Retail
Feature Recommendation on Mobile Games
Background
Dalam suatu proses bisnis, pemberian fasilitas atau fitur produk yang sesuai dengan kebutuhan dan kenyamanan user atau customer adalah hal yang penting untuk diperhatikan. Salah satu cara untuk mengetahui minat user adalah dengan melakukan A/B Testing. Di A/B Testing, terdapat 2 grup A dan B yang diberikan perlakuan yang berbeda yang kemudian akan dibandingkan performansi dari masing-masing grup.
Pada artikel ini, digunakan data dari kaggle (https://www.kaggle.com/yufengsui/mobile-games-ab-testing) untuk melakukan proses A/B Testing. Data ini berisi tentang perilaku user pada Mobile Games yang berjudul Cookie Cats. Cookie Cats merupakan permainan populer yang dikembangkan oleh Tactile Entertainment.
Pada saat pemain melalui level-level dalam game, mereka terkadang akan menemukan gate yang memaksa mereka untuk menunggu waktu tertentu atau melakukan pembelian dalam aplikasi untuk melanjutkan permainan. Selain mendorong pembelian dalam aplikasi, gate ini juga memiliki tujuan untuk memberikan pemain istirahat dari bermain game. Sehingga dapat meningkatkan dan memperpanjang kenyamanan pemain dalam bermain game.
Nah, tetapi di manakah gate itu perlu ditempatkan? Pada awalnya, gate ditempatkan di level 30. Akan tetapi perusahaan akan mencoba untuk melakukan pemindahan gate tersebut di Cookie Cats dari level 30 ke level 40. Untuk melakukan eksperimen tersebut, perusahaan memutuskan melakukan A/B Testing dan melakukan analisis apakah pemindahan tersebut berpengaruh pada kenyamanan pemain atau tidak.
Data Preparation
Sebelum melakukan pemodelan, perlu dilakukan persiapan data. Data yang dipersiapkan dipastikan telah memiliki kualitas yang baik agara model yang dibangun nantinya juga model yang baik.
1
2
3
|
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
|
1
|
df=pd.read_csv('cookie_cats.csv')
|
1
2
3
4
5
6
|
#> userid version sum_gamerounds retention_1 retention_7
#> 0 116 gate_30 3 False False
#> 1 337 gate_30 38 True False
#> 2 377 gate_40 165 True False
#> 3 483 gate_40 1 False False
#> 4 488 gate_40 179 True True
|
Data ini diambil dari 90.189 pemain yang melakukan instalasi pada game pada saat A/B Testing dijalankan.
Variabel-variabelnya adalah :
- userid - nomor unik yang mengidentifikasikan setiap pemain.
- version - kategori apakah pemain diletakkan di the control group (gate_30 - a gate at level 30) atau di grup dengan gate yang berpindah (gate_40 - a gate at level 40).
- sum_gamerounds - banyaknya ronde permainan yang dimainkan pemain selama 14 hari pertama setelah instalasi.
- retention_1 - apakah pemain datang kembali dan main pada saat 1 hari setelah melakukan instalasi?
- retention_7 - apakah pemain datang kembali dan main pada saat 7 hari setelah melakukan instalasi?
Exploratory Data Analysis
Mari melakukan eksplorasi pada data yang kita punya untuk lebih memahaminya!
1
2
3
|
# EDA
df.groupby("version")['sum_gamerounds'].agg(["min", "max", pd.Series.mode, "median", "mean", "std", "count"])
|
1
2
3
4
|
#> min max mode median mean std count
#> version
#> gate_30 0 49854 1 17.0 52.456264 256.716423 44700
#> gate_40 0 2640 1 16.0 51.298776 103.294416 45489
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#memeriksa ilustrasi distribusi data
def plot_distribution(dataframe):
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
sns.histplot(dataframe, x="sum_gamerounds", label='histogram', multiple="dodge", hue="version",
shrink=.8, binwidth=10, ax=axes[0])
sns.boxplot(x=dataframe['version'], y=dataframe['sum_gamerounds'], ax=axes[1])
axes[0].set_xlim(0, 200)
axes[1].set_yscale('log')
axes[0].set_title('Distribution histogram', fontsize=14)
axes[1].set_title('Distribution version', fontsize=14)
plt.show()
|
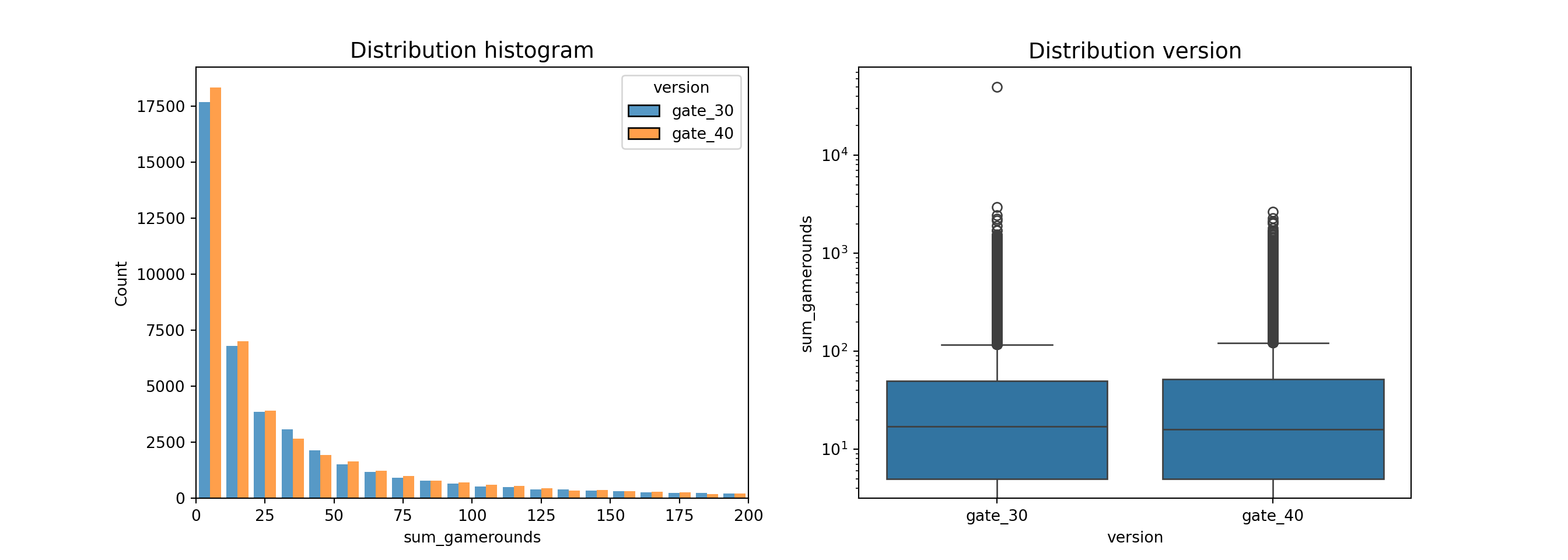
Dari summary dan visualisasi data, dapat dilihat bahwa rataan dan distribusi banyaknya ronde permainan yang dimainkan pemain selama 14 hari pertama setelah instalasi pada gate_30 dan gate_40 diduga hampir sama.
Modeling
A/B Testing
Sejauh ini, ada 2 tipe A/B Testing yang sering digunakan.
- Tradisional Statistika : menggunakan uji hipotesis signifikansi rataan
- Bayesian A/B Testing : menggunakan prinsip bayesian
Dalam artikel ini, akan digunakan 2 metode itu untuk analisis
Traditional Statistics
Dalam model ini, digunakan kolom sum_gamerounds pada data.
1
2
|
A = df[df['version'] == "gate_30"]['sum_gamerounds']
B = df[df['version'] == "gate_40"]['sum_gamerounds']
|
Uji Normalitas
Sebelum menentukan jenis metode yang digunakan dalam A/B Testing secara tradisional, akan dilakukan uji normalitas. Uji ini digunakan untuk memeriksa jenis distribusi dari data. Dalam hal ini dilakukan uji Saphiro-Wilk dengan hipotesis nol adalah data berdistribusi normal sedanglkan hipotesis alternatifnya adalah data tidak berdistribusi normal.
1
2
3
4
|
#Cek Asumsi
from scipy.stats import shapiro
import scipy.stats as stats
shapiro(A)
|
1
|
#> ShapiroResult(statistic=0.08805022308043553, pvalue=2.146395844442685e-157)
|
1
|
#> ShapiroResult(statistic=0.482561004889815, pvalue=3.3446548187520663e-140)
|
Didapatkan nilai pvalue sangat kecil dan kurang dari 0.05 (batas signifikansi yang ditentukan). Maka hipotesis nol ditolak. Artinya, data tidak berdistribusi normal.
Karena data tidak berdistribusi normal, kemudia untuk menghindari asumsi distribusi, digunakan uji non-parameterik ‘Mann Whitney-U’
Uji Hipotesis
Dalam Mann Whitney-U, hipotesis nolnya adalah 2 populasi sama dan hipotesis alternatifnya adalah dua populasi tidak sama.
1
2
|
_, pvalue = stats.mannwhitneyu(A, B)
pvalue
|
Didapatkan p-value kurang dari 0.05. Artinya, hipotesis nol ditolak. Dua populasi tersebut tidak sama. Namun sampai sejauh ini, kita belum dapat menentukan mana populasi yang lebih baik.
Bayesian A/B Testing
Bayesian A/B Testing menggunakan metode inferensi bayesian yang memberikan peluang seberapa baik/buruk grup A dari pada grup B. Dalam model ini digunakan kolom retention_1 pada data.
1
|
#> WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
|
1
2
3
4
5
6
7
|
N_A = 44700
N_B = 45489
observations_A = df[df['version'] == 'gate_30']['retention_1'].values.astype(int)
observations_B = df[df['version'] == 'gate_40']['retention_1'].values.astype(int)
print('Banyaknya user yang kembali setelah 1 hari di grup A:', observations_A.sum())
|
1
|
#> Banyaknya user yang kembali setelah 1 hari di grup A: 20034
|
1
|
print('Banyaknya user yang kembali setelah 1 hari di grup B:', observations_B.sum())
|
1
|
#> Banyaknya user yang kembali setelah 1 hari di grup B: 20119
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#Bayesian
true_p_A = 0.448188
true_p_B = 0.442283
with pm.Model() as model:
p_A = pm.Beta("p_A", 11, 14)
p_B = pm.Beta("p_B", 11, 14)
delta = pm.Deterministic("delta", p_A - p_B)
obs_A = pm.Bernoulli("obs_A", p_A, observed=observations_A)
obs_B = pm.Bernoulli("obs_B", p_B, observed=observations_B)
step = pm.Metropolis()
trace = pm.sample(200, step=step, return_inferencedata=False)
burned_trace=trace[10:]
|
1
2
3
4
5
6
7
8
9
|
#> Sampling 4 chains, 0 divergences ----------------------- 100% 0:00:00 / 0:00:05
#>
#> Multiprocess sampling (4 chains in 4 jobs)
#> CompoundStep
#> >Metropolis: [p_A]
#> >Metropolis: [p_B]
#> Sampling 4 chains for 1_000 tune and 200 draw iterations (4_000 + 800 draws total) took 19 seconds.
#> The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
#> The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
|
1
2
3
|
p_A_samples = burned_trace["p_A"]
p_B_samples = burned_trace["p_B"]
delta_samples = burned_trace["delta"]
|
1
|
plt.figure(figsize=(12.5, 10))
|
1
|
#> <Figure size 1250x1000 with 0 Axes>
|
1
2
3
4
5
6
7
8
9
|
from IPython.core.pylabtools import figsize
figsize(12.5, 10)
ax = plt.subplot(311)
plt.hist(p_A_samples, histtype='stepfilled', bins=25, alpha=0.85,
label="posterior of $p_A$", color="#A60628", density=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#> (array([ 19.48218154, 7.30581808, 38.96436307, 2.43527269,
#> 29.2232723 , 36.52909038, 150.9869069 , 38.96436307,
#> 155.85745228, 77.92872614, 26.78799961, 250.83308727,
#> 148.55163421, 199.69236074, 119.3283619 , 80.36399883,
#> 116.89308921, 146.11636151, 51.14072653, 19.48218154,
#> 41.39963576, 41.39963576, 43.83490845, 0. ,
#> 7.30581808]), array([0.44127548, 0.44181578, 0.44235609, 0.44289639, 0.4434367 ,
#> 0.443977 , 0.4445173 , 0.44505761, 0.44559791, 0.44613822,
#> 0.44667852, 0.44721883, 0.44775913, 0.44829944, 0.44883974,
#> 0.44938005, 0.44992035, 0.45046066, 0.45100096, 0.45154127,
#> 0.45208157, 0.45262188, 0.45316218, 0.45370249, 0.45424279,
#> 0.4547831 ]), [<matplotlib.patches.Polygon object at 0x00000274F835CD10>])
|
1
|
plt.vlines(true_p_A, 0, 80, linestyle="--", label="true $p_A$ (unknown)")
|
1
|
#> <matplotlib.collections.LineCollection object at 0x00000274F8359E50>
|
1
|
plt.legend(loc="upper right")
|
1
|
#> <matplotlib.legend.Legend object at 0x00000274F81AB990>
|
1
|
plt.title("Posterior distributions of $p_A$, $p_B$, and delta unknowns")
|
1
|
#> Text(0.5, 1.0, 'Posterior distributions of $p_A$, $p_B$, and delta unknowns')
|
1
2
3
4
|
ax = plt.subplot(312)
plt.hist(p_B_samples, histtype='stepfilled', bins=25, alpha=0.85,
label="posterior of $p_B$", color="#467821", density=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#> (array([ 13.38184816, 48.17465339, 2.67636963, 0. ,
#> 13.38184816, 53.52739266, 90.99656752, 125.78937274,
#> 123.11300311, 136.49485128, 208.75683136, 184.66950467,
#> 131.14211201, 136.49485128, 144.52396017, 232.84415806,
#> 173.96402614, 66.90924082, 29.44006596, 45.49828376,
#> 24.0873267 , 10.70547853, 0. , 29.44006596,
#> 8.0291089 ]), array([0.43610199, 0.43659362, 0.43708525, 0.43757688, 0.43806852,
#> 0.43856015, 0.43905178, 0.43954341, 0.44003504, 0.44052668,
#> 0.44101831, 0.44150994, 0.44200157, 0.44249321, 0.44298484,
#> 0.44347647, 0.4439681 , 0.44445973, 0.44495137, 0.445443 ,
#> 0.44593463, 0.44642626, 0.44691789, 0.44740953, 0.44790116,
#> 0.44839279]), [<matplotlib.patches.Polygon object at 0x00000274F81FB250>])
|
1
|
plt.vlines(true_p_B, 0, 80, linestyle="--", label="true $p_B$ (unknown)")
|
1
|
#> <matplotlib.collections.LineCollection object at 0x00000274F85B4B90>
|
1
|
plt.legend(loc="upper right")
|
1
|
#> <matplotlib.legend.Legend object at 0x00000274F7825E50>
|
1
2
3
|
ax = plt.subplot(313)
plt.hist(delta_samples, histtype='stepfilled', bins=30, alpha=0.85,
label="posterior of delta", color="#7A68A6", density=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#> (array([ 1.90715987, 0. , 1.90715987, 1.90715987,
#> 0. , 17.16443882, 22.88591843, 34.32887764,
#> 24.7930783 , 26.70023817, 55.3076362 , 24.7930783 ,
#> 97.26515332, 146.85130991, 167.83006847, 93.45083358,
#> 62.93627568, 68.65775528, 120.15107175, 137.31551057,
#> 87.72935397, 82.00787437, 41.95751712, 45.77183686,
#> 45.77183686, 7.62863948, 9.53579934, 11.44295921,
#> 9.53579934, 1.90715987]), array([-0.00538879, -0.00469887, -0.00400895, -0.00331902, -0.0026291 ,
#> -0.00193918, -0.00124926, -0.00055934, 0.00013058, 0.0008205 ,
#> 0.00151042, 0.00220034, 0.00289026, 0.00358018, 0.00427011,
#> 0.00496003, 0.00564995, 0.00633987, 0.00702979, 0.00771971,
#> 0.00840963, 0.00909955, 0.00978947, 0.01047939, 0.01116931,
#> 0.01185924, 0.01254916, 0.01323908, 0.013929 , 0.01461892,
#> 0.01530884]), [<matplotlib.patches.Polygon object at 0x00000274F8434D10>])
|
1
2
|
plt.vlines(true_p_A - true_p_B, 0, 60, linestyle="--",
label="true delta (unknown)")
|
1
|
#> <matplotlib.collections.LineCollection object at 0x00000274F846A650>
|
1
|
plt.vlines(0, 0, 60, color="black", alpha=0.2)
|
1
|
#> <matplotlib.collections.LineCollection object at 0x00000274F846B310>
|
1
|
plt.legend(loc="upper right")
|
1
|
#> <matplotlib.legend.Legend object at 0x00000274F85B5E50>
|
1
2
3
4
|
import numpy as np
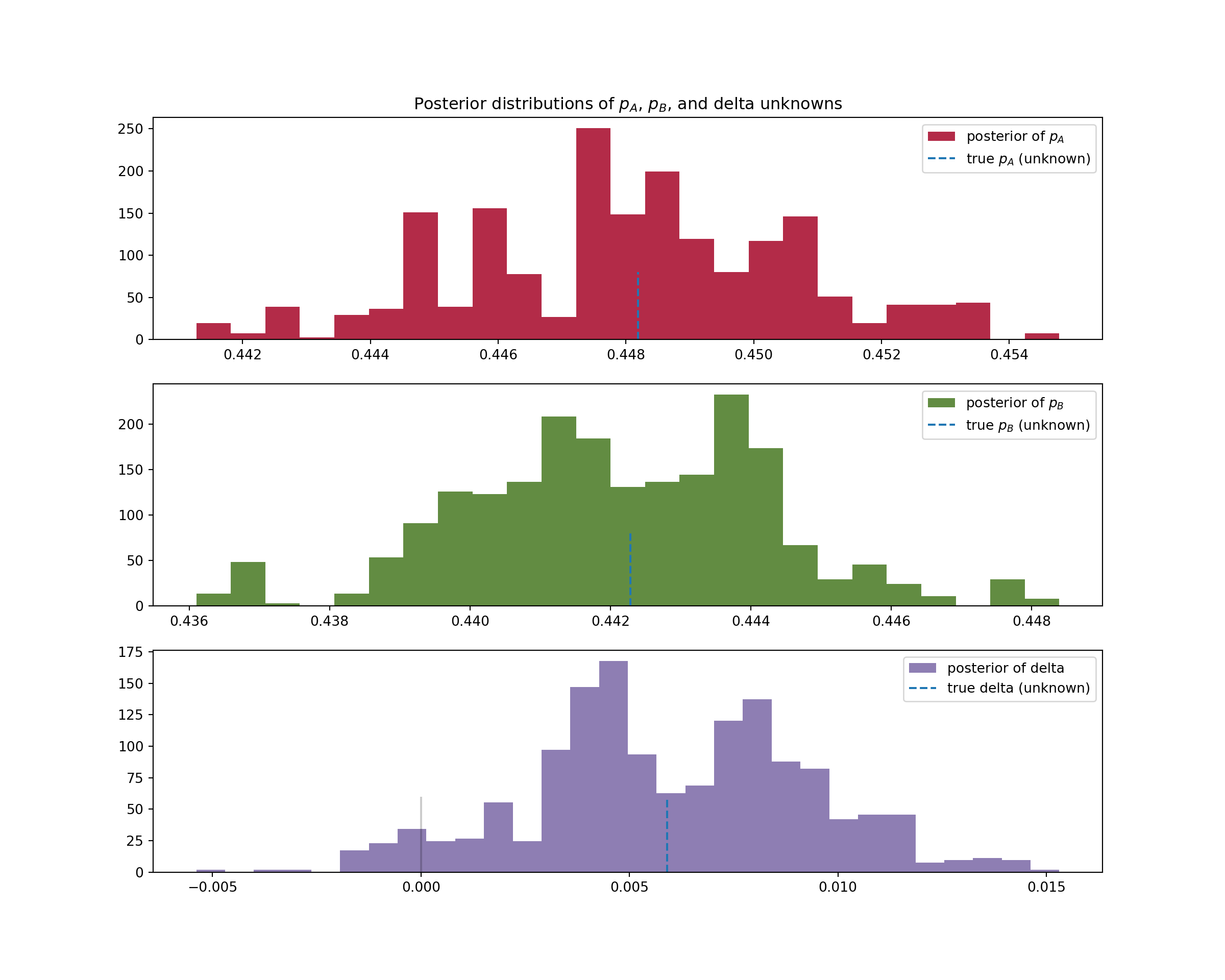
print("Peluang grup A lebih buruk dari grup B: %.3f" % \
np.mean(delta_samples < 0))
|
1
|
#> Peluang grup A lebih buruk dari grup B: 0.042
|
1
2
|
print("Peluang grup A lebih baik dari grup B: %.3f" % \
np.mean(delta_samples > 0))
|
1
|
#> Peluang grup A lebih baik dari grup B: 0.958
|
Conclusion
Setelah melakukan A/B Testing dengan tradisional stastitik (Mann Whitney-U), didapatkan bahwa gate_30 dan gate_40 adalah dua populasi yang tidak sama. Setelah menggunakan A/B Testing dengan Bayesian, didapatkan bahwa gate_30 lebih baik dari gate_40. Artinya, perusahaan tidak perlu memindahkan gate ke level 40 dan tetap meletakkan gate di level 30.
