Retail
Customer Segmentation with RFM Analysis (in Python Programming Language)
Background
Dalam transaksi jual beli, customer memiliki peran penting dalam eksistensi dan kemajuan sebuah industri. Oleh karenanya berbagai strategi marketing dilakukan untuk menarik perhatian customer baru atau untuk mempertahankan loyalitas customer.
Cara yang paling umum dilakukan adalah pemberian diskon pada product tertentu atau pemberian free product untuk customer tertentu. Strategi marketing ini diterapkan sesuai dengan value yang dimiliki oleh customer. Beberapa value dapat dikategorikan menjadi low-value customer (customer dengan frekuensi transaksi rendah dan spend money rendah), medium-value customer (customer dengan frekuensi transaksi tinggi namun spend money rendah atau sebaliknya), dan high-value customer (customer dengan frekuensi transaksi tinggi dan spend money yang tinggi pula).
Dalam melakukan segmentasi customer ada beberapa faktor yang harus dipertimbangkan. Faktor tersebut umumnya dianalisis berdasarkan data historical transaksi yang dimiliki oleh customer. Dari data historical tersebut dilakukan analisis lebih lanjut untuk mengetahui pattern data dan kemudian dilakukan modelling dengan bantuan algoritma machine learning agar menghasilkan output yang dapat dipertanggungjawabkan. Rangkaian proses ini nantinya diharapkan dapat menjawab beberapa pertanyaan bisnis seperti :
Siapakah customer yang berpotensi untuk *churn*, Siapakah loyal customer, Siapakah potential customer, dan lain-lain.
Metode segmentasi yang paling umum digunakan untuk melakukan segmentasi customer adalah RFM analysis. RFM akan melakukan segmentasi berdasarkan 3 poin penting yaitu :
- Recency : Waktu transaksi terakhir yang dilakukan customer
- Frequency : Banyak transaksi yang dilakukan oleh customer
- Monetary : Banyak uang yang dikeluarkan ketika melakukan transaksi
Dalam artikel ini, akan dibahas lebih lanjut tentang proses segmentasi customer menggunakan metode RFM dengan bantuan machine learning clustering algorithm. Bahasa yang digunakan adalah bahasa pemrograman python.

Modelling Analysis
Pada artikel ini data yang digunakan adalah data online retail di UK yang dapat ditemukan pada link berikut. Data ini adalah data transaksi yang terjadi pada 01/12/2010 sampai 09/12/2011.
Import Library and Read Data
1
2
3
4
5
6
7
|
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
pd.options.mode.chained_assignment = None
# Suppress the warning (not recommended for general use)
import warnings
warnings.simplefilter(action='ignore', category=pd.errors.SettingWithCopyWarning)
|
1
|
ecom = pd.read_csv("data_ecom_uk.csv",encoding='latin1')
|
#> InvoiceNo StockCode ... CustomerID Country
#> 0 536365 85123A ... 17850.0 United Kingdom
#> 1 536365 71053 ... 17850.0 United Kingdom
#>
#> [2 rows x 8 columns]
#> (541909, 8)
Dataframe ini mengandung 541909 observasi dengan jumlah kolom sebanyak 8 yang antara lain adalah :
InvoiceNo : Nomor invoice yang terdiri dari 6 digit angka unik. Ketika InvoiceNo diawali dengan character C maka mengindikasikan cancellation transaction.StockCode : Kode product yang terdiri dari 5 digit angka unik.Description : Deskripsi nama product.Quantity : Jumlah product yang dibeli pada setiap transaksi.InvoiceDate : Tanggal transaksi berlangsung.UnitPrice : Harga satuan product.CustomerID : ID Customer yang berisi 5 digit angka unik dan berbeda pada setiap customer.Country : Nama negara.
Get only transaction in UK
Dikarenakan terdapat beberapa data yang tidak berada pada country United Kingdom (UK), maka perlu dilakukan filter data hanya untuk country daerah UK.
1
2
|
ecom_uk = ecom[ecom['Country']=='United Kingdom']
ecom_uk.shape
|
#> (495478, 8)
#> InvoiceNo StockCode ... CustomerID Country
#> 0 536365 85123A ... 17850.0 United Kingdom
#> 1 536365 71053 ... 17850.0 United Kingdom
#>
#> [2 rows x 8 columns]
Handle Missing Values
Missing value adalah masalah yang umum dihadapi ketika melakukan proses pengolahan data. Missing value terjadi ketika terdapat obeservasi kosong pada sebuah data.
Pada hasil di bawah ini dapat diketahui informasi bahwa beberapa variable pada data menggandung nilai missing, variable tersebut antara lain adalah Description dan CustomerID. CustomerID adalah variable penting dalam RFM analisis, dikarenakan CustomerID mengandung informasi unik ID member. Sedangkan Description mengandung informasi terkait deskripsi produk. Jika ditelaah lebih jauh, untuk menangani missing values pada kedua variable tersebut dapat dilakukan dengan cara deletion, dikarenakan proses imputasi pada kedua variable tersebut akan menghasilkan informasi yang tidak akurat.
#> InvoiceNo 0
#> StockCode 0
#> Description 1454
#> Quantity 0
#> InvoiceDate 0
#> UnitPrice 0
#> CustomerID 133600
#> Country 0
#> dtype: int64
Berikut ini adalah proses penghapusan missing values pada data :
1
|
ecom_uk.dropna(inplace=True)
|
Select Unique Transaction
Duplicated values atau duplikasi data adalah nilai berulang pada satu atau lebih observasi. Untuk menangani data yang duplikat dapat dilakukan penghapusan dan hanya mempertahankan salah satu observasi.
1
|
ecom_uk.drop_duplicates(subset=['InvoiceNo', 'CustomerID'], keep="first", inplace=True)
|
Change Data Types
Dalam pengolahan data transformasi tipe data pada format yang sesuai sangat penting untuk dilakukan, hal ini agar nantinya data-data tersebut siap untuk dilakukan manipulasi lebih lanjut.
#> InvoiceNo object
#> StockCode object
#> Description object
#> Quantity int64
#> InvoiceDate object
#> UnitPrice float64
#> CustomerID float64
#> Country object
#> dtype: object
1
2
3
|
ecom_uk['InvoiceDate'] = pd.to_datetime(ecom_uk['InvoiceDate'])
ecom_uk['Country'] = ecom_uk['Country'].astype('category')
ecom_uk['CustomerID'] = ecom_uk['CustomerID'].astype('int64')
|
Drop cancelled transaction
Karakter pertama “C” pada InvoiceNo menunjukkan bahwa customer melakukan pembatalan terhadap transaksi yang dilakukan. Sehingga data akan kurang relevan jika tetap dipertahankan, maka dari itu perlu dilakukan penghapusan pada observasi tersebut.
1
|
ecom_uk = ecom_uk.loc[~ecom_uk.iloc[:,0].str.contains(r'C')]
|
#> InvoiceNo StockCode ... CustomerID Country
#> 0 536365 85123A ... 17850 United Kingdom
#> 7 536366 22633 ... 17850 United Kingdom
#> 9 536367 84879 ... 13047 United Kingdom
#> 21 536368 22960 ... 13047 United Kingdom
#> 25 536369 21756 ... 13047 United Kingdom
#>
#> [5 rows x 8 columns]
Exploratory Data Analysis
Tahapan Exploratory Data Analysis digunakan untuk mengetahui pattern dari data.
Recency
Recency adalah faktor yang menyimpan informasi tentang berapa lama sejak customer melakukan pembelian. Untuk melakukan perhitungan recency pada masing-masing customer dapat dilakukan dengan cara memanipulasi tanggal transaksi customer dan kemudian dikurangi dengan tanggal maksimum yang terdapat pada data. Berikut di bawah ini adalah detail langkah-langkahnya :
- Manipulasi tanggal transaksi dengan mengekstrak informasi tanggal, bulan dan tahun transaksi.
1
|
ecom_uk['Date'] = ecom_uk['InvoiceDate'].dt.date
|
#> InvoiceNo StockCode ... Country Date
#> 0 536365 85123A ... United Kingdom 2010-12-01
#> 7 536366 22633 ... United Kingdom 2010-12-01
#>
#> [2 rows x 9 columns]
- Mengambil tanggal transaksi maksimum pada keseluruhan observasi
1
2
|
last_trans = ecom_uk['Date'].max()
last_trans
|
#> datetime.date(2011, 12, 9)
- Mengekstrak informasi tanggal transaksi maksimum pada tiap customer.
1
|
recent = ecom_uk.groupby(by=['CustomerID'], as_index=False)['Date'].max()
|
1
2
|
recent.columns = ['CustomerID','Last Transaction']
recent.head()
|
#> CustomerID Last Transaction
#> 0 12346 2011-01-18
#> 1 12747 2011-12-07
#> 2 12748 2011-12-09
#> 3 12749 2011-12-06
#> 4 12820 2011-12-06
- Menghitung selisih tanggal transaksi maksimum dengan tanggal transaksi terakhir pada tiap customer, kemudian menyimpan jumlah hari pada kolom
Days Recent.
1
2
3
4
5
6
7
8
9
10
11
|
recent['Last Transaction'] = pd.to_datetime(recent['Last Transaction'])
import pandas as pd
# Ensure datetime format
recent['Last Transaction'] = pd.to_datetime(recent['Last Transaction'])
if not isinstance(last_trans, pd.DatetimeIndex):
last_trans = pd.to_datetime(last_trans)
# Calculate days difference
recent['Days Recent'] = last_trans - recent['Last Transaction']
recent['Days Recent'] = recent['Days Recent'].dt.days
|
#> CustomerID Last Transaction Days Recent
#> 0 12346 2011-01-18 325
#> 1 12747 2011-12-07 2
#> 2 12748 2011-12-09 0
#> 3 12749 2011-12-06 3
#> 4 12820 2011-12-06 3
1
|
recent.drop(columns=['Last Transaction'], inplace=True)
|
Frequency
Frequency mengandung infromasi tentang seberapa sering customer melakukan transaksi pembelian dalam kurun waktu tertentu. Nilai frequency dapat diperoleh dengan cara menghitung jumlah transkasi pada setiap unik customer.
1
|
temp = ecom_uk[['CustomerID','InvoiceNo']]
|
1
2
|
trans_cust = temp.groupby(by=['CustomerID']).count()
trans_cust.rename(columns={'InvoiceNo':'Number of Transaction'})
|
#> Number of Transaction
#> CustomerID
#> 12346 1
#> 12747 11
#> 12748 210
#> 12749 5
#> 12820 4
#> ... ...
#> 18280 1
#> 18281 1
#> 18282 2
#> 18283 16
#> 18287 3
#>
#> [3921 rows x 1 columns]
1
|
trans_cust.reset_index()
|
#> CustomerID InvoiceNo
#> 0 12346 1
#> 1 12747 11
#> 2 12748 210
#> 3 12749 5
#> 4 12820 4
#> ... ... ...
#> 3916 18280 1
#> 3917 18281 1
#> 3918 18282 2
#> 3919 18283 16
#> 3920 18287 3
#>
#> [3921 rows x 2 columns]
Ouptut di atas menunjukkan jumlah transaksi yang dilakukan pada masing-masing customer. CustomerID 12346 melakukan transaksi sebanyak 1 kali saja, CustomerID 12747 melakukan transaksi sebanyak 11 kali, dan seterusnya.
Berikut dibawah ini adalah detail informasi InvoiceNo pada setiap transaksi yang dilakukan oleh customer.
1
|
table_trans_details = temp.groupby(by=['CustomerID','InvoiceNo']).count()
|
1
|
table_trans_details.head()
|
#> Empty DataFrame
#> Columns: []
#> Index: [(12346, 541431), (12747, 537215), (12747, 538537), (12747, 541677), (12747, 545321)]
Monetary
Monetary adalah faktor yang menyimpan jumlah pengeluaran customer dalam transaksi. Nilai monetary dapat dihitung dari harga barang yang dibeli oleh masing-masing customer pada transaksi tertentu dan kemudian dikalkulasikan dengan jumlah barang yang dibeli.
1
2
|
ecom_uk['Total'] = ecom_uk['UnitPrice'] * ecom_uk['Quantity']
ecom_uk.head(2)
|
#> InvoiceNo StockCode ... Date Total
#> 0 536365 85123A ... 2010-12-01 15.3
#> 7 536366 22633 ... 2010-12-01 11.1
#>
#> [2 rows x 10 columns]
1
|
monetary = ecom_uk.groupby(by=['CustomerID'], as_index=False)['Total'].sum()
|
#> CustomerID Total
#> 0 12346 77183.60
#> 1 12747 689.49
#> 2 12748 3841.31
#> 3 12749 98.35
#> 4 12820 58.20
#> ... ... ...
#> 3916 18280 23.70
#> 3917 18281 5.04
#> 3918 18282 38.25
#> 3919 18283 66.75
#> 3920 18287 80.40
#>
#> [3921 rows x 2 columns]
Merge Column based on CustomerID
Setelah mendapatkan informasi pada setiap faktor penting, langkah selanjutnya adalah menyimpannya kedalam sebuah dataframe baru.
1
2
3
4
|
new_ = monetary.merge(trans_cust,on='CustomerID')
new_data = new_.merge(recent,on='CustomerID')
new_data.rename(columns={'Total':'Monetary','InvoiceNo':'Frequency','Days Recent':'Recency'}, inplace=True)
new_data.head()
|
#> CustomerID Monetary Frequency Recency
#> 0 12346 77183.60 1 325
#> 1 12747 689.49 11 2
#> 2 12748 3841.31 210 0
#> 3 12749 98.35 5 3
#> 4 12820 58.20 4 3
Modelling
Clustering Recency, Frequency, and Monetary
Proses clustering bertujuan untuk membagi level customer kedalam beberapa segment tertentu meliputi low-value customer, medium-value customer or high-value customer.
Recency
Pada faktor Recency, customer yang memiliki recent trasaksi akan di kategorikan pada high-value customer. Kenapa? Karena customer tersebut berpotensi untuk melakukan pembelian lagi dibanding dengan customer yang sudah lama tidak melakukan pembelian.
1
|
new_data['Recency'].describe()
|
#> count 3921.000000
#> mean 91.722265
#> std 99.528532
#> min 0.000000
#> 25% 17.000000
#> 50% 50.000000
#> 75% 142.000000
#> max 373.000000
#> Name: Recency, dtype: float64
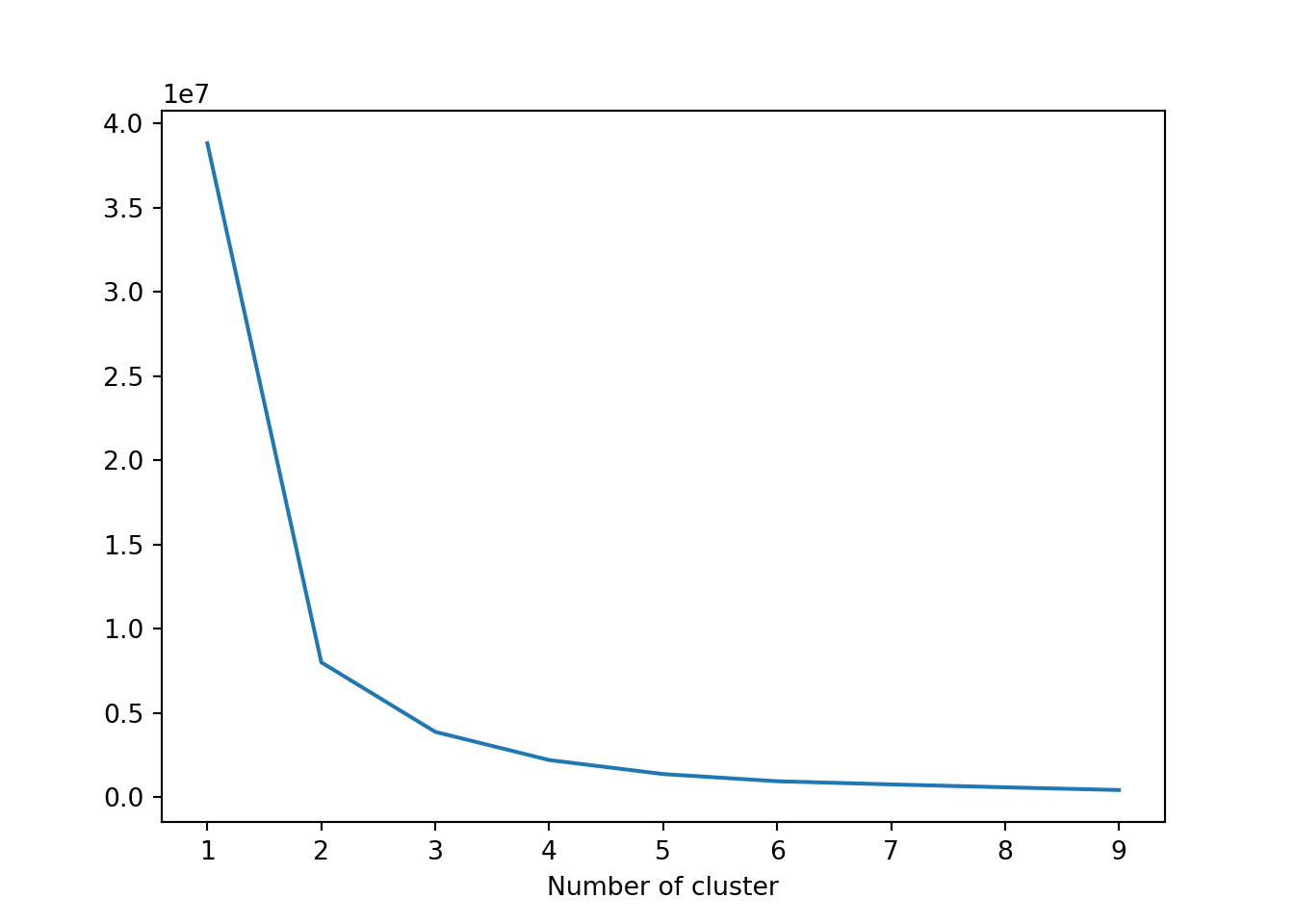
Teknik elbow mwthod untuk menentukan jumlah cluster yang terbentuk.
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from sklearn.cluster import KMeans
sse={}
recency = new_data[['Recency']]
for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(recency)
recency["clusters"] = kmeans.labels_
sse[k] = kmeans.inertia_
plt.figure()
plt.plot(list(sse.keys()), list(sse.values()))
plt.xlabel("Number of cluster")
plt.show()
|
1
2
|
kmeans = KMeans(n_clusters=3)
kmeans.fit(new_data[['Recency']])
|
KMeans(n_clusters=3)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
1
|
new_data['RecencyCluster'] = kmeans.predict(new_data[['Recency']])
|
1
|
new_data.groupby('RecencyCluster')['Recency'].describe()
|
#> count mean std ... 50% 75% max
#> RecencyCluster ...
#> 0 709.0 159.358251 37.559764 ... 158.0 191.0 227.0
#> 1 2673.0 32.680883 26.125380 ... 25.0 52.0 96.0
#> 2 539.0 295.551020 44.264820 ... 288.0 327.5 373.0
#>
#> [3 rows x 8 columns]
Berdasarkan visualisasi grafik elbow, maka jumlah cluster ideal yang dapat dibentuk adalah sebanyak 3 cluster. Pada hasil di atas menunjukkan bahwa cluster 1 mengandung informasi customer yang melakukan transaksi paling baru (most recent) sedangkan cluster 0 mengandung informasi customer yang sudah lama tidak melakukan transaksi pembelian.
Untuk keperluan standarisasi, maka perlu dilakukan re-order cluster sehingga cluster 0 akan memuat informasi low-value customer, cluster 1 medium-value customer dan cluster 2 high-value customer.
Dikarenakan step ini adalah step Recency, maka cluster yang memiliki nilai recency rendah akan dikategorikan pada cluster 2.
Dibawah ini adalah fungsi untuk melakukan reorder cluster :
1
2
3
4
5
6
7
8
9
10
|
#function for ordering cluster numbers
def order_cluster(cluster_field_name, target_field_name,df,ascending):
new_cluster_field_name = 'new_' + cluster_field_name
df_new = df.groupby(cluster_field_name)[target_field_name].mean().reset_index()
df_new = df_new.sort_values(by=target_field_name,ascending=ascending).reset_index(drop=True)
df_new['index'] = df_new.index
df_final = pd.merge(df,df_new[[cluster_field_name,'index']], on=cluster_field_name)
df_final = df_final.drop([cluster_field_name],axis=1)
df_final = df_final.rename(columns={"index":cluster_field_name})
return df_final
|
1
|
new_data = order_cluster('RecencyCluster', 'Recency',new_data,False)
|
Frequency
Factor penting selanjutnya adalah Frequency. Pada step frequency, customer yang memiliki banyak transaksi pembelian akan dikategorikan pada level high-value customer.
1
|
new_data['Frequency'].describe()
|
#> count 3921.000000
#> mean 4.246111
#> std 7.205750
#> min 1.000000
#> 25% 1.000000
#> 50% 2.000000
#> 75% 5.000000
#> max 210.000000
#> Name: Frequency, dtype: float64
1
2
3
4
5
6
7
8
9
10
|
sse={}
frequency = new_data[['Frequency']]
for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(frequency)
frequency["clusters"] = kmeans.labels_
sse[k] = kmeans.inertia_
plt.figure()
plt.plot(list(sse.keys()), list(sse.values()))
plt.xlabel("Number of cluster")
plt.show()
|
1
2
|
kmeans = KMeans(n_clusters=3)
kmeans.fit(new_data[['Frequency']])
|
KMeans(n_clusters=3)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
1
2
|
new_data['FrequencyCluster'] = kmeans.predict(new_data[['Frequency']])
new_data.groupby('FrequencyCluster')['Frequency'].describe()
|
#> count mean std min 25% 50% 75% max
#> FrequencyCluster
#> 0 3505.0 2.647932 1.897152 1.0 1.0 2.0 4.0 8.0
#> 1 19.0 72.421053 40.239996 44.0 47.5 57.0 88.5 210.0
#> 2 397.0 15.093199 6.705860 9.0 10.0 13.0 18.0 41.0
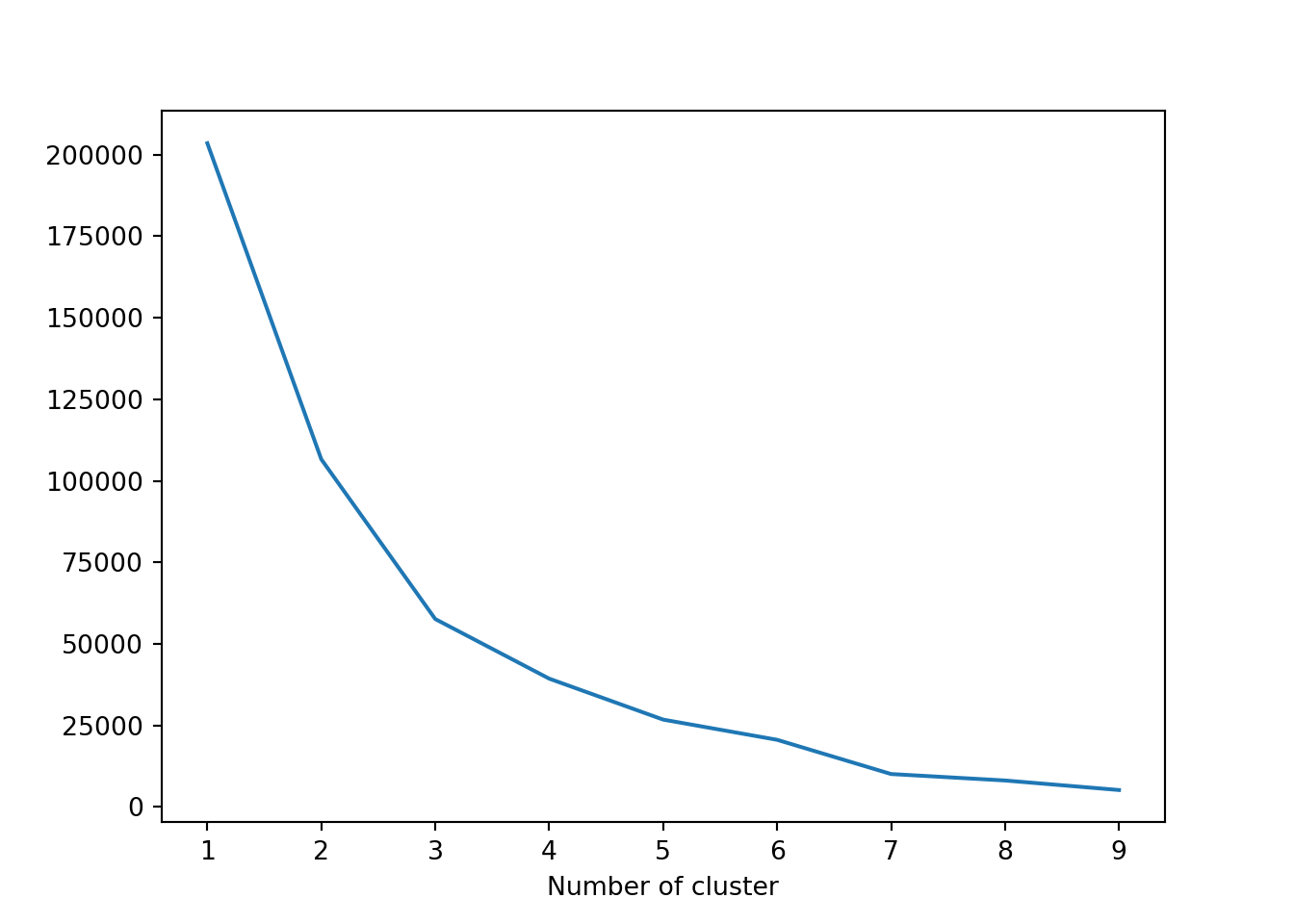
Sama halnya dengan tahapan pada step Recency, pada step ini juga perlu dilakukan standarisasi cluster dengan melakukan reorder pada cluster. Sehingga cluster 0 dengan nilai frequency yang rendah akan dikategorikan pada level low-value customer sedangkan cluster 2 dengan nilai frequency tinggi akan dikategorikan pada level high-values customer.
1
|
new_data = order_cluster('FrequencyCluster', 'Frequency',new_data,True)
|
Monetary
Faktor penting terakhir pada RFM analysis adalah Monetary. Customer dengan nilai monetary yang tinggi akan dikategorikan pada level high-value customer dikarenakan berkontribusi besar dalam pendapatan yang dihasilkan industry.
1
|
new_data['Monetary'].describe()
|
#> count 3921.000000
#> mean 293.299913
#> std 3261.756525
#> min 0.000000
#> 25% 17.700000
#> 50% 45.400000
#> 75% 124.500000
#> max 168471.250000
#> Name: Monetary, dtype: float64
1
2
3
4
5
6
7
8
9
10
|
sse={}
monetary_ = new_data[['Monetary']]
for k in range(1, 10):
kmeans = KMeans(n_clusters=k, max_iter=1000).fit(monetary_)
monetary_["clusters"] = kmeans.labels_
sse[k] = kmeans.inertia_
plt.figure()
plt.plot(list(sse.keys()), list(sse.values()))
plt.xlabel("Number of cluster")
plt.show()
|
1
2
|
kmeans = KMeans(n_clusters=3)
kmeans.fit(new_data[['Monetary']])
|
KMeans(n_clusters=3)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
1
2
|
new_data['MonetaryCluster'] = kmeans.predict(new_data[['Monetary']])
new_data.groupby('MonetaryCluster')['Monetary'].describe()
|
#> count mean ... 75% max
#> MonetaryCluster ...
#> 0 3914.0 189.384371 ... 123.200 17895.28
#> 1 1.0 168471.250000 ... 168471.250 168471.25
#> 2 6.0 40051.213333 ... 41519.325 77183.60
#>
#> [3 rows x 8 columns]
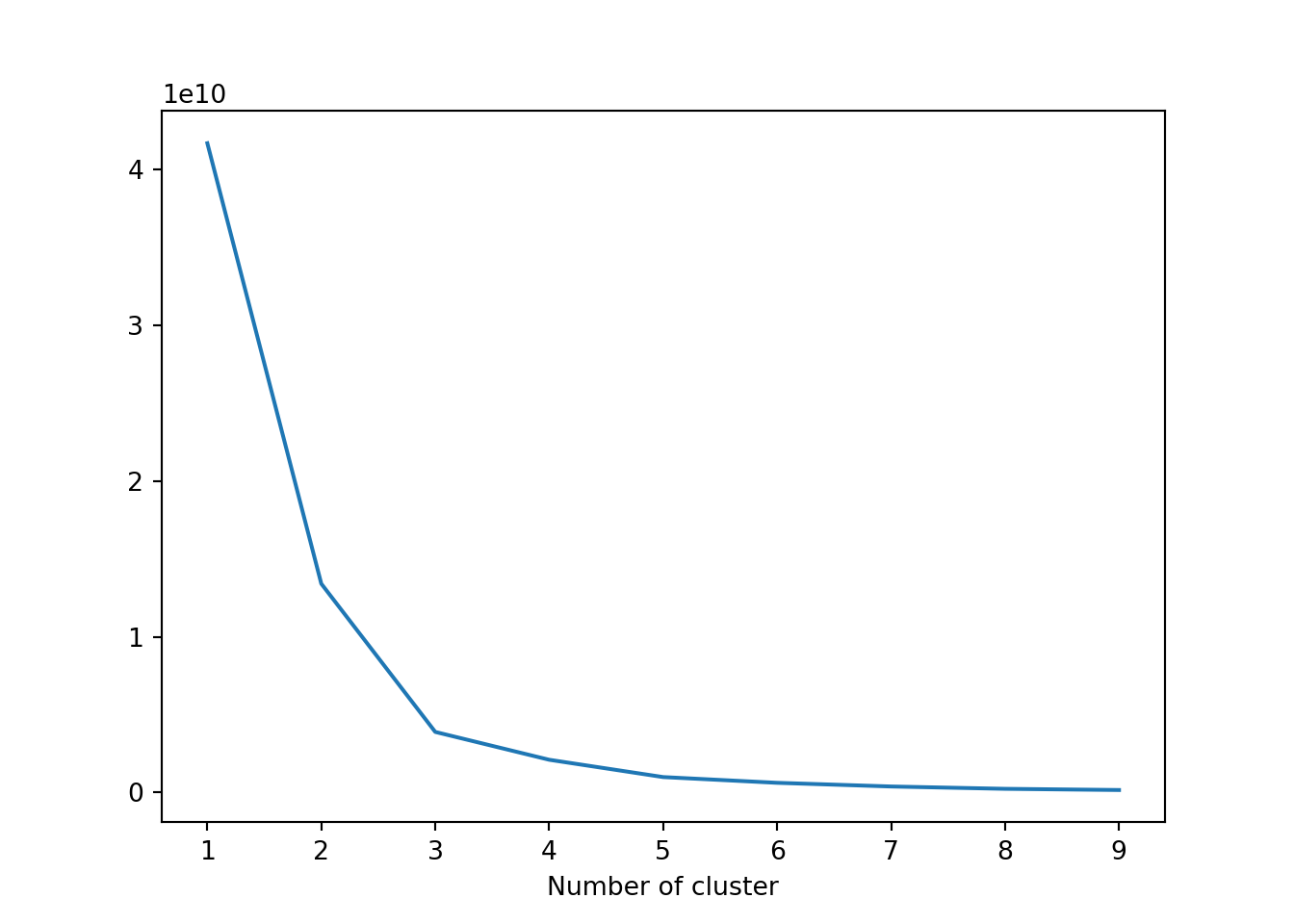
Reorder cluster untuk standarisasi cluster sehingga cluster 0 dengan nilai monetary rendah akan dikategorikan dalam low-value customer sedangkan cluster 2 dengan nilai monetary tinggi akan dikelompokkan pada high-values customer.
1
|
new_data = order_cluster('MonetaryCluster', 'Monetary',new_data,True)
|
Segmentation Customer based on Cluster
Setelah memperoleh nilai cluster terurut pada setiap observasi data, langkah selanjutnya adalah memberikan label pada masing-masing observasi. Label ini bertujuan untuk mengidentifikasi level pada masing-masing customer apakah tergolong pada low-value customer, medium-value customer atau high-value customer.
Proses pelabelan terdiri dari beberapa tahapan yang antara lain adalah :
#> CustomerID Monetary ... FrequencyCluster MonetaryCluster
#> 0 12346 77183.60 ... 0 1
#> 1 15098 39916.50 ... 0 1
#> 2 16029 24384.92 ... 2 1
#> 3 17450 26768.97 ... 2 1
#> 4 17949 29999.69 ... 2 1
#>
#> [5 rows x 7 columns]
- Menghitung score pada masing-masing observasi dengan melakukan penjumlahan pada nilai cluster.
1
2
|
new_data['Score'] = new_data['RecencyCluster'] + new_data['FrequencyCluster'] + new_data['MonetaryCluster']
new_data.head(2)
|
#> CustomerID Monetary Frequency ... FrequencyCluster MonetaryCluster Score
#> 0 12346 77183.6 1 ... 0 1 1
#> 1 15098 39916.5 3 ... 0 1 2
#>
#> [2 rows x 8 columns]
1
|
print(new_data['Score'].min())
|
#> 0
1
|
print(new_data['Score'].max())
|
#> 5
Dari hasil di atas diperoleh informasi bahwa minimum score pada data adalah 0, sedangkan maksimum value pada data adalah 4. Sehingga untuk segmentasi label dapat dikategorikan berdasarkan ketentuan berikut :
- Customer dengan score <= 1 akan masuk dalam kategori
low-value customer
- Customer dengan score <= 3 akan masuk dalam kategori
medium-value customer
- Customer dengan score > 3 akan masuk dalam kategori
high-value customer
1
2
3
4
5
6
7
8
9
10
|
label = []
def label_(data) :
if data <= 1 :
lab = "Low"
elif data <= 3 :
lab = "Medium"
else :
lab = "High"
label.append(lab)
|
1
|
new_data['Score'].apply(label_)
|
#> 0 None
#> 1 None
#> 2 None
#> 3 None
#> 4 None
#> ...
#> 3916 None
#> 3917 None
#> 3918 None
#> 3919 None
#> 3920 None
#> Name: Score, Length: 3921, dtype: object
1
|
new_data['Label'] = label
|
#> CustomerID Monetary Frequency ... MonetaryCluster Score Label
#> 0 12346 77183.6 1 ... 1 1 Low
#> 1 15098 39916.5 3 ... 1 2 Medium
#>
#> [2 rows x 9 columns]
Customer’s behavior in each factor based on their label
Setelah memberikan label pada masing-masing customer, apakah sudah cukup membantu untuk tim management dalam menentukan strategi marketing yang tepat? Jawabannya dapat Ya atau Tidak. Tidak dikarenakan management perlu untuk mengetahui informasi detail dari behavior (kebiasaan) customer pada setiap level dalam melakukan pembelanjaan. Oleh karena itu, sebelum melangkah lebih jauh, terlebih dahulu lakukan behavior analisis sebagai berikut :
1
2
3
4
5
6
7
8
9
10
11
12
|
import numpy as np
def neg_to_zero(x):
if x <= 0:
return 1
else:
return x
new_data['Recency'] = [neg_to_zero(x) for x in new_data.Recency]
new_data['Monetary'] = [neg_to_zero(x) for x in new_data.Monetary]
rfm_log = new_data[['Recency', 'Frequency', 'Monetary']].apply(np.log, axis = 1).round(3)
|
1
2
3
4
5
6
|
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
rfm_scaled = scaler.fit_transform(rfm_log)
rfm_scaled = pd.DataFrame(rfm_scaled, index = new_data.index, columns = rfm_log.columns)
|
#> Recency Frequency Monetary
#> 0 1.389971 -1.049966 4.788147
#> 1 0.996792 0.170733 4.359157
#> 2 -0.064790 3.551812 4.038228
#> 3 -1.121628 3.203041 4.098768
#> 4 -2.530970 3.178605 4.172979
1
2
|
rfm_scaled['Label'] = new_data.Label
rfm_scaled['CustomerID'] = new_data.CustomerID
|
#> Recency Frequency Monetary Label CustomerID
#> 0 1.389971 -1.049966 4.788147 Low 12346
#> 1 0.996792 0.170733 4.359157 Medium 15098
#> 2 -0.064790 3.551812 4.038228 High 16029
#> 3 -1.121628 3.203041 4.098768 High 17450
#> 4 -2.530970 3.178605 4.172979 High 17949
#> ... ... ... ... ... ...
#> 3916 -2.530970 3.960563 2.967380 High 15311
#> 3917 -1.785964 3.226367 3.836427 High 16013
#> 3918 -0.610495 3.317447 2.977145 High 16422
#> 3919 -2.530970 4.303780 2.165383 High 17841
#> 3920 -2.530970 -0.280226 5.296556 High 16446
#>
#> [3921 rows x 5 columns]
1
2
|
rfm_melted = pd.melt(frame= rfm_scaled, id_vars= ['CustomerID', 'Label'], \
var_name = 'Metrics', value_name = 'Value')
|
#> CustomerID Label Metrics Value
#> 0 12346 Low Recency 1.389971
#> 1 15098 Medium Recency 0.996792
#> 2 16029 High Recency -0.064790
#> 3 17450 High Recency -1.121628
#> 4 17949 High Recency -2.530970
#> ... ... ... ... ...
#> 11758 15311 High Monetary 2.967380
#> 11759 16013 High Monetary 3.836427
#> 11760 16422 High Monetary 2.977145
#> 11761 17841 High Monetary 2.165383
#> 11762 16446 High Monetary 5.296556
#>
#> [11763 rows x 4 columns]
Visualisasi behavior customer pada setiap level.
1
2
3
4
5
6
7
|
import seaborn as sns
# a snake plot with RFM
sns.lineplot(x = 'Metrics', y = 'Value', hue = 'Label', data = rfm_melted)
plt.title('Customer Behavior based on their Label')
plt.legend(loc = 'upper right')
plt.show()
|
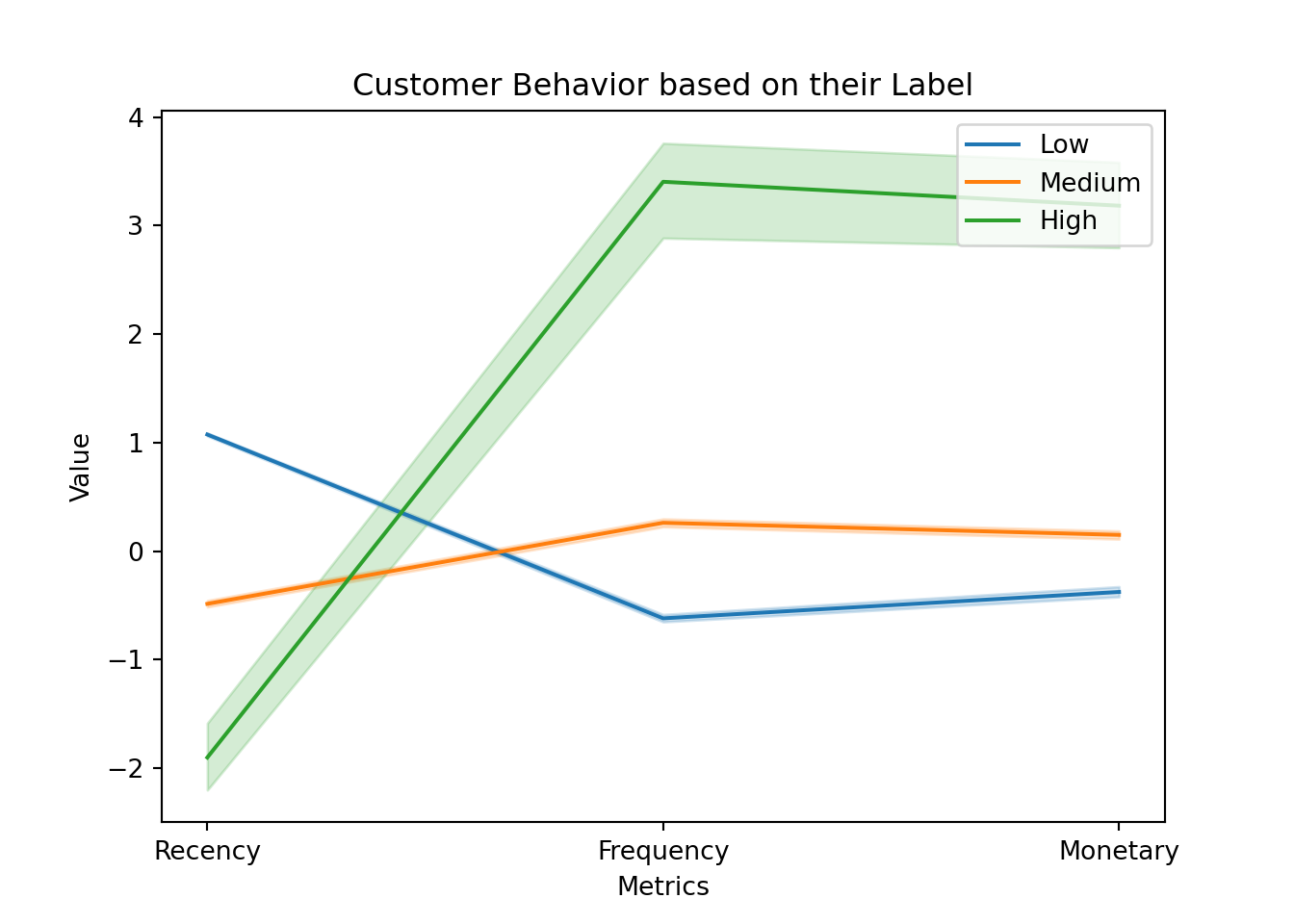
Berdasarkan visualisasi di atas diperoleh detail informasi bahwa :
- Customer dengan
high-value labels memiliki kecenderungan untuk menghabiskan banyak uang dalam berbelanja (high monetary) dan sering melakukan pembelanjaan (high frequency)
- Customer dengan
medium-value labels tidak terlalu sering melakukan pembelian dan juga tidak banyak menghabiskan uang selama transaksi.
- Customer dengan
low-value labels hanya menghabiskan sedikit uang selama berbelanja, tidak terlalu sering berbelanja, tetapi memiliki nilai recency yang cukup tinggi dibandingkan level lainnya.
Berdasarkan rules di atas, pihak management dapat mempertimbangkan melakukan strategi marketing dengan cara :
- Memberikan special promotion atau discount untuk
low-value customer yang baru-baru saja berkunjung untuk berbelanja, sehingga mereka tertarik untuk berbelanja lagi di lain waktu.
- Mempertahankan
medium-value customer dengan cara memberikan cashback pada pembeliannya.
- Memberikan reward pada loyal customer (
high-value) dengan cara memberikan free product atau cashback pada pembelanjaannya.
Conclusion
RFM analysis adalah teknik yang umum digunakan untuk melakukan segmentasi terhadap customer berdasarkan value dan behavior selama bertransaksi. Teknik ini sangat membantu pihak management khususnya marketing team dalam menentukan strategi bisnis yang cocok untuk mempertahankan loyal customer dan menarik customer baru.
