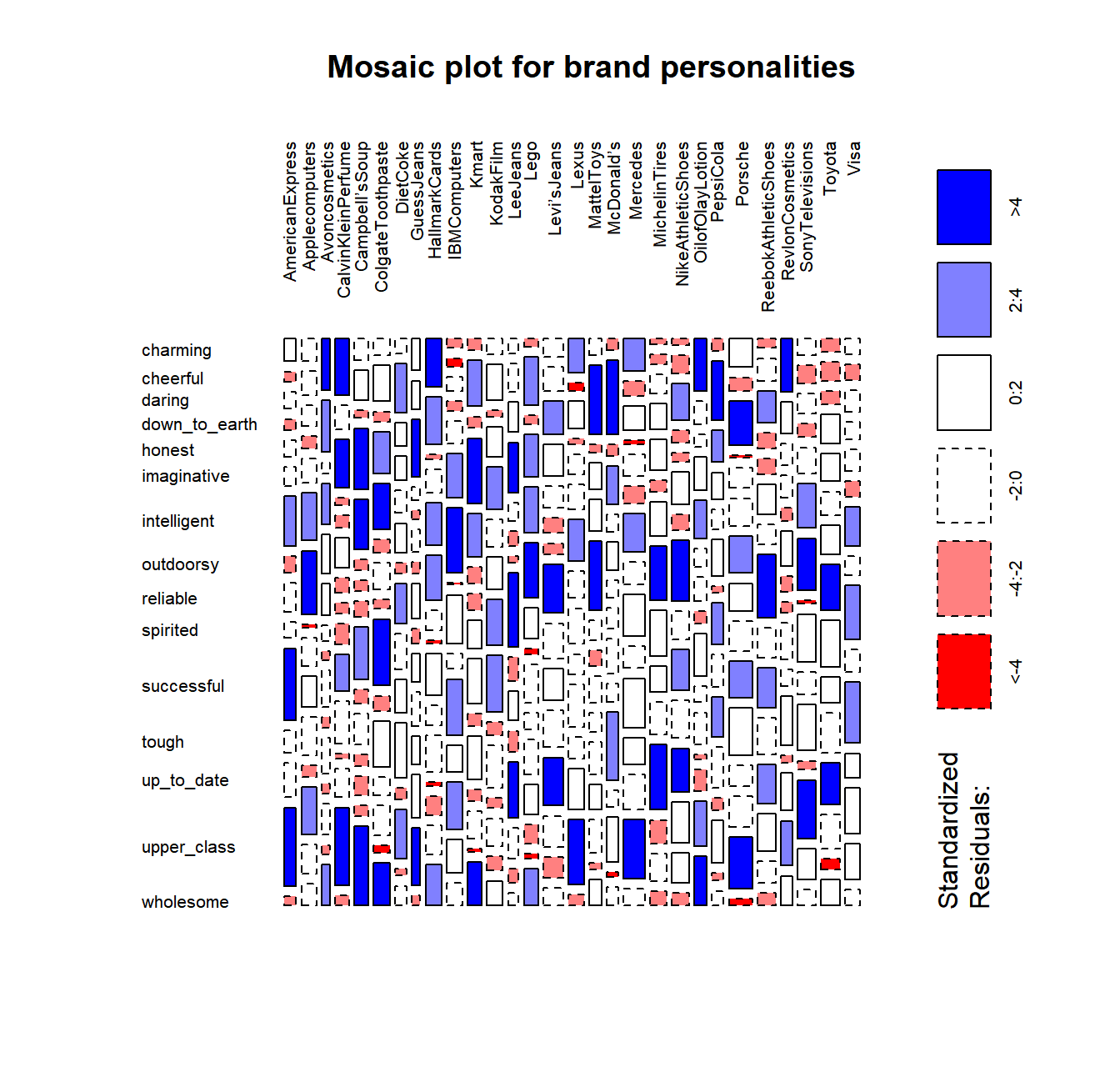
Dari mosaic plot di atas, kita dapat melihat bahwa:
- Brand avoncosmetics, CalvinKleinPerfume, Hallmarks Cards, OlofOlayLotion, dan RevlonCosmetics memiliki persona charming dibanding brand lain
- Brand MattelToys, McDonald’s, dan PepsiCola memiliki persona cheerful dibanding brand lain
- Brand LeeJeans, Levi’sJeans, Michelin Tires, Nike dan Reebok memiliki persona outdoorsy dibanding brand lain
- Brand American Express, CalvinKleinPerfume, Guess Jeans, Lexus, Mercedes, dan Porsche memiliki persona upper_class dibanding brand lain
- Campbel’s Soup, Colgate Toothpaste, Kmart, dan OlofOlayLotion memiliki persona wholesome dibanding brand lainn
Chi-Square Test
Uji chi-square adalah sebuah tes statistik yang membantu kita menentukan apakah ada hubungan yang signifikan antara dua variabel kategorik.
Uji ini sering digunakan dalam social science research, studi medis, dan bidang lain di mana kita ingin memeriksa hubungan antara variabel.
Sebagai contoh, misalnya kita ingin mengetahui apakah terdapat hubungan yang signifikan antara usia seseorang dengan tingkat merokok. Kita bisa mengumpulkan data dari sekelompok orang dan menggunakan uji chi-square untuk melihat apakah ada perbedaan yang signifikan kelompok usia tertentu dengan tingkat merokoknya.
Uji hipotesis untuk Chi-Square Test adalah sebagai berikut.
\(H_0\) : Variabel baris dan kolom dari tabel kontingensi adalah independen\(H_1\) : Variabel baris dan kolom adalah dependen (memiliki hubungan yang signifikan)

Untuk sel tertentu pada contingency table, nilai yang diharapkan dihitung sebagai berikut:
$$E_{ij}=\frac{row_i.marginal * column_j.marginal}{grand.total}$$
Statistik Chi square dihitung sebagai berikut:
$$χ^2= \sum\frac{(O_{ij} - E_{ij})^2}{E_{ij}}$$
keterangan:
- χ2 = Statistik Chi-square
- Oi = Nilai observasi (pengamatan) ke-i
- Ei = Nilai ekspektasi ke-i
Catatan:
- Statistik Chi-square yang dihitung ini dibandingkan dengan nilai kritis (diperoleh dari tabel statistik) dengan derajat kebebasan df = ( r − 1 ) ( c − 1 ) dan alpha = 0,05. r adalah jumlah baris dan c adalah jumlah kolom pada tabel kontingensi.
- Jika statistik Chi-kuadrat yang dihitung lebih besar dari nilai kritis atau p-value < 0.05, maka kita dapat menyimpulkan bahwa variabel baris dan kolom tidak independen satu sama lain. Sehingga mereka dikatakan terkait atau memiliki hubungan secara signifikan.
- Di R, kita bisa melakukan chi-square test dengan menggunakan fungsi
chisq.test().
Question
Uji hipotesis Chi-Square Test untuk menguji apakah ada perbedaan yang signifikan kelompok usia tertentu dengan tingkat merokoknya.
\(H_0\) : Tidak ada hubungan antara kelompok usia dan tingkat merokoknya (independen)\(H_1\) : Ada hubungan antara kelompok usia dan tingkat merokoknya
1
2
3
|
#chi_squared test in R
#chisq.test(kolom_kategorikal, kolom_kategorikal)
chisq.test(esoph$agegp, esoph$tobgp)
|
1
2
3
4
5
|
#>
#> Pearson's Chi-squared test
#>
#> data: esoph$agegp and esoph$tobgp
#> X-squared = 2.4, df = 15, p-value = 0.9999
|
Catatan: Tolak H0 jika pvalue < 0.05
Kesimpulan: p-value = 0.9999 > 0.05, gagak tolak H0 maka tidak ada hubungan antara kelompok usia dan tingkat merokoknya
Question: Bagaimana melakukan chi-square test pada tabel kontingensi brand_table
1
|
chisq.test(brand_table)
|
1
2
3
4
5
|
#>
#> Pearson's Chi-squared test
#>
#> data: brand_table
#> X-squared = 3841.8, df = 392, p-value < 0.00000000000000022
|
Correspondence Analysis Concept
Correspondence Analysis (CA) adalah jenis teknik dimentionality reduction yang dapat digunakan untuk memvisualisasikan dan mengeksplorasi hubungan variabel kategorikal dalam sebuah dataset.
Analisis korespondensi (CA) diperlukan untuk tabel kontingensi besar untuk memvisualisasikan titik baris dan titik kolom secara grafis dalam ruang berdimensi dua dimensi.
Plot hasilnya menampilkan:
- hubungan antara kategori baris dan kolom
- setiap titik mewakili kategori
- jarak antara titik mencerminkan kekuatan hubungan antara kategori tersebut
Misal kita ingin menganalisis apakah terdapat hubungan antara tipe pekerjaan rumah dengan role keluarga. CA akan menghasilkan plot berikut untuk menunjukkan hubungan dari kedua variabel tersebut.
 Glossary:
Glossary:
- Standardized residual: ukuran signifikansi hubungan yang berasal dari statistik chi-square
- Row marginal/ margin baris: jumlah frekuensi per baris
- Column marginal/margin kolom: jumlah frekuensi per kolom
- Singular Value Decomposition (SVD): prosedur dekomposisi matriks untuk mendapatkan eigen value dan eigen vector
- Singular value: nilai diagonal dari matriks diagonal yang dihasilkan SVD
- Eigen value (sv^2): variansi yang dipertahankan oleh setiap dimensi
- Eigen vector baris (U): komponen koordinat baris pada CA
- Eigen vector kolom (v): komponen koordinat kolom pada CA
- matriks ortogonal: matriks yang memiliki invers yang sama dengan transposenya
- matriks diagonal: matriks yang nilainya hanya terdapat pada diagonalnya, sementara elemen lainnya bernilai nol.
Implementasi Correspondence Analysis for Brand Personalities
Pada bagian sebelumnya kita sudah melakukan eksplorasi data pada data brand. Sekarang kita akan menerapkan CA untuk menganalisis hubungan variabel brand dan personality pada data brand CA pada data brand akan membantu kita memperoleh plot visualisasi untuk mengidentifikasi personality pada setiap brand.
Untuk melakukan CA, dapat digunakan fungsi CA() dari package factomineR
CA(X, ncp = 5, graph = TRUE)
Keterangan:
X: data (tabel kontingensi)ncp: jumlah dimensi yang disimpan di hasil akhir.graph: nilai boolean. Jika TRUE grafik ditampilkan.
1
2
|
brand.ca <- CA(brand_table, graph = FALSE)
brand.ca
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#> **Results of the Correspondence Analysis (CA)**
#> The row variable has 29 categories; the column variable has 15 categories
#> The chi square of independence between the two variables is equal to 3841.76 (p-value = 0 ).
#> *The results are available in the following objects:
#>
#> name description
#> 1 "$eig" "eigenvalues"
#> 2 "$col" "results for the columns"
#> 3 "$col$coord" "coord. for the columns"
#> 4 "$col$cos2" "cos2 for the columns"
#> 5 "$col$contrib" "contributions of the columns"
#> 6 "$row" "results for the rows"
#> 7 "$row$coord" "coord. for the rows"
#> 8 "$row$cos2" "cos2 for the rows"
#> 9 "$row$contrib" "contributions of the rows"
#> 10 "$call" "summary called parameters"
#> 11 "$call$marge.col" "weights of the columns"
#> 12 "$call$marge.row" "weights of the rows"
|
Dalam menginterpretasikan hasil dari analisis korespondensi, terdapat beberapa output yang dihasilkan yaitu statistik Chi-square, nilai Eigen, komponen baris dan komponen kolom. Selanjutnya, akan dibahas satu per satu terkait output ini.
Chi-Square Test
Untuk menginterpretasikan CA, perlu dilakukan uji chi square untuk memeriksa hubungan antara variabel brand dan variabel atribut personality.
Dengan rumusan hipotesis sebagai berikut.
\(H_0\) : Tidak ada hubungan antara brand dan personality (independen)\(H_1\) : Ada hubungan antara brand dan personality
Catatan: H0 ditolak jika pvalue < 0.05
Kesimpulan: p-value = 0 maka H0 ditolak, artinya ada hubungan antara brand dan personality
Nilai Eigen/ Variance
Sama seperti di PCA, eigen atau variance juga menunjukkan banyak informasi yang dipertahankan oleh setiap dimensi. Dimensi 1 menjelaskan variansi terbanyak, diikuti oleh dimensi 2 dan seterusnya. Pada summary brand.ca kita dapat memanggil nilai eigen dengan $eig.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#> eigenvalue percentage of variance cumulative percentage of variance
#> dim 1 0.1016068450 35.98514267 35.98514
#> dim 2 0.0762365463 26.99998211 62.98512
#> dim 3 0.0356997982 12.64346247 75.62859
#> dim 4 0.0309644217 10.96637863 86.59497
#> dim 5 0.0114072819 4.04000996 90.63498
#> dim 6 0.0072451320 2.56594041 93.20092
#> dim 7 0.0060861501 2.15547467 95.35639
#> dim 8 0.0036043001 1.27650116 96.63289
#> dim 9 0.0034801183 1.23252085 97.86541
#> dim 10 0.0027901258 0.98815267 98.85357
#> dim 11 0.0014229304 0.50394591 99.35751
#> dim 12 0.0009812083 0.34750532 99.70502
#> dim 13 0.0005686232 0.20138394 99.90640
#> dim 14 0.0002642847 0.09359923 100.00000
|
Note: pada data brand, menggunakan 2 dimensi CA berhasil merangkum data kita sebesar 62.98512%
Rows Components
Komponen fungsi brand-ca$row berisi:
$coord: koordinat setiap titik baris pada setiap dimensi (1,2,dst). Digunakan untuk membuat plot.$cos2: kualitas representasi baris.$contrib: kontribusi baris (dalam %) terhadap definisi dimensi.
Rows Coordinat
CA menghasilkan koordinat baru untuk variabel baris pada dimensi baru, yang dapat dipanggil dengan $coord.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
#> Dim 1 Dim 2 Dim 3 Dim 4
#> AmericanExpress -0.43009425 -0.26274259 -0.14006556 0.135092794
#> Applecomputers -0.10963034 -0.29594656 -0.21293975 -0.204124786
#> Avoncosmetics 0.42438497 -0.24395914 0.23683297 0.004318099
#> CalvinKleinPerfume -0.48332589 -0.33917232 0.45242792 0.010585488
#> Campbell’sSoup 0.67062192 -0.09390081 0.08016308 0.390171002
#> ColgateToothpaste 0.43267403 -0.08456799 -0.11733869 0.145138207
#> DietCoke 0.13845095 0.15600975 0.11953343 -0.249355669
#> GuessJeans -0.41720526 0.09320176 0.33934509 -0.033210574
#> HallmarkCards 0.28831092 -0.39169337 0.18727979 -0.022121380
#> IBMComputers -0.13369114 -0.25361416 -0.44885590 -0.068520237
#> Kmart 0.57560715 0.08070950 0.03867825 0.101839612
#> KodakFilm 0.24587565 0.04802314 -0.09816621 0.023963298
#> LeeJeans 0.03300983 0.65347110 0.15642295 0.105167710
#> Lego 0.45979331 -0.05957126 -0.14167135 -0.140679892
#> Levi’sJeans -0.04609905 0.38717552 0.09220936 0.091533031
#> Lexus -0.40986057 -0.17017633 -0.01589640 0.112549791
#> MattelToys 0.34747860 -0.04306142 0.03569126 -0.423766292
#> McDonald’s 0.32884129 0.04576167 0.05670141 -0.329354152
#> Mercedes -0.32962291 -0.15638998 -0.02759191 0.145498412
#> MichelinTires -0.11120486 0.43676393 -0.22899279 0.236361250
#> NikeAthleticShoes -0.28028576 0.42626900 0.03149350 -0.085704410
#> OilofOlayLotion 0.16419368 -0.35488553 0.20532061 0.312919722
#> PepsiCola 0.12450525 0.21986183 0.21396336 -0.341123738
#> Porsche -0.42659856 -0.06127262 0.05948155 -0.020034025
#> ReebokAthleticShoes -0.18702663 0.42251965 0.02456882 -0.082647000
#> RevlonCosmetics -0.03759488 -0.32382707 0.26871649 0.008619822
#> SonyTelevisions -0.10220444 -0.27676463 -0.25675379 -0.168268932
#> Toyota 0.08827826 0.26648649 -0.15448323 0.088026201
#> Visa -0.13992008 -0.05706729 -0.18574731 0.058274423
#> Dim 5
#> AmericanExpress -0.1143892938
#> Applecomputers 0.0945932165
#> Avoncosmetics 0.0520569517
#> CalvinKleinPerfume 0.0197906060
#> Campbell’sSoup -0.0006043648
#> ColgateToothpaste -0.1105428705
#> DietCoke -0.1900414684
#> GuessJeans -0.0060201842
#> HallmarkCards 0.1568561664
#> IBMComputers 0.0304423575
#> Kmart -0.1438087567
#> KodakFilm -0.0744302335
#> LeeJeans 0.0664311687
#> Lego 0.2254639656
#> Levi’sJeans 0.0214432137
#> Lexus 0.0027901335
#> MattelToys 0.2228290816
#> McDonald’s -0.2519975124
#> Mercedes -0.0170428985
#> MichelinTires 0.1174489130
#> NikeAthleticShoes 0.0432409217
#> OilofOlayLotion 0.0581036972
#> PepsiCola -0.1140364893
#> Porsche 0.0096438616
#> ReebokAthleticShoes 0.0365513704
#> RevlonCosmetics -0.0221898703
#> SonyTelevisions -0.0495074649
#> Toyota 0.0378954455
#> Visa -0.1796737922
|
Gunakan fungsi fviz_ca_row() [in factoextra] untuk memvisualisasikan hanya titik baris:
1
|
fviz_ca_row(brand.ca, repel = TRUE)
|
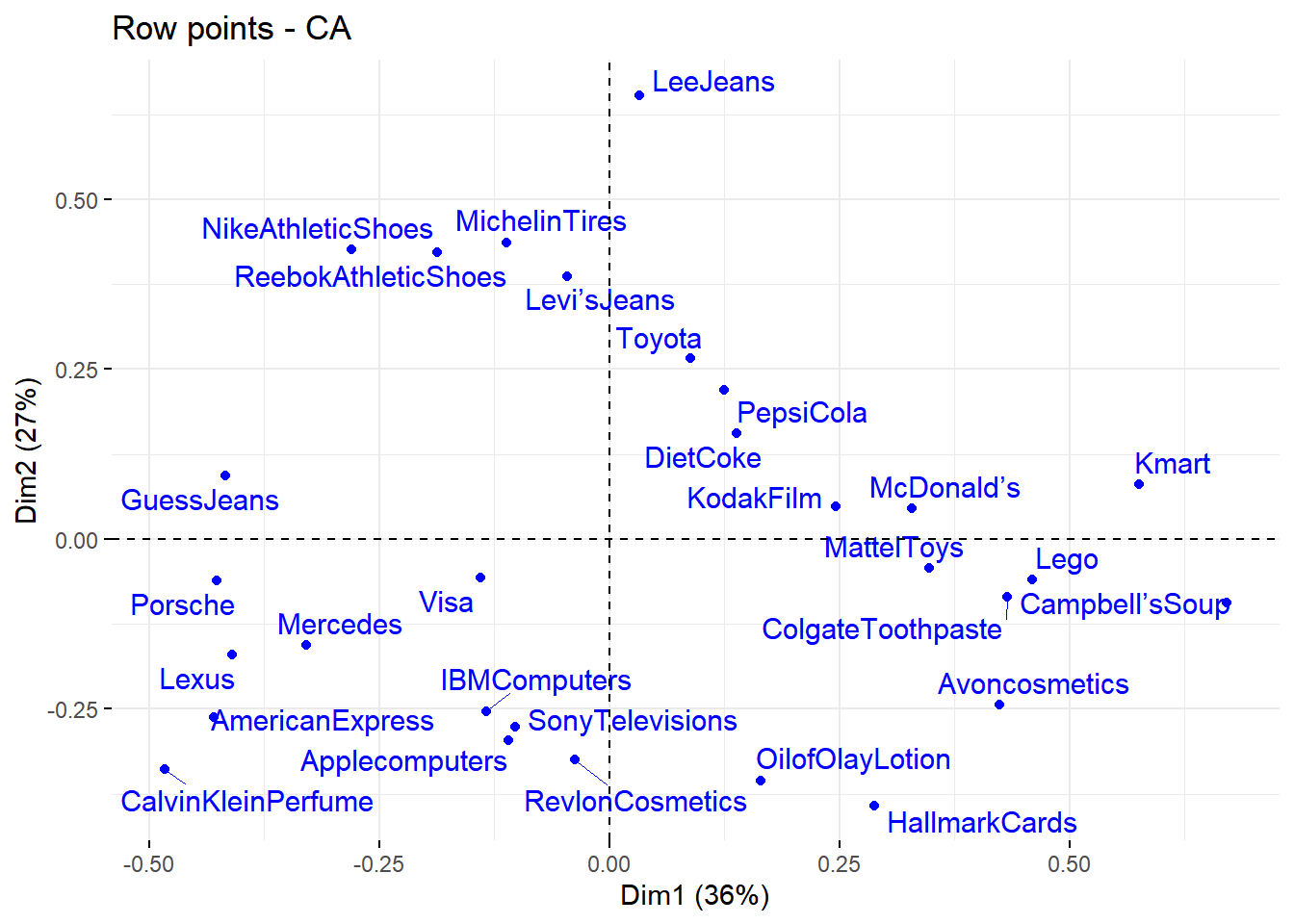
Kita dapat mengidentifikasi kesamaan atau ketidaksamaan dalam kategori baris dengan memperhatikan jarak antar titik koordinat baris.
- Baris dengan profil serupa akan memiliki titik koordinat yang berdekatan (karakteristik mirip)
- Kategori baris yang memilki hubungan negatif atau bertolak belakang akan memiliki titik koordinat yang berada pada kuadran yang berlawanan (karakteristik tidak mirip)
Sehingga, berdasarkan plot titik koordinat baris insight yang didapatkan adalah:
- Nike, Reebok, Levi’s Jeans, dan Michelin Tires berada berdekatan dan dalam satu kuadran yang sama. Nampaknya keempat brand ini memiliki kemiripan personality outdoorsy jika ditelusuri lewat ballon plot.
- IBM, Apple, Sony memiliki personality yang mirip
- Toyota dan Mercedes Benz tidak mirip padahal sama-sama produsen mobil (mungkin branding personality yang dibangun sangat berbeda)
Quality of representation of rows
CA dapat merangkum data dan memvisualisasikannya dalam plot dua dimensi. Perhatikan bahwa dua dimensi baru (dimensi 1 & 2) dapat mempertahankan 62.89% dari variasi yang terkandung dalam data. Namun, tidak semua titik data ditampilkan dengan sama baiknya dalam dua dimensi. Kualitas representasi baris pada peta faktor disebut cosinus kuadrat (cos2).
$$cos2 = \frac{row.coord^2}{d^2}$$
dengan row.coord adalah koordinat baris pada sumbu \(d^2\) adalah jarak kuadrat dari rata-rata profil baris.
1
|
head(brand.ca$row$cos2)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#> Dim 1 Dim 2 Dim 3 Dim 4
#> AmericanExpress 0.47865009 0.17862894 0.050763739 0.0472231809
#> Applecomputers 0.05094028 0.37121579 0.192182277 0.1766002553
#> Avoncosmetics 0.53539088 0.17692336 0.166738278 0.0000554289
#> CalvinKleinPerfume 0.41313819 0.20344923 0.362004553 0.0001981696
#> Campbell’sSoup 0.66951479 0.01312633 0.009566509 0.2266285701
#> ColgateToothpaste 0.70784155 0.02704123 0.052059124 0.0796485554
#> Dim 5
#> AmericanExpress 0.0338580256331
#> Applecomputers 0.0379244968931
#> Avoncosmetics 0.0080557958669
#> CalvinKleinPerfume 0.0006926812326
#> Campbell’sSoup 0.0000005437547
#> ColgateToothpaste 0.0462036061552
|
Catatan:
- Nilai cos2 adalah 0 sampai 1
- Jika kategori baris terwakili dengan baik oleh dua dimensi, jumlah dari cos2 mendekati 1
Berikut divisualisasikan nilai cos2 untuk masing-masing brand. Semakin oranye warna suatu brand, semakin bagus kualitas representasi suatu brand tersebut pada plot CA.
1
2
3
4
5
|
# Color by cos2 values: quality on the factor map
fviz_ca_row(brand.ca, col.row = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE,
title="Row Poins based on Their Quality Cos2")
|
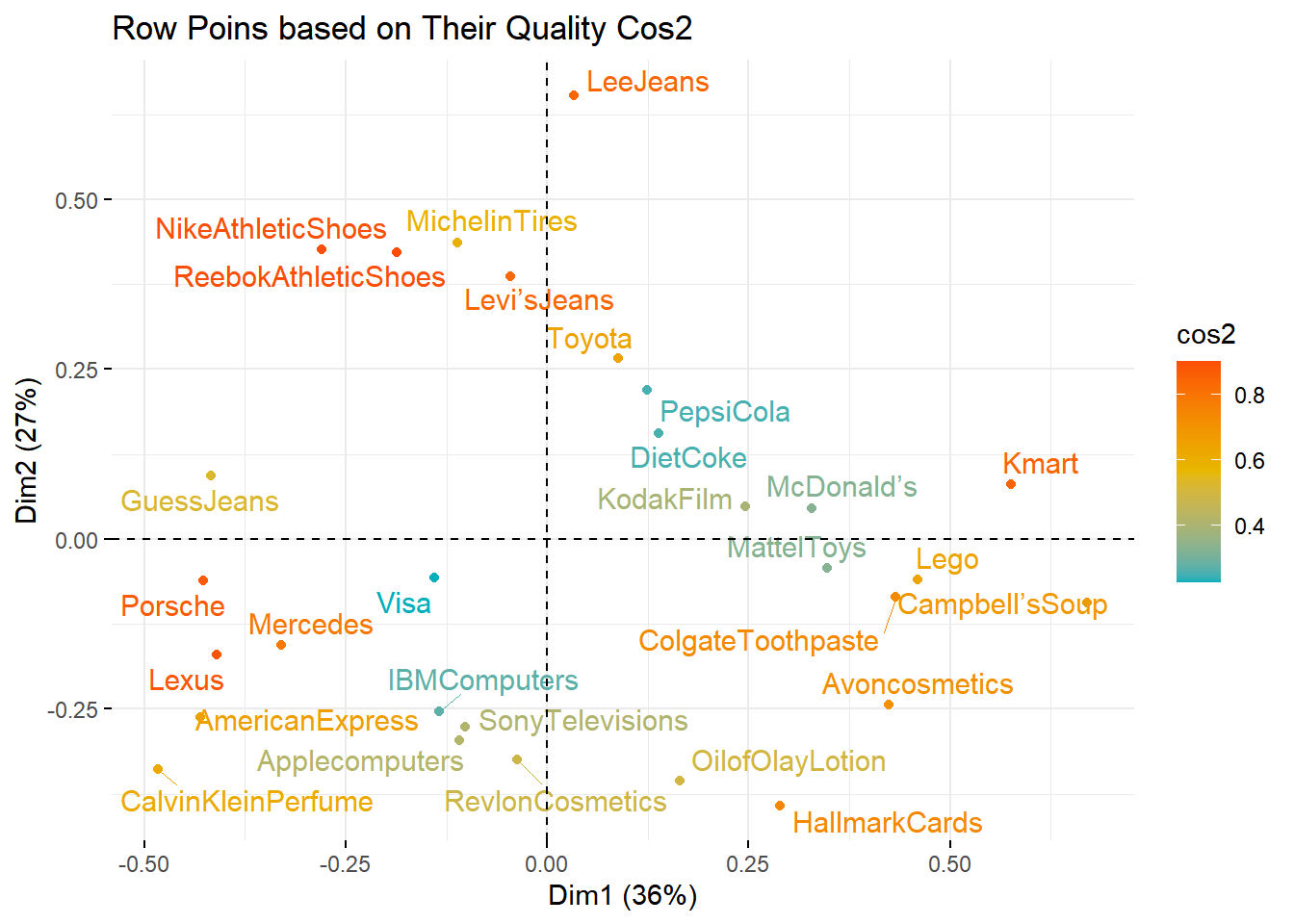
Note: semakin dekat suatu titik koordinat dengan pusat kuadran, biasanya semakin sedikit informasi yang diperoleh. Sehingga umumnya titik koordinat yang jauh dari kuadran yang memiliki banyak insight
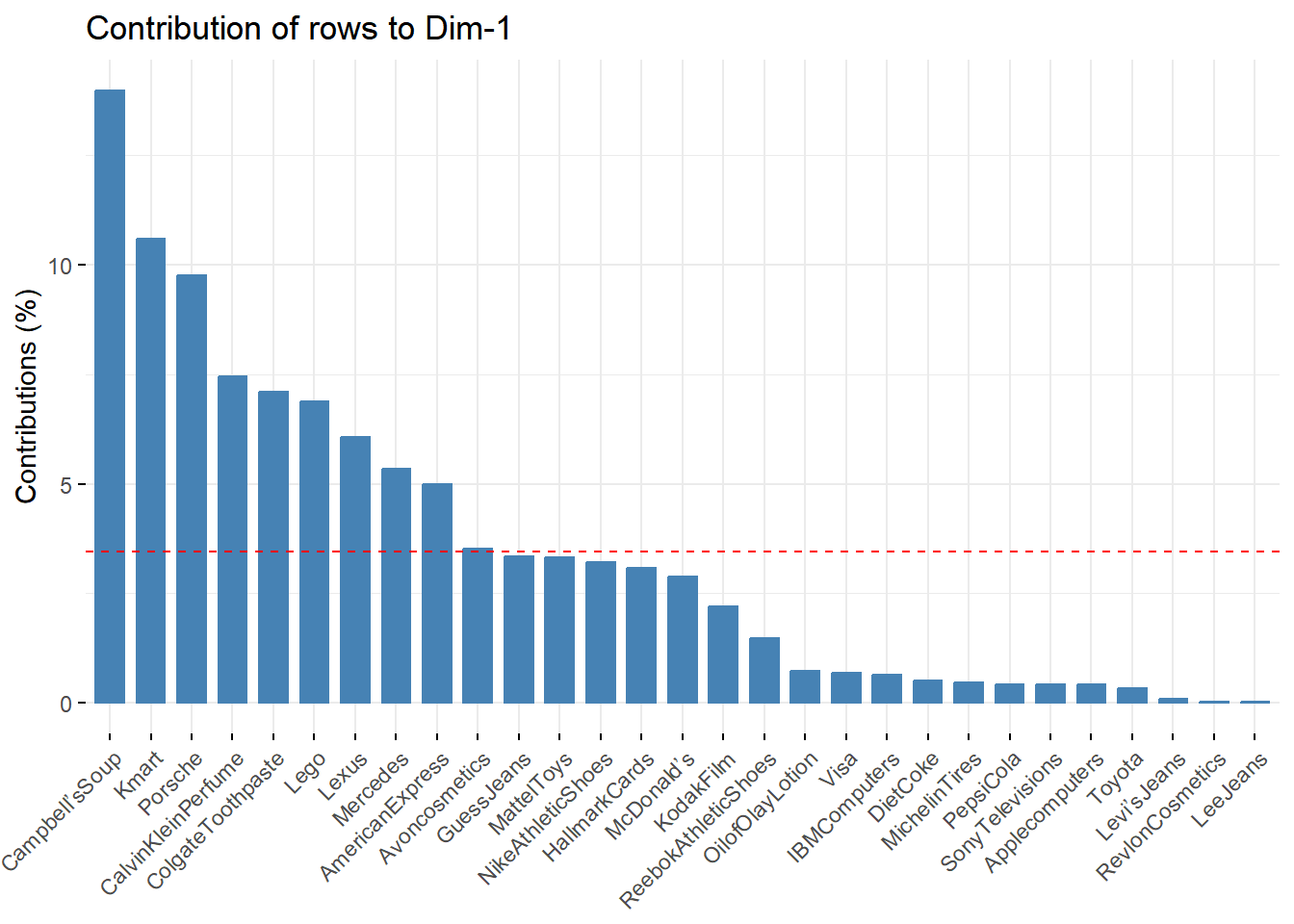
Contributions of rows to the dimensions
Variabel baris dengan nilai yang lebih besar, berkontribusi paling besar terhadap definisi dimensi. Baris yang paling berkontribusi pada Dim.1 dan Dim.2 adalah yang paling penting dalam menjelaskan variabilitas dalam kumpulan data.
1
|
head(brand.ca$row$contrib)
|
1
2
3
4
5
6
7
|
#> Dim 1 Dim 2 Dim 3 Dim 4 Dim 5
#> AmericanExpress 4.9909437 2.4824248 1.5065215 1.615770807 3.1446111483
#> Applecomputers 0.4146927 4.0276460 4.4528252 4.717549052 2.7499558788
#> Avoncosmetics 3.5304969 1.5549262 3.1293734 0.001199392 0.4731666399
#> CalvinKleinPerfume 7.4518700 4.8908655 18.5840840 0.011729161 0.1112869233
#> Campbell’sSoup 13.9884797 0.3655220 0.5688805 15.537637760 0.0001011939
#> ColgateToothpaste 7.0957696 0.3612848 1.4853114 2.620000369 4.1255335476
|
Besar kontribusi variabel baris pada dimensi 1 dan 2 dapat dilihat dengan visualisasi berikut:
1
2
|
# Contributions of rows to dimension 1
fviz_contrib(brand.ca, choice = "row", axes = 1)
|
1
2
|
# Contributions of rows to dimension 2
fviz_contrib(brand.ca, choice = "row", axes = 2)
|
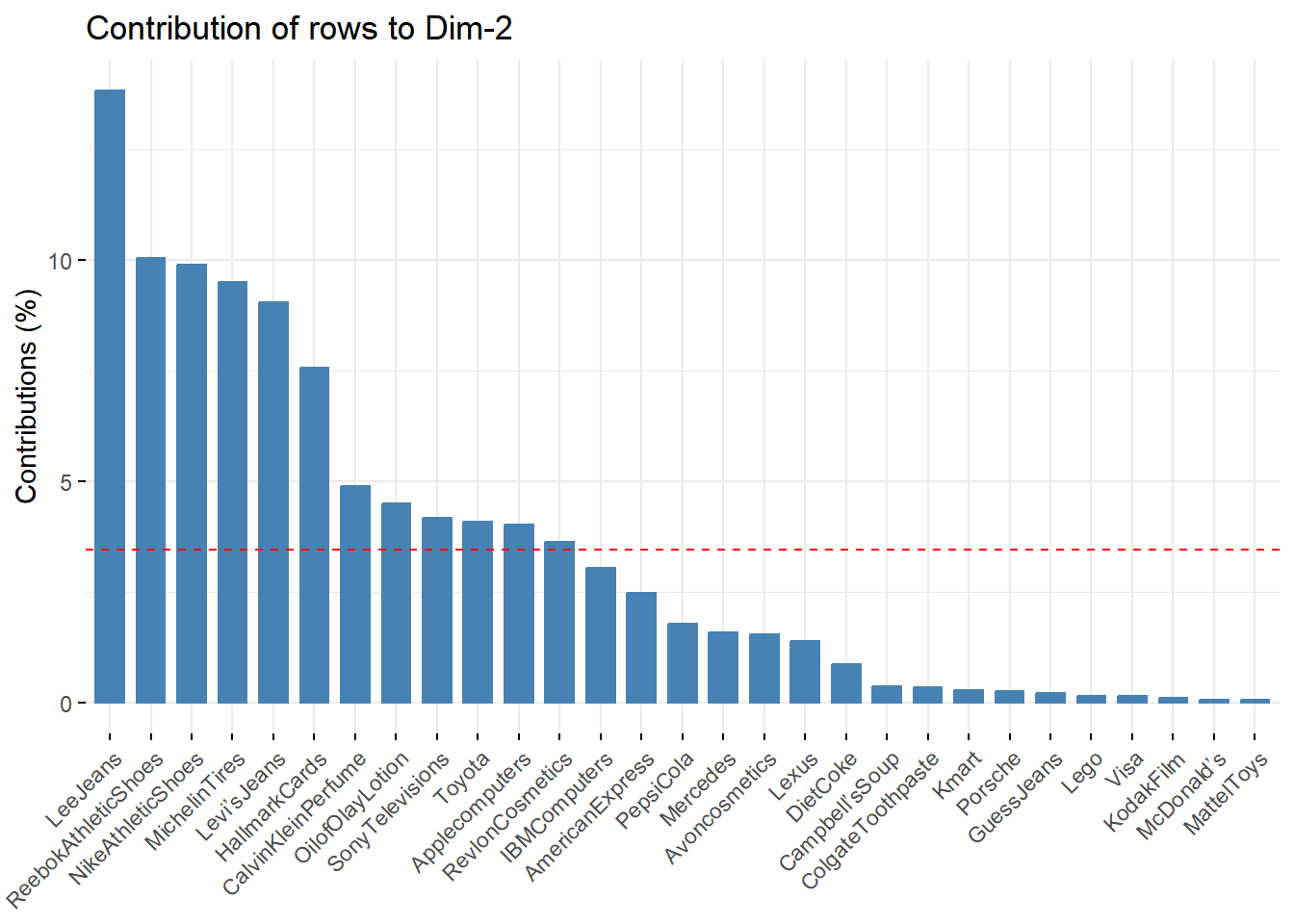
Insight:
- Kategori baris yang paling berkontribusi besar pada dimensi 1 adalah Campbell Soup
- Kategori baris yang paling berkontribusi besar pada dimensi 2 adalah Lee Jeans
Columns Components
Interpretasi untuk komponen kolom sama persis dengan komponen baris.
Komponen fungsi brand-ca$col berisi:
$coord: koordinat setiap titik kolom pada setiap dimensi (1,2,dst). Digunakan untuk membuat plot.$cos2: kualitas representasi kolom.$contrib: kontribusi kolom (dalam %) terhadap definisi dimensi.
1
2
|
# Koordinat kolom
head(brand.ca$col$coord)
|
1
2
3
4
5
6
7
|
#> Dim 1 Dim 2 Dim 3 Dim 4 Dim 5
#> charming -0.11737879 -0.418163663 0.40396413 0.15319744 0.08982199
#> cheerful 0.41831869 -0.008226802 0.22189043 -0.32437698 -0.04503380
#> daring -0.43244316 0.155536449 0.23846887 -0.04804722 -0.03034045
#> down_to_earth 0.59226080 0.162709583 0.07327456 0.15314815 -0.05017338
#> honest 0.35335280 -0.099681167 -0.07699910 0.12707796 0.07533147
#> imaginative 0.04052672 -0.156084506 -0.04996894 -0.36735381 0.22016171
|
1
2
|
# Kualitas representasi tiap kategori kolom pada plot 2 dimensi
head(brand.ca$col$cos2)
|
1
2
3
4
5
6
7
|
#> Dim 1 Dim 2 Dim 3 Dim 4 Dim 5
#> charming 0.033127834 0.4204422544 0.39237325 0.05643088 0.019398990
#> cheerful 0.493577624 0.0001908987 0.13887308 0.29678433 0.005720292
#> daring 0.572866461 0.0741070791 0.17420424 0.00707183 0.002819937
#> down_to_earth 0.784165294 0.0591844903 0.01200295 0.05243305 0.005627667
#> honest 0.666850851 0.0530686284 0.03166525 0.08624862 0.030308505
#> imaginative 0.007462045 0.1106864590 0.01134423 0.61311790 0.220220875
|
1
2
|
# Kontribusi tiap kategori kolom ke dimensi CA
head(brand.ca$col$contrib)
|
1
2
3
4
5
6
7
|
#> Dim 1 Dim 2 Dim 3 Dim 4 Dim 5
#> charming 0.7145703 12.08698709 24.0884326 3.9941901 3.7271069
#> cheerful 11.5566478 0.00595716 9.2544727 22.8022329 1.1929861
#> daring 9.5095497 1.63955506 8.2304292 0.3852107 0.4169527
#> down_to_earth 19.5118693 1.96272261 0.8500345 4.2811101 1.2472700
#> honest 7.6316834 0.80944856 1.0314109 3.2389465 3.0895622
#> imaginative 0.1090617 2.15609846 0.4718964 29.4048067 28.6690710
|
Seperti titik baris, titik kolom juga dapat diwarnai berdasarkan kualitas representasinya pada plot CA yang ditunjukkan nilai cos2:
1
2
3
|
fviz_ca_col(brand.ca, col.col = "cos2",
gradient.cols = c("#00AFBB", "#E7B800", "#FC4E07"),
repel = TRUE)
|
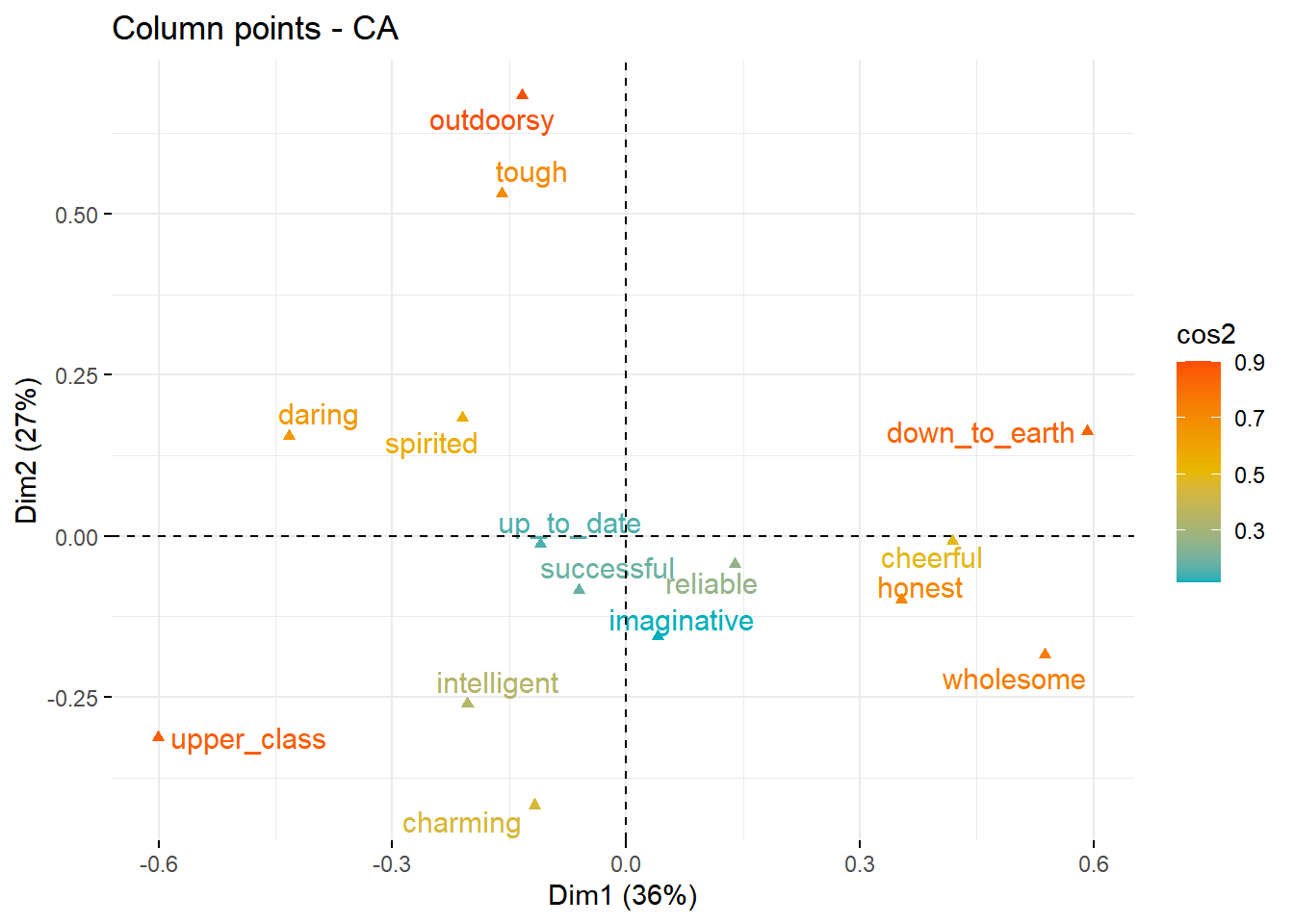
Sementara itu, untuk memvisualisasikan kontribusi kolom ke dua dimensi pertama:
1
2
|
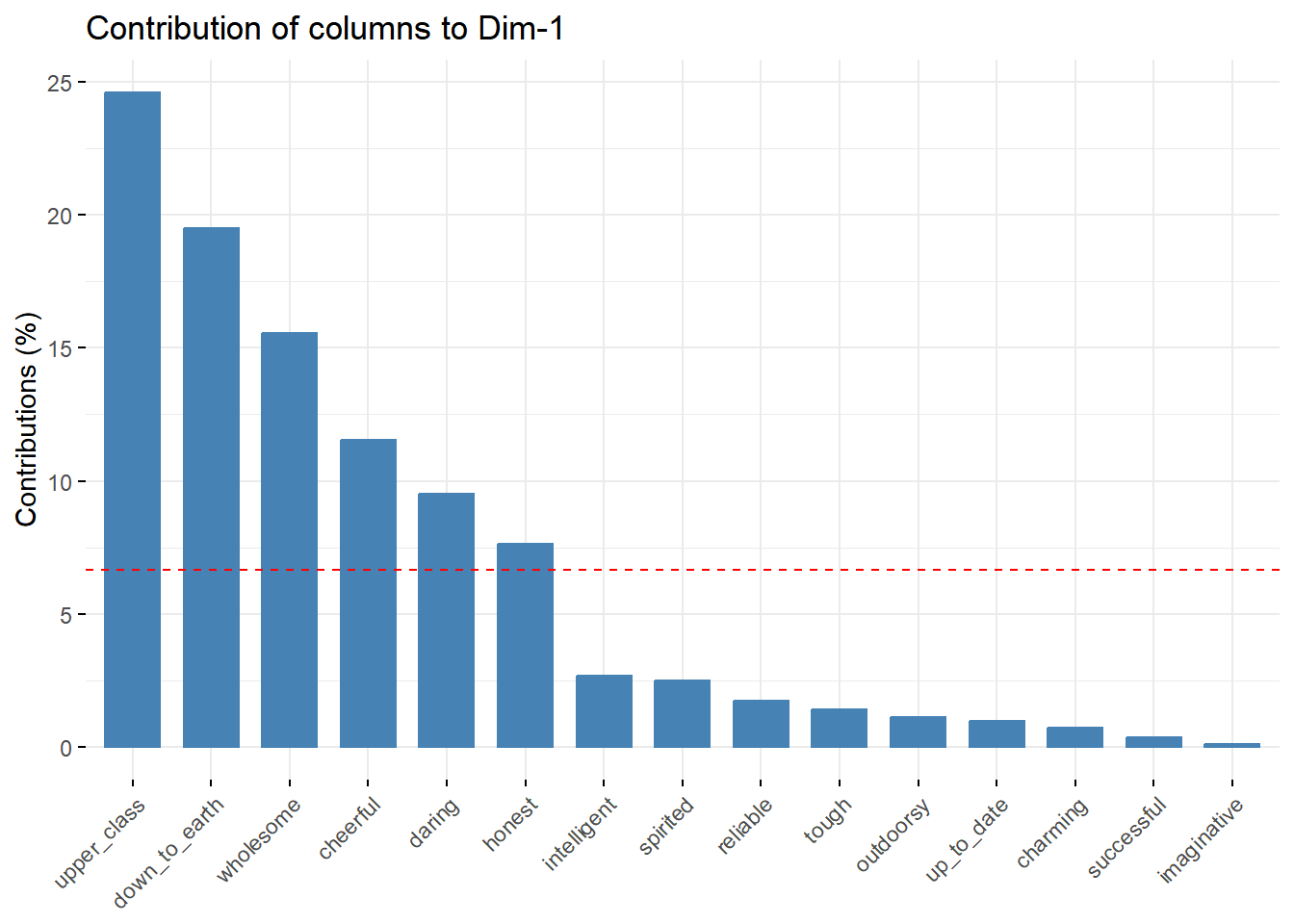
# Contributions of columns to dimension 1
fviz_contrib(brand.ca, choice = "col", axes = 1)
|
1
2
|
# Contributions of columns to dimension 2
fviz_contrib(brand.ca, choice = "col", axes = 2)
|
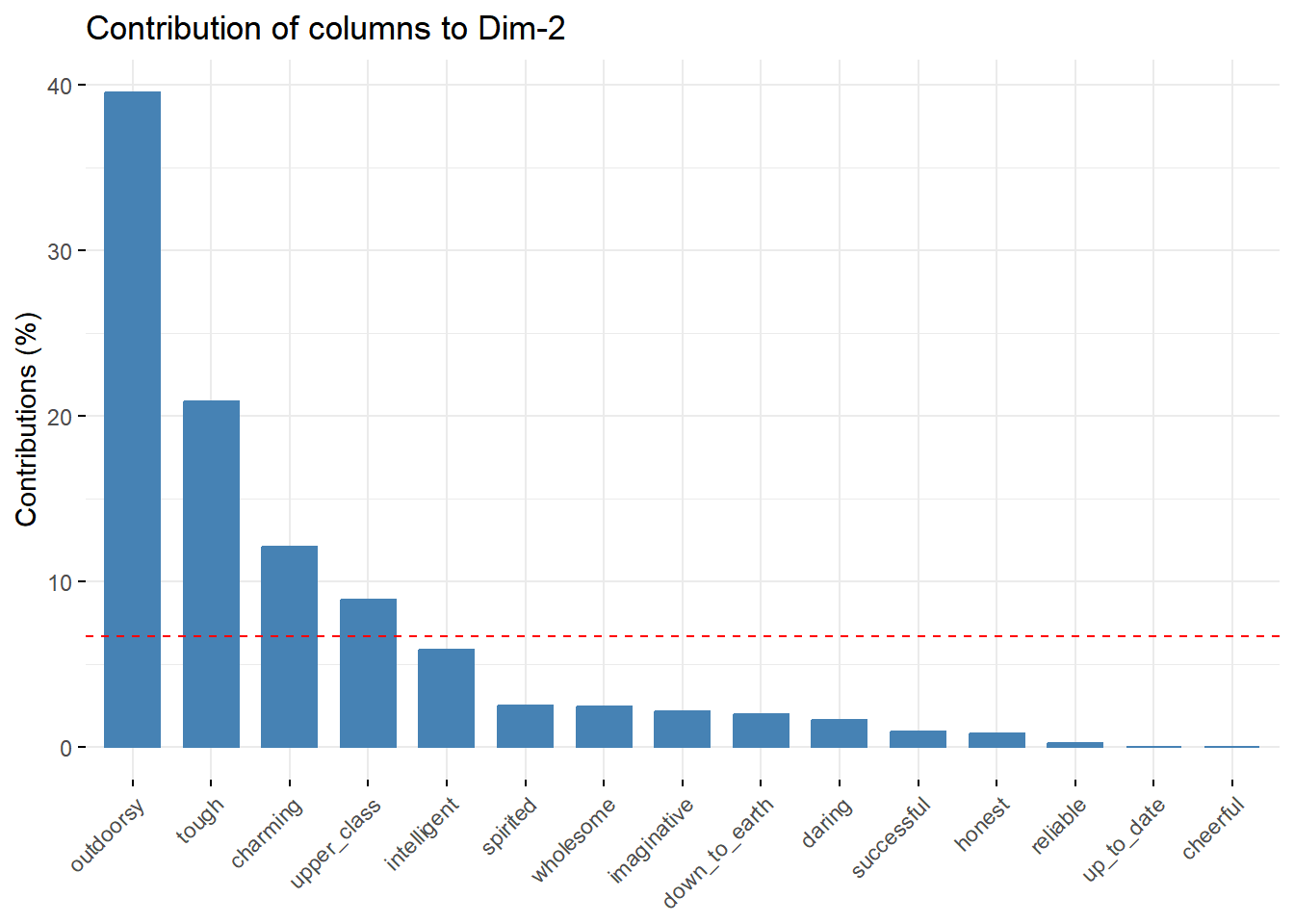
Insight:
- Kategori kolom yang paling berkontribusi besar pada dimensi 1 adalah upper class
- Kategori kolom yang paling berkontribusi besar pada dimensi 2 adalah outdoorsy
Interpretasi Biplot CA
Plot standar analisis korespondensi adalah biplot simetris di mana baris (titik biru) dan kolom (segitiga merah) direpresentasikan dalam ruang yang sama menggunakan koordinat baru.
Biplot pada CA artinya gabungan dua plot, yaitu plot untuk variabel baris dan plot untuk variabel kolom. Koordinat pada biplot CA mewakili profil baris dan kolom. Biplot CA di R dapat diperoleh menggunakan fungsi fviz_ca_biplot(ca objek, repel = TRUE)
1
|
fviz_ca_biplot(brand.ca, repel = TRUE)
|
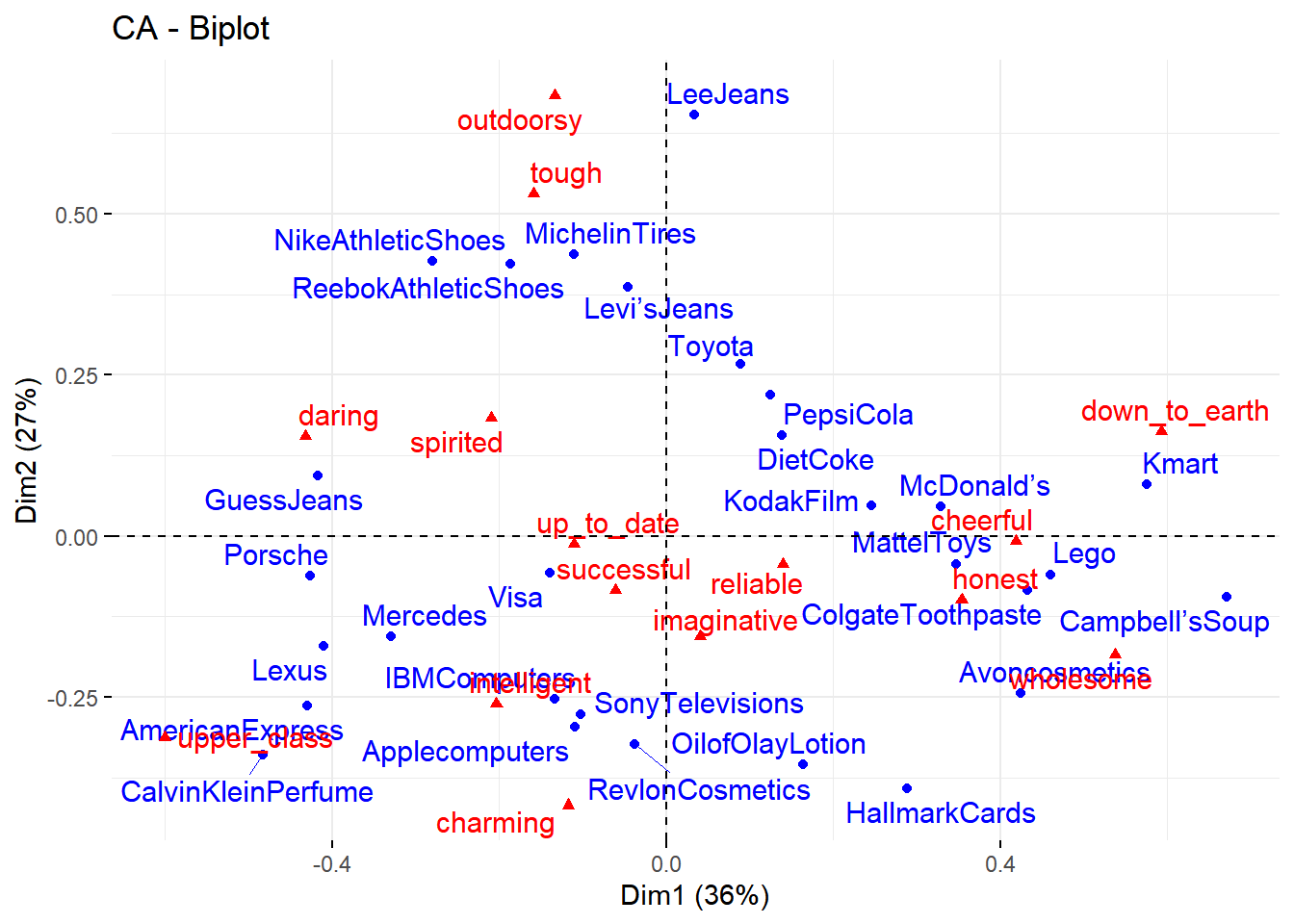
Berikut adalah beberapa poin yang perlu diperhatikan dalam menginterpretasi biplot CA:
- Kedekatan titik kategori dengan titik asal menunjukkan kekhasan kategori tersebut
- Jika titik kategori terletak dekat dengan titik asal plot menunjukkan bahwa kategori tersebut kurang berbeda dari kategori lainnya atau kurang khas
- Semakin jauh suatu kategori dari titik asalnya, semakin diskriminatif kategori tersebut, yang menunjukkan bahwa kategori tersebut memiliki karakteristik khas yang membedakannya dari kategori lain
- Kedekatan suatu titik dengan titik lainnya dalam konteks baris atau kolom menunjukkan kesamaan profil/karakteristik (similarity), jika data discaling dengan benar. Namun fungsi
CA() sudah secara otomatis melakukan scaling.
- Untuk mengetahui hubungan dari kategori baris dan kategori kolom dilihat dari seberapa besar sudut yang terbentuk dari panah baris dan kolom ke titik asalnya. Tambahkan parameter
arrow untuk menampilkan panah baris dan kolom pada biplot.
1
|
fviz_ca_biplot(brand.ca, repel = TRUE, arrows = c(TRUE, TRUE))
|
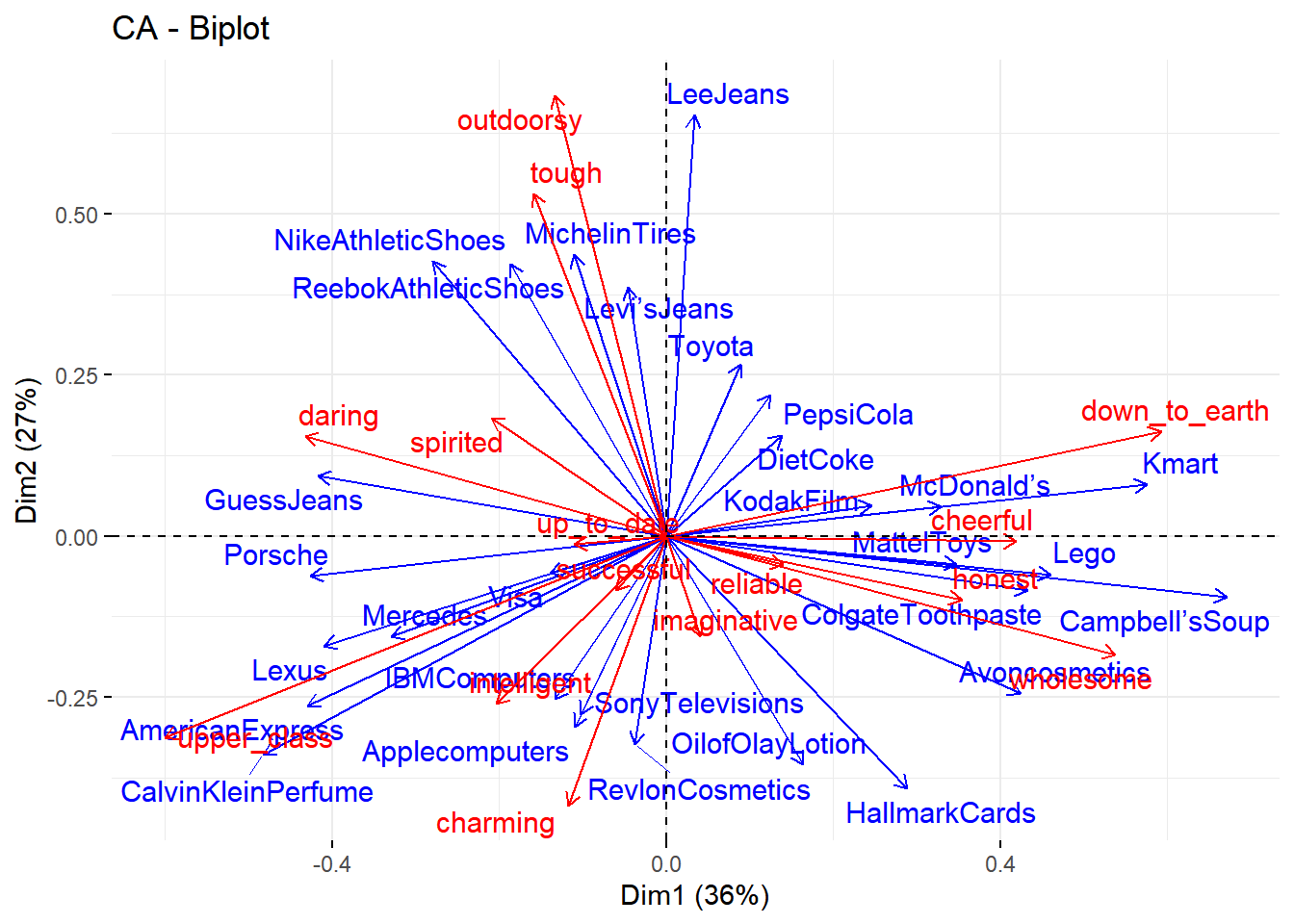
Cara interpretasi hubungan dari kategori baris dan kategori kolom:
- sudut panah baris (biru) dan panah kolom (merah) mendekati 0: kategori baris dan kolom memiliki hubungan positif
- sudut 90 derajat: kategori baris dan kolom tidak memiliki hubungan
- sudut 180 derajat: kategori baris dan kolom memiliki hubungan negatif
- Semakin jauh suatu titik dari titik asalnya, semakin kuat hubungannya dengan suatu kategori lain sesuai kriteria sudutnya (positif/negatif)
Dengan demikian, berdasarkan profil baris (personality), berikut adalah pemetaan untuk data brand personality:
- Tough & spirited: Nike, Reebok, Levi’s Jeans dan Michelin Tires
- Daring: GuessJeans
- Upper_class: CalvinKleinPerfume, AmericanExpress, Lexus
- Charming: Revlon Cosmetics, Apple
- Down_to_eart: Kmart
- Wholesome: Campbell’s Soup, Avoncosmetics
Kesimpulan
Correspondence Analysis memberikan hasil visualisasi yang mudah diinterpretasi sehingga kita dengan mudah menemukan asosiasi dari dua kategori variabel. CA dapat membantu kita mendefinisikan personality (variabel kolom) dari suatu brand (variabel baris). Sebelumnya, telah dibahas juga detail komponen analisis korespondensi dan intuisi matematikanya. Berdasarkan analisis yang telah dilakukan, diperoleh terdapat beberapa pemetaan personality untuk brand-brand yang ada. Jika dibandingkan dengan ballon plot dan mosaicplot, ada beberapa hasil pemetaan yang sama. Namun, CA memberikan hasil pemetaan yang lebih kuat dengan memvisualisasikan hubungan kedua variabel pada biplot.
Setelah mengetahui pemetaan personality untuk masing-masing brand, perusahaan dapat memaksimalkan marketingnya dengan memperkuat personality yang telah melekat serta merumuskan strategi brand positioning.
Correspondence Analysis Workflow
- Import Data
- Data Preprocessing: Contingency Table
- EDA: Ballonplot & Mosaicplot (Optional)
- Chi-Square Test
- Row component & column component
- Biplot Interpretation
Reference
