Finance
Credit Risk Analysis
Background
Credit scoring merupakan sistem yang digunakan oleh bank atau lembaga keuangan lain untuk menentukan apakah seorang nasabah layak atau tidak mendapatkan pinjaman. Credit scoring membutuhkan berbagai data profil calon peminjam sehingga tingkat resiko dapat dihitung dengan tepat. Semakin tepat dan lengkap data yang disediakan, maka semakin akurat perhitungan yang dilakukan.
Proses tersebut tentunya merupakan hal yang baik, namun di sisi calon peminjam proses yang harus dilalui dirasa sangat merepotkan dan membutuhkan waktu untuk menunggu dan seiring tingginya tingkat kompetisi yang ada di industri finansial, menjadikan nasabah memiliki banyak alternatif. Semakin cepat proses yang ditawarkan, semakin tinggi kesempatan untuk mendapatkan peminjam.
Tantangan pun muncul, bagaimana mendapatkan peminjam dengan proses yang efisien namun akurasi dari credit scoring tetap tinggi. Disinilah machine learning dapat membantu menganalisa data-data profil peminjam dan proses pembayaran sehingga dapat mengetahui profil peminjam yang memiliki peluang besar untuk melunasi pinjaman dengan lancar.
Harapannya setelah mempunyai model machine learning dengan perfomance model yang baik, pegawai bank dapat dengan mudah mengidentifikasi karakteristik customer yang memiliki peluang besar untuk melunasi pinjaman dengan lancar. Dengan adanya model machine learning ini tentunya akan mengurangi biaya dan waktu yang lebih cepat.
Modelling Analysis
Cleaning data
1
2
|
credit <- read_csv("credit_record.csv")
application <- read_csv("application_record.csv")
|
Data Description:
Credit
ID : Client numberMONTHS_BALANCE : Record month The month of the extracted data is the starting point, backwards, 0 is the current month, -1 is the previous month, and so onSTATUS : Status
- 0: 1-29 days past due
- 1: 30-59 days past due
- 2: 60-89 days overdue
- 3: 90-119 days overdue
- 4: 120-149 days overdue
- 5: Overdue or bad debts, write-offs for more than 150 days
- C: paid off that month
- X: No loan for the month
Application
ID : Client numberCODE_GENDER : GenderFLAG_OWN_CAR : Is there a carFLAG_OWN_REALTY ; Is there a propertyCNT_CHILDREN : Number of childrenAMT_INCOME_TOTAL : Annual incomeNAME_INCOME_TYPE : Income categoryNAME_EDUCATION_TYPE : Education levelNAME_FAMILY_STATUS : Marital statusNAME_HOUSING_TYPE : Way of livingDAYS_BIRTH : Birthday Count backwards from current day (0), -1 means yesterdayDAYS_EMPLOYED : Start date of employment Count backwards from current day(0). If positive, it means - - the person currently unemployed.FLAG_MOBIL : Is there a mobile phoneFLAG_WORK_PHONE : Is there a work phoneFLAG_PHONE : Is there a phoneFLAG_EMAIL : Is there an emailOCCUPATION_TYPE : OccupationCNT_FAM_MEMBERS :Family size
Check missing values
Pada data credit tidak terdapat missing value
1
2
|
#> ID MONTHS_BALANCE STATUS
#> 0 0 0
|
1
|
colSums(is.na(application))
|
1
2
3
4
5
6
7
8
9
10
|
#> ID CODE_GENDER FLAG_OWN_CAR FLAG_OWN_REALTY
#> 0 0 0 0
#> CNT_CHILDREN AMT_INCOME_TOTAL NAME_INCOME_TYPE NAME_EDUCATION_TYPE
#> 0 0 0 0
#> NAME_FAMILY_STATUS NAME_HOUSING_TYPE DAYS_BIRTH DAYS_EMPLOYED
#> 0 0 0 0
#> FLAG_MOBIL FLAG_WORK_PHONE FLAG_PHONE FLAG_EMAIL
#> 0 0 0 0
#> OCCUPATION_TYPE CNT_FAM_MEMBERS
#> 134203 0
|
Pada data application terdapat variabel OCCUPATION_TYPE yang memiliki banyak data missing, kita dapat membuang variabel tersebut. Serta kita akan membuang variabel DAYS_BIRTH dan DAYS_EMPLOYED yang tidak dibutuhkan pada model.
1
2
|
application <- application %>%
select(-c(OCCUPATION_TYPE, DAYS_BIRTH, DAYS_EMPLOYED))
|
Menyesuaikan tipe data
Tahap berikutnya adalah menggabungkan data credit dan application serta menyesuaikan tipe data kategorik yang masih terbaca sebagai character.
1
2
3
4
5
6
7
8
9
10
11
|
data_clean <- credit %>%
left_join(application) %>%
na.omit() %>%
select(-ID) %>%
filter(STATUS != "X") %>%
mutate(STATUS = as.factor(ifelse(STATUS == "C", "good credit", "bad credit"))) %>%
mutate_at(.vars = c("FLAG_MOBIL", "FLAG_WORK_PHONE",
"FLAG_PHONE", "FLAG_EMAIL"), as.factor) %>%
mutate_if(is.character, as.factor) %>%
data.frame()
str(data_clean)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#> 'data.frame': 631765 obs. of 16 variables:
#> $ MONTHS_BALANCE : num 0 -1 -2 -3 -4 -5 -6 -7 -8 -9 ...
#> $ STATUS : Factor w/ 2 levels "bad credit","good credit": 2 2 2 2 2 2 2 2 2 2 ...
#> $ CODE_GENDER : Factor w/ 2 levels "F","M": 2 2 2 2 2 2 2 2 2 2 ...
#> $ FLAG_OWN_CAR : Factor w/ 2 levels "N","Y": 2 2 2 2 2 2 2 2 2 2 ...
#> $ FLAG_OWN_REALTY : Factor w/ 2 levels "N","Y": 2 2 2 2 2 2 2 2 2 2 ...
#> $ CNT_CHILDREN : num 0 0 0 0 0 0 0 0 0 0 ...
#> $ AMT_INCOME_TOTAL : num 427500 427500 427500 427500 427500 ...
#> $ NAME_INCOME_TYPE : Factor w/ 5 levels "Commercial associate",..: 5 5 5 5 5 5 5 5 5 5 ...
#> $ NAME_EDUCATION_TYPE: Factor w/ 5 levels "Academic degree",..: 2 2 2 2 2 2 2 2 2 2 ...
#> $ NAME_FAMILY_STATUS : Factor w/ 5 levels "Civil marriage",..: 1 1 1 1 1 1 1 1 1 1 ...
#> $ NAME_HOUSING_TYPE : Factor w/ 6 levels "Co-op apartment",..: 5 5 5 5 5 5 5 5 5 5 ...
#> $ FLAG_MOBIL : Factor w/ 1 level "1": 1 1 1 1 1 1 1 1 1 1 ...
#> $ FLAG_WORK_PHONE : Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 2 2 2 ...
#> $ FLAG_PHONE : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
#> $ FLAG_EMAIL : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 1 1 1 ...
#> $ CNT_FAM_MEMBERS : num 2 2 2 2 2 2 2 2 2 2 ...
|
Exploratory Data Analysis (EDA)
Pada data EDA kita ingin mengetahui bagaimana sebaran data kategorik maupun numerik.
1
|
data_clean %>% inspect_cat() %>% show_plot()
|
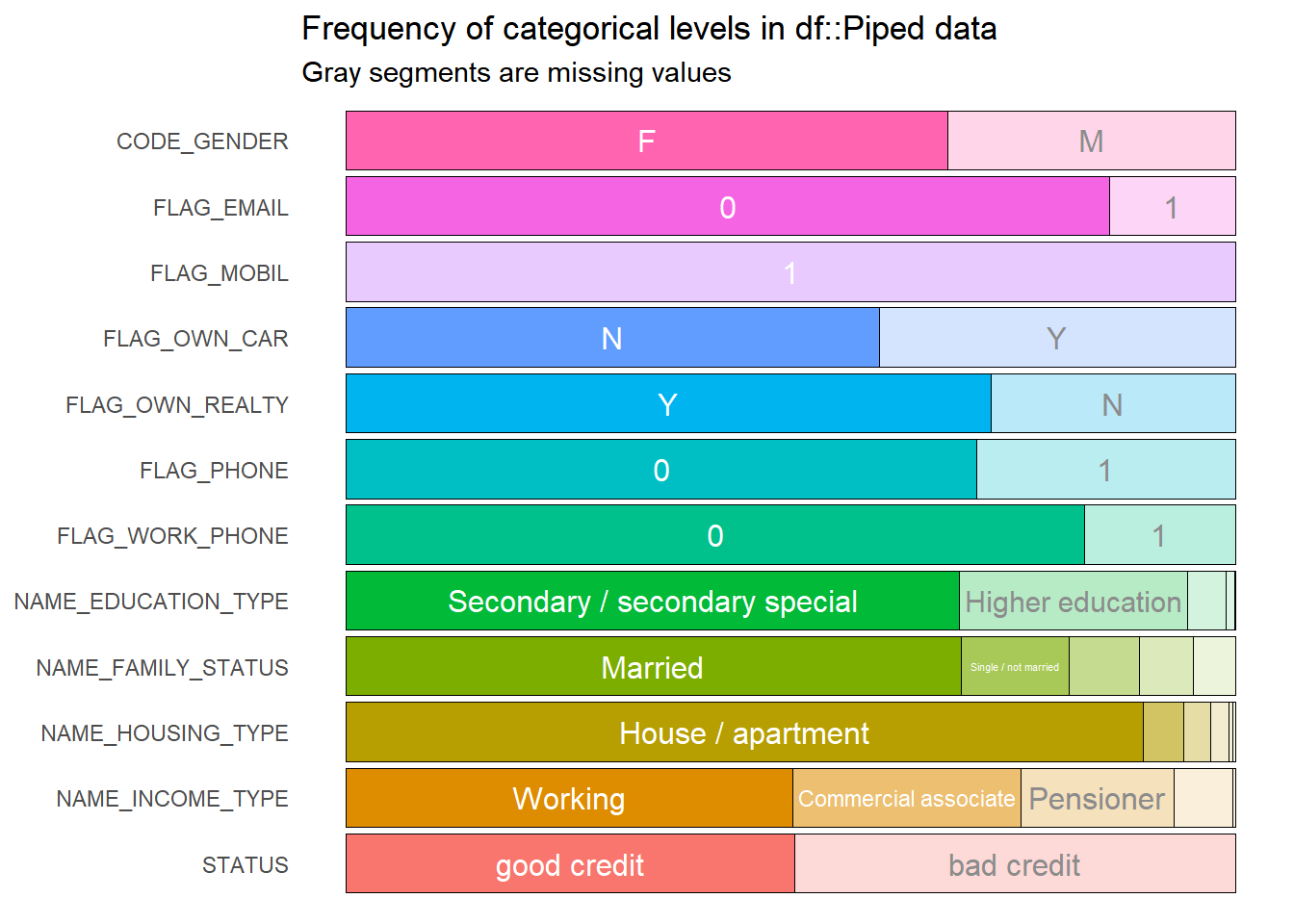 Pada visualisasi berikut kita akan mendapatkan informasi apakah terdapat variabel yang tidak memiliki banyak informasi pada data, contohnya adalah variabel `FLAG_MOBIL` dimana keseluruhan data berisikan 1, artinya semua nasabah kita yang melakukan pinjaman memiliki mobil. Data yang tidak memiliki variansi seperti ini tidak diikutsertakan pada model.
Pada visualisasi berikut kita akan mendapatkan informasi apakah terdapat variabel yang tidak memiliki banyak informasi pada data, contohnya adalah variabel `FLAG_MOBIL` dimana keseluruhan data berisikan 1, artinya semua nasabah kita yang melakukan pinjaman memiliki mobil. Data yang tidak memiliki variansi seperti ini tidak diikutsertakan pada model.
1
2
|
data_clean <- data_clean %>%
select(-c(FLAG_MOBIL,FLAG_EMAIL))
|
1
|
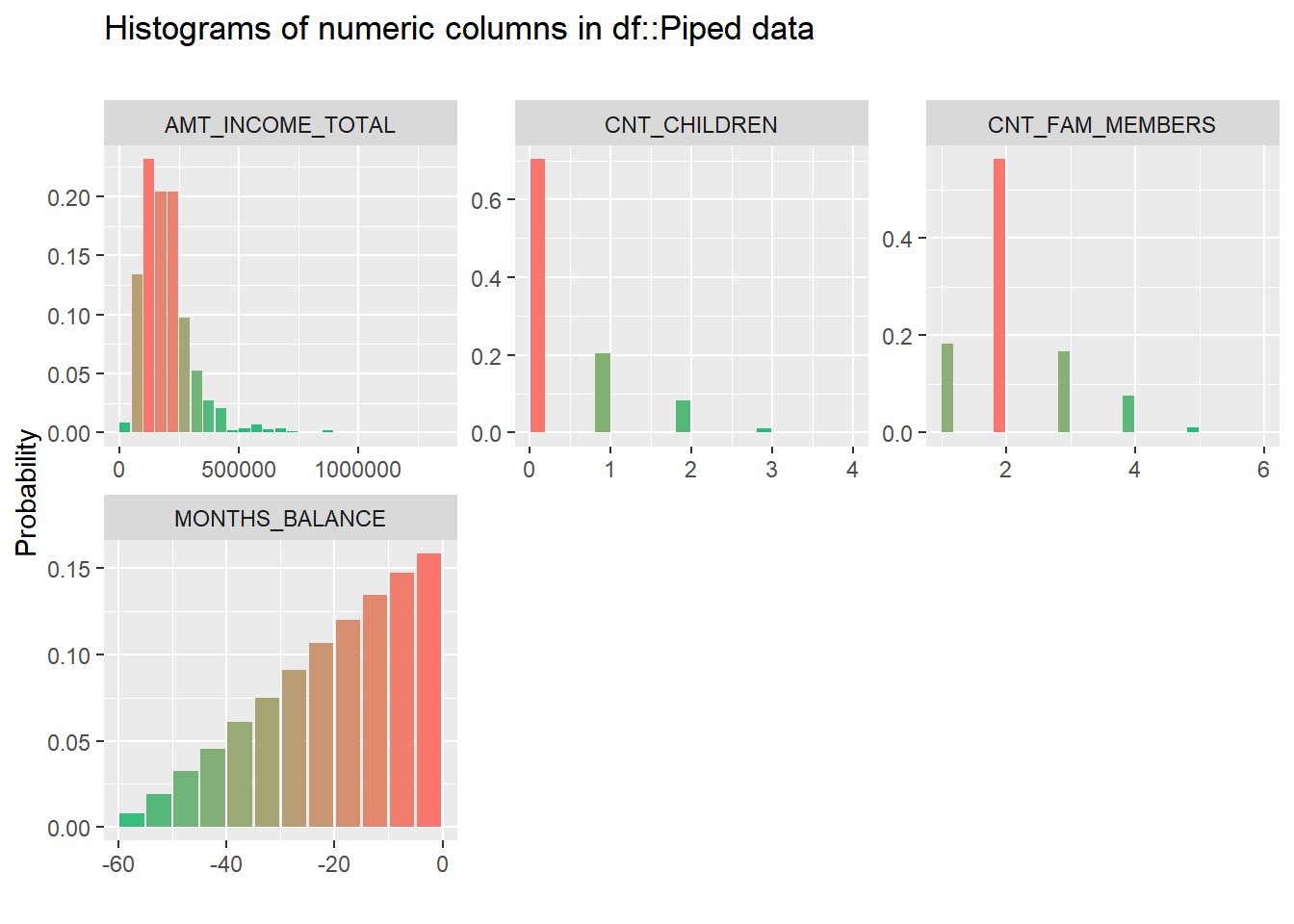
data_clean %>% inspect_num() %>% show_plot()
|
Modelling Random Forest
Split data train dan data test dengan proporsi 80:20. Data train akan digunakan untuk modelling, sedangkan data test akan digunakan untuk evaluasi.
1
2
3
4
|
set.seed(100)
index <- initial_split(data = data_clean, prop = 0.8, strata = "STATUS")
train <- training(index)
test <- testing(index)
|
Cek proporsi dari target variabel
1
|
prop.table(table(train$STATUS))
|
1
2
3
|
#>
#> bad credit good credit
#> 0.4960937 0.5039063
|
Bentuk model random forest dengan 3 k-fold dan 2 repetition
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# set.seed(100)
#
# ctrl <- trainControl(method = "repeatedcv",
# number = 3,
# repeats = 2,
# allowParallel=FALSE)
#
# model_forest <- caret::train(STATUS ~.,
# data = train,
# method = "rf",
# trControl = ctrl)
#saveRDS(model_forest, "model_forest.RDS")
model_forest <- readRDS("model_forest.RDS")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#> Random Forest
#>
#> 80001 samples
#> 13 predictor
#> 2 classes: 'bad credit', 'good credit'
#>
#> No pre-processing
#> Resampling: Cross-Validated (3 fold, repeated 2 times)
#> Summary of sample sizes: 53335, 53334, 53333, 53334, 53334, 53334, ...
#> Resampling results across tuning parameters:
#>
#> mtry Accuracy Kappa
#> 2 0.6432232 0.2846367
#> 14 0.7487656 0.4973803
#> 26 0.7114411 0.4230518
#>
#> Accuracy was used to select the optimal model using the largest value.
#> The final value used for the model was mtry = 14.
|
Setelah dilakukan 3 repetition pada model, repetition kedua memiliki accuracy paling tinggi dengan jumlah mtry sebanyak 14.
Selanjutnya akan dilakukan prediksi untuk data test dan mencari nilai confusion matrix pada hasil prediksi.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
pred_rf <- predict(model_forest, newdata = test, type = "prob") %>%
mutate(result = as.factor(ifelse(`bad credit` > 0.45, "bad credit", "good credit")),
actual = ifelse(test$STATUS == 'good credit', 0, 1))
confmat_rf <- confusionMatrix(pred_rf$result,
test$STATUS,
mode = "prec_recall",
positive = "bad credit")
eval_rf <- tidy(confmat_rf) %>%
mutate(model = "Random Forest") %>%
select(model, term, estimate) %>%
filter(term %in% c("accuracy", "precision", "recall", "specificity"))
eval_rf
|
1
2
3
4
5
6
7
|
#> # A tibble: 4 × 3
#> model term estimate
#> <chr> <chr> <dbl>
#> 1 Random Forest accuracy 0.812
#> 2 Random Forest specificity 0.815
#> 3 Random Forest precision 0.811
#> 4 Random Forest recall 0.809
|
Modelling XGBoost
Tahap selanjutnya kita akan implementasikan data menggunakan model XGBoost, kita perlu menyiapkan data untuk model XGBoost terlebih dahulu
1
2
3
|
data_xgb <- data_clean %>%
mutate(STATUS = ifelse(STATUS == "good credit", 0, 1)) %>%
data.frame()
|
1
2
3
4
|
set.seed(100)
index <- initial_split(data = data_xgb, prop = 0.8, strata = "STATUS")
train_xgb <- training(index)
test_xgb <- testing(index)
|
1
2
|
label_train <- as.numeric(train_xgb$STATUS)
label_test <- as.numeric(test_xgb$STATUS)
|
1
2
3
4
5
|
train_matrix <- data.matrix(train_xgb[,-2])
test_matrix <- data.matrix(test_xgb[,-2])
# convert data to Dmatrix
dtrain <- xgb.DMatrix(data = train_matrix, label = label_train)
dtest <- xgb.DMatrix(data = test_matrix, label = label_test)
|
1
2
3
4
5
6
7
8
|
params <- list(booster = "gbtree",
objective = "binary:logistic",
eta=0.7,
gamma=10,
max_depth=10,
min_child_weight=3,
subsample=1,
colsample_bytree=0.5)
|
1
2
3
4
5
6
7
8
9
|
xgbcv <- xgb.cv( params = params,
data = dtrain,
nrounds = 1000,
showsd = T,
nfold = 10,
stratified = T,
print_every_n = 50,
early_stopping_rounds = 20,
maximize = F)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#> [1] train-logloss:0.658662+0.007933 test-logloss:0.661058+0.006557
#> Multiple eval metrics are present. Will use test_logloss for early stopping.
#> Will train until test_logloss hasn't improved in 20 rounds.
#>
#> [51] train-logloss:0.499070+0.002877 test-logloss:0.522102+0.005311
#> [101] train-logloss:0.484907+0.002400 test-logloss:0.511246+0.005861
#> [151] train-logloss:0.479035+0.002541 test-logloss:0.506482+0.006336
#> [201] train-logloss:0.475424+0.001885 test-logloss:0.503721+0.005527
#> [251] train-logloss:0.472145+0.001382 test-logloss:0.501116+0.004776
#> [301] train-logloss:0.469895+0.000887 test-logloss:0.499619+0.004786
#> [351] train-logloss:0.468053+0.000621 test-logloss:0.498204+0.004675
#> [401] train-logloss:0.466677+0.000615 test-logloss:0.497064+0.004712
#> [451] train-logloss:0.465230+0.001051 test-logloss:0.495919+0.004776
#> [501] train-logloss:0.463936+0.001203 test-logloss:0.495003+0.004136
#> [551] train-logloss:0.462722+0.001080 test-logloss:0.494104+0.004121
#> [601] train-logloss:0.462171+0.001191 test-logloss:0.493726+0.004162
#> [651] train-logloss:0.461517+0.001091 test-logloss:0.493349+0.004292
#> [701] train-logloss:0.461138+0.001122 test-logloss:0.493079+0.004226
#> [751] train-logloss:0.460702+0.001232 test-logloss:0.492759+0.004191
#> [801] train-logloss:0.460177+0.001332 test-logloss:0.492256+0.004187
#> [851] train-logloss:0.459702+0.000982 test-logloss:0.491947+0.004133
#> [901] train-logloss:0.459231+0.000911 test-logloss:0.491621+0.004155
#> [951] train-logloss:0.458708+0.000952 test-logloss:0.491276+0.004243
#> [1000] train-logloss:0.458331+0.001051 test-logloss:0.491019+0.004244
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
#> ##### xgb.cv 10-folds
#> iter train_logloss_mean train_logloss_std test_logloss_mean
#> 1 0.6586617 0.007932747 0.6610580
#> 2 0.6261109 0.014786739 0.6318969
#> 3 0.6127767 0.018208261 0.6200069
#> 4 0.5954663 0.014391087 0.6041849
#> 5 0.5854660 0.014752739 0.5949785
#> ---
#> 996 0.4583978 0.001032491 0.4910331
#> 997 0.4583400 0.001056519 0.4910225
#> 998 0.4583307 0.001051172 0.4910193
#> 999 0.4583307 0.001051173 0.4910193
#> 1000 0.4583307 0.001051172 0.4910193
#> test_logloss_std
#> 0.006557291
#> 0.013925367
#> 0.017604226
#> 0.014605105
#> 0.013268623
#> ---
#> 0.004250393
#> 0.004241653
#> 0.004244270
#> 0.004244261
#> 0.004244259
#> Best iteration:
#> iter train_logloss_mean train_logloss_std test_logloss_mean test_logloss_std
#> 1000 0.4583307 0.001051172 0.4910193 0.004244259
|
1
2
3
4
5
6
7
8
9
|
xgb1 <- xgb.train (params = params,
data = dtrain,
nrounds = xgbcv$best_iteration,
watchlist = list(val=dtest,train=dtrain),
print_every_n = 100,
early_stoping_rounds = 10,
maximize = F ,
eval_metric = "error",
verbosity = 0)
|
1
2
3
4
5
6
7
8
9
10
11
|
#> [1] val-error:0.410279 train-error:0.400343
#> [101] val-error:0.255587 train-error:0.238428
#> [201] val-error:0.249188 train-error:0.231015
#> [301] val-error:0.247088 train-error:0.227503
#> [401] val-error:0.246588 train-error:0.224928
#> [501] val-error:0.246388 train-error:0.224478
#> [601] val-error:0.245038 train-error:0.222828
#> [701] val-error:0.243438 train-error:0.222065
#> [801] val-error:0.243088 train-error:0.221553
#> [901] val-error:0.242738 train-error:0.220878
#> [1000] val-error:0.242088 train-error:0.219790
|
1
2
|
xgbpred_prob <- predict(object = xgb1, newdata = dtest)
xgbpred <- ifelse (xgbpred_prob > 0.45,1,0)
|
1
2
|
confmat_xgb <- confusionMatrix(as.factor(xgbpred), as.factor(label_test), positive = "1")
confmat_xgb
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction 0 1
#> 0 7347 2255
#> 1 2732 7667
#>
#> Accuracy : 0.7507
#> 95% CI : (0.7446, 0.7566)
#> No Information Rate : 0.5039
#> P-Value [Acc > NIR] : < 0.00000000000000022
#>
#> Kappa : 0.5015
#>
#> Mcnemar's Test P-Value : 0.00000000001579
#>
#> Sensitivity : 0.7727
#> Specificity : 0.7289
#> Pos Pred Value : 0.7373
#> Neg Pred Value : 0.7652
#> Prevalence : 0.4961
#> Detection Rate : 0.3833
#> Detection Prevalence : 0.5199
#> Balanced Accuracy : 0.7508
#>
#> 'Positive' Class : 1
#>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
confmat_rf <- confusionMatrix(pred_rf$result,
test$STATUS,
mode = "prec_recall",
positive = "bad credit")
eval_rf <- tidy(confmat_rf) %>%
mutate(model = "Random Forest") %>%
select(model, term, estimate) %>%
filter(term %in% c("accuracy", "precision", "recall", "specificity"))
confmat_xgb <- confusionMatrix(as.factor(xgbpred), as.factor(label_test), positive = "1")
eval_xgb <- tidy(confmat_xgb) %>%
mutate(model = "XGBoost") %>%
select(model, term, estimate) %>%
filter(term %in% c("accuracy", "precision", "recall", "specificity"))
|
Setelah diperoleh perfomance model XGBoost kita akan membandingkan dengan perfomance model random forest.
1
2
|
eval_result <- rbind(eval_rf, eval_xgb)
eval_result
|
1
2
3
4
5
6
7
8
9
10
11
|
#> # A tibble: 8 × 3
#> model term estimate
#> <chr> <chr> <dbl>
#> 1 Random Forest accuracy 0.812
#> 2 Random Forest specificity 0.815
#> 3 Random Forest precision 0.811
#> 4 Random Forest recall 0.809
#> 5 XGBoost accuracy 0.751
#> 6 XGBoost specificity 0.729
#> 7 XGBoost precision 0.737
#> 8 XGBoost recall 0.773
|
Metrics evaluasi yang kita utamakan adalah recall karena kita ingin meminimalisir mungkin keadaan dimana data actual nasabah tersebut bad credit namun terprediksi sebagai good credit. Dari hasil evaluasi dapat diketahui model XGBoost memiliki nilai recall lebih tinggi dibandingkan model random forest.
1
2
3
4
5
6
7
|
library(Ckmeans.1d.dp)
var_imp <- xgb.importance(model = xgb1,
feature_names = dimnames(dtrain)[[2]])
xgb.ggplot.importance(var_imp,top_n = 10) +
theme_minimal()+
theme(legend.position = "none")
|
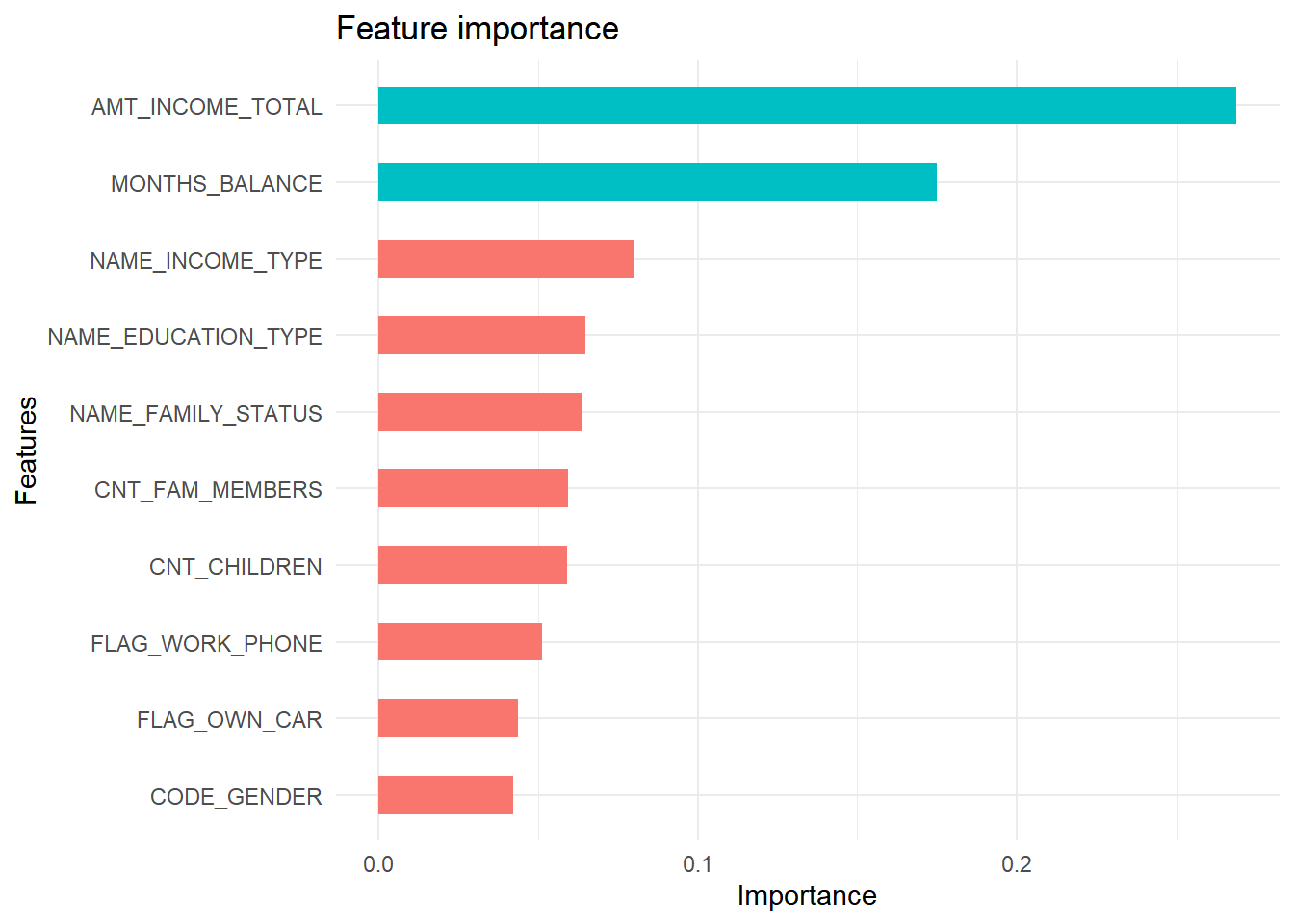 Grafik di atas menampilkan informasi mengenai 10 variabel yang paling berpengaruh pada model. Annual income dan months balance merupakan dua variabel terpenting pada model ini.
Grafik di atas menampilkan informasi mengenai 10 variabel yang paling berpengaruh pada model. Annual income dan months balance merupakan dua variabel terpenting pada model ini.
1
2
3
4
5
6
7
8
|
xgb_result <- data.frame(class1 = xgbpred_prob, actual = as.factor(label_test))
auc_xgb <- roc_auc(data = xgb_result, truth = actual,class1)
value_roc_xgb <- prediction(predictions = xgbpred_prob,
labels = label_test)
# ROC curve
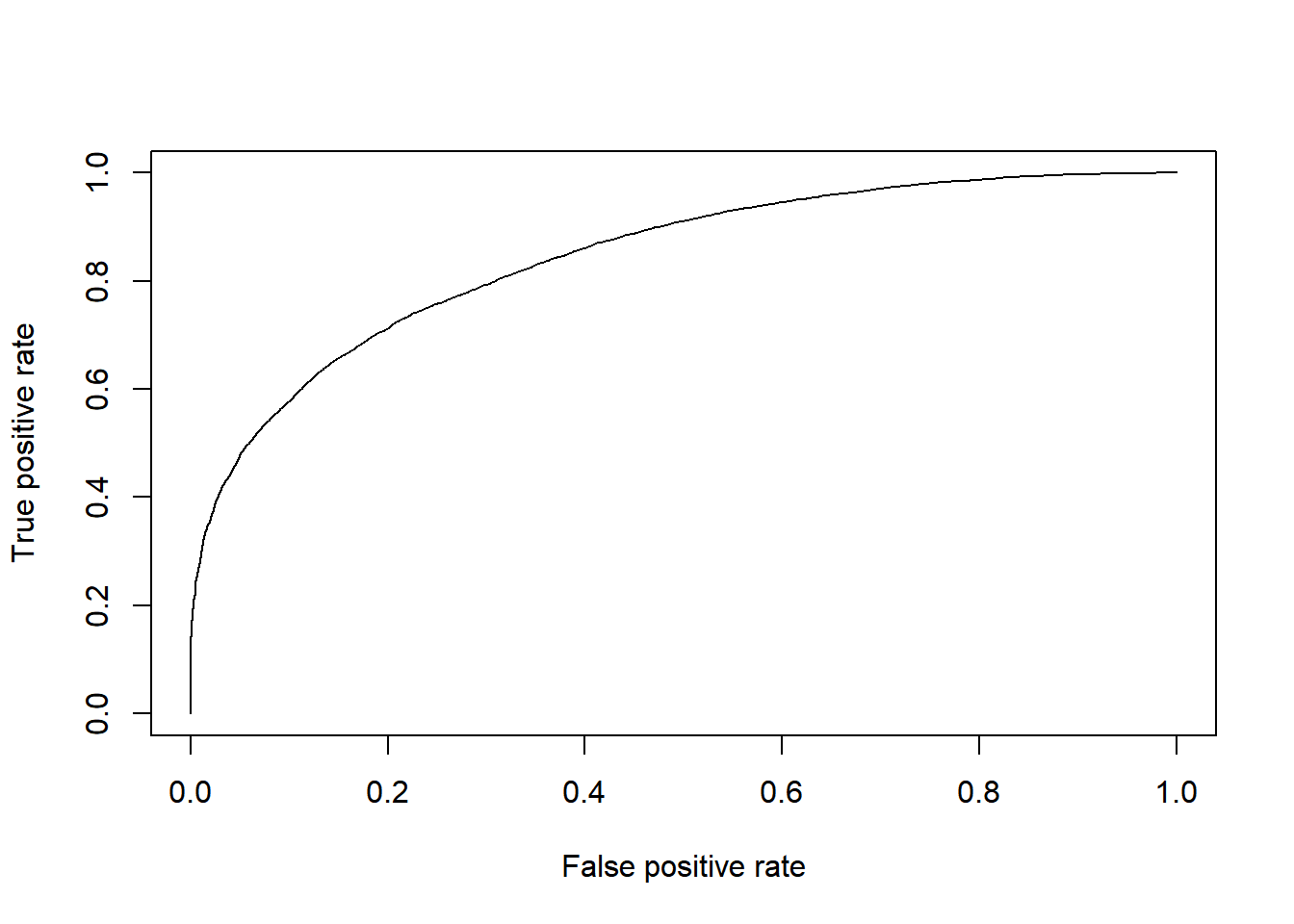
plot(performance(value_roc_xgb, "tpr", "fpr"))
|
1
2
|
value_auc_xgb <- performance(value_roc_xgb, measure = "auc")
value_auc_xgb@y.values
|
1
2
|
#> [[1]]
#> [1] 0.8434915
|
Nilai AUC yang diperoleh pada model model ini sebesar 0.84 artinya model dapat memprediksi dengan baik kedua target class yaitu good credit dan bad credit. Harapannya model ini dapat digunakan oleh pihak bank untuk menentukan credit scoring dengan mengisikan data profil nasabah, kemudian hasil yang diperoleh dapat di visualisasikan sebagai berikut:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
set.seed(123)
explainer <- lime(train_matrix %>% as.data.frame(), xgb1)
explanation <- explain( test_matrix[11:12, ] %>%
as.data.frame(),
explainer,
labels = "1",
n_features = 3,
n_permutations = 5000,
dist_fun = "manhattan",
kernel_width = 0.75,
feature_select = "highest_weights")
plot_features(explanation)
|
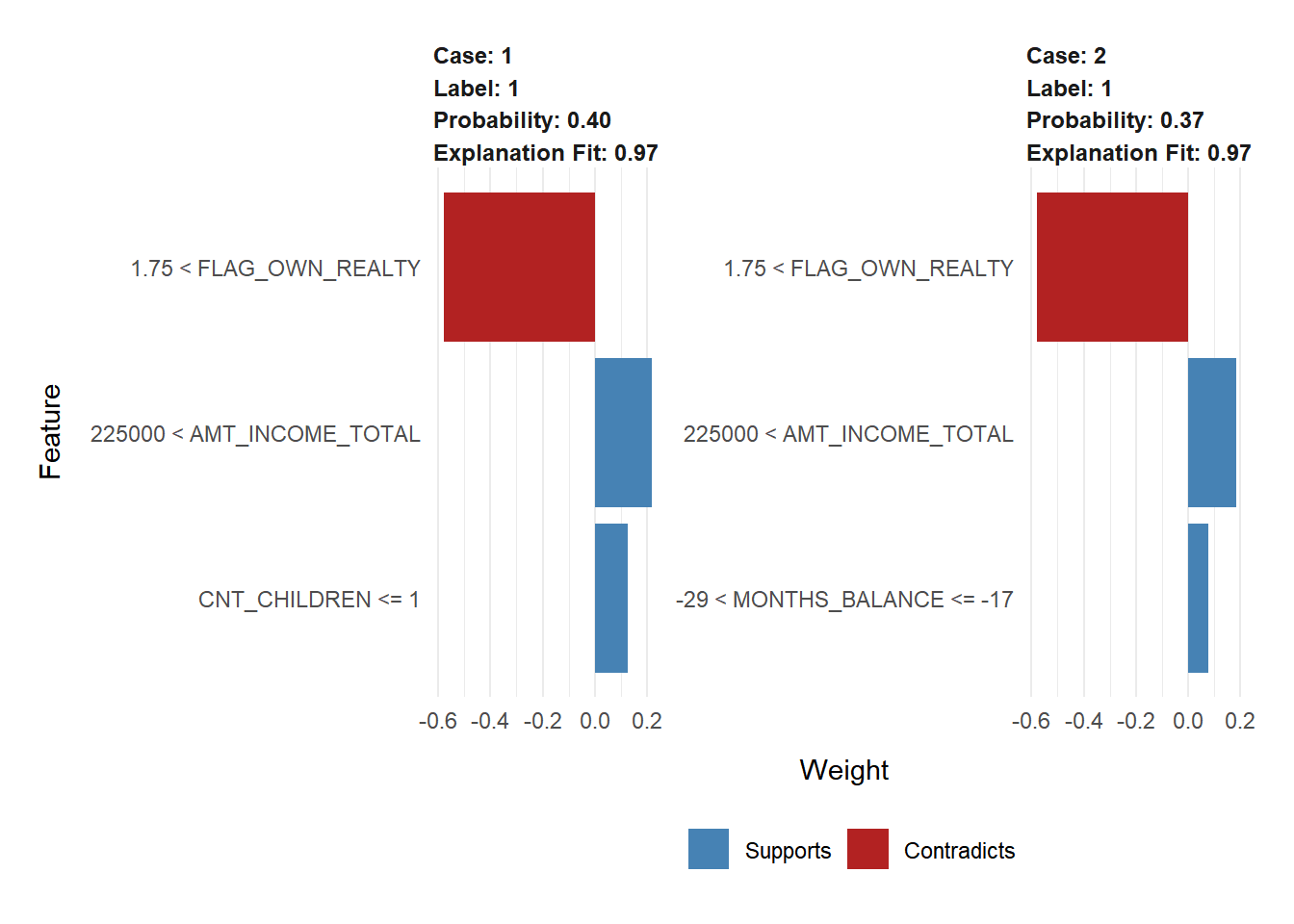
Hasil dari visualisasi tersebut untuk nasabah 1 dan 2 memiliki probability 0.4 dan 0.37 artinya kedua nasabah tersebut akan dikategorikan sebagai good credit. Kedua nasabah tersebut memiliki karakteristik yang mirip karena hasil prediksi mereka didukung oleh kepemilikan model dan juga total income.
