
Predicting Algerian Forest
Pendahuluan
Kebakaran hutan terjadi secara tidak terencana dan tidak terkendali dan dapat terjadi oleh petir atau kelalaian manusia di hutan, padang rumput, atau semak-semak (Government of Canada, 2020). Sebagian besar kebakaran hutan disebabkan oleh manusia, namun iklim kering, suhu panas, petir, dan letusan gunung berapi juga dapat menyebabkan kejadian tersebut (National Park Service, 2018). Dekade terakhir perubahan iklim hanya memperparah jumlah kebakaran hutan, menyebabkan kejadian yang lebih sering dan ekstrem.
Badan penanggulangan kebakaran hutan menggunakan banyak variabel untuk menunjukkan kebakaran hutan yang akan terjadi dan evolusi dari machine learning telah memberikan kita kemampuan untuk memprediksi kejadian masa depan dengan menganalisis variabel-variabel ini. Oleh karena itu, dengan mengajukan pertanyaan prediktif: apakah variabel tertentu memungkinkan kita untuk menentukan apakah kebakaran hutan telah atau akan terjadi dan jika ya, seberapa akurat mereka akan terjadi?
Untuk mendukung hipotesis tersebut, saya menggunakan dataset tentang Kebakaran Hutan Algeria dari UCI dataset. Dataset ini berisi kumpulan observasi kebakaran hutan dan data di dua wilayah Algeria: wilayah Bejaia dan wilayah Sidi Bel-Abbes. Rentang waktu dataset ini adalah dari Juni 2012 hingga September 2012 (Tanggal: (DD/MM/YYYY) Hari, bulan (‘juni’ hingga ‘september’), tahun (2012)).
Dalam proyek ini, saya berfokus pada apakah karakteristik cuaca tertentu dapat memprediksi kebakaran hutan di wilayah-wilayah ini menggunakan algoritma Klasifikasi berbagai macam metode pohon keputusan dan kemudian, saya mengevaluasi akurasi modelnya.
|
|
#> Reading layer `algeria-with-regions_1411' from data source
#> `C:\Users\irvan\OneDrive\Desktop\Algoritma\4.RnD\algotech\content\post\2024-04-24-forest-fire-prediction\algeria_administrative\algeria-with-regions_1411.geojson'
#> using driver `GeoJSON'
#> Simple feature collection with 58 features and 1 field
#> Geometry type: MULTIPOLYGON
#> Dimension: XY
#> Bounding box: xmin: -8.668908 ymin: 18.96815 xmax: 11.99734 ymax: 37.08985
#> Geodetic CRS: WGS 84
Algeria: wilayah Bejaia dan wilayah Sidi Bel-Abbes
|
|
#> [1] "أدرار" "الشلف" "الأغواط" "أم البواقي"
#> [5] "باتنة" "بجاية" "بسكرة" "بشار"
#> [9] "البليدة" "البويرة" "تمنراست" "تبسة"
#> [13] "تلمسان" "تيارت" "تيزي وزو" "الجزائر"
#> [17] "الجلفة" "جيجل" "سطيف" "سعيدة"
#> [21] "سكيكدة" "سيدي بلعباس" "عنابة" "قالمة"
#> [25] "قسنطينة" "المدية" "مستغانم" "المسيلة"
#> [29] "معسكر" "ورقلة" "وهران" "البيض"
#> [33] "اليزي" "برج بوعريريج" "بومرداس" "الطارف"
#> [37] "تندوف" "تسمسيلت" "الوادي" "خنشلة"
#> [41] "سوق أهراس" "تيبازة" "ميلة" "عين الدفلى"
#> [45] "النعامة" "عين تموشنت" "غرداية" "غليزان"
#> [49] "المغير" "المنيعة" "أولاد جلال" "برج باجي مختار"
#> [53] "بني عباس" "تيميمون" "تقرت" "جانت"
#> [57] "عين صالح" "عين قزّام"
Dari daftar yang diberikan, “بجاية” adalah Bejaia dan “سيدي بلعباس” adalah Sidi Bel-Abbes.
Metode
Disini saya menggunakan beragam pustaka dalam bahasa pemrograman R untuk melakukan analisis dan pemodelan data untuk menjawab permasalahan yang ada. Menitikberatkan perbandingan antara berbagai library yang berbeda dalam proyek berbasis Decision Tree ini memiliki beberapa alasan yang mendasar:
-
Perbandingan Performa: Setiap library atau paket memiliki keunggulan dan kelemahan tersendiri dalam implementasi algoritma Decision Tree. Melakukan perbandingan akan membantu kita memahami mana yang lebih cocok untuk kasus tertentu, serta melihat performa relatif dari masing-masing library.
-
Kemampuan dan Fitur Tambahan: Beberapa library mungkin memiliki fitur tambahan atau pendekatan yang unik dalam membangun pohon keputusan. Melalui perbandingan, kita dapat mengeksplorasi fitur-fitur tambahan ini dan menentukan apakah itu relevan atau tidak dengan kebutuhan proyek.
-
Ketersediaan dan Dukungan: Ketersediaan library dan tingkat dukungan komunitasnya juga merupakan faktor penting. Library yang lebih populer atau aktif dikembangkan mungkin memiliki dokumentasi yang lebih baik, pembaruan terkini, dan komunitas yang lebih besar untuk mendukung pemecahan masalah.
-
Konteks Proyek: Tidak ada satu ukuran yang cocok untuk semua dalam pemodelan data. Konteks proyek, karakteristik data, dan tujuan analisis dapat mempengaruhi pilihan library yang paling sesuai. Melalui perbandingan, kita dapat menyesuaikan pilihan dengan kebutuhan spesifik proyek.
-
Pemahaman Algoritma: Melakukan perbandingan antara library juga membantu dalam pemahaman yang lebih baik tentang algoritma Decision Tree itu sendiri. Membandingkan implementasi yang berbeda dapat membantu kita memahami detail dan mekanisme di balik algoritma tersebut.
Dengan mempertimbangkan semua faktor ini, melakukan perbandingan antara berbagai library dalam proyek Decision Tree dapat membantu dalam membuat keputusan yang lebih terinformasi dan memastikan bahwa kita memanfaatkan alat yang paling efektif dan efisien untuk tujuan analisis data yang spesifik.
Berikut adalah perbandingan antara beberapa algoritma pohon keputusan yang umum digunakan dalam lingkungan R, yaitu rpart, party, C5.0, dan caret:
- rpart (Recursive Partitioning and Regression Trees):
rpartadalah salah satu paket yang sering digunakan dalam R untuk membuat model pohon keputusan.- Algoritma rpart menggunakan pendekatan partisi rekursif (proses iteratif yang membagi dataset menjadi subset yang semakin kecil dan lebih homogen berdasarkan nilai variabel prediktor) untuk membangun pohon keputusan.
- rpart dapat digunakan baik untuk regresi maupun klasifikasi.
- Mengadopsi algoritma CART (Classification and Regression Trees).
- Mudah digunakan dan fleksibel dalam penggunaannya.
- party:
- Paket
partymenyediakan algoritma pohon keputusan lain dalam lingkungan R. - Algoritma yang ditawarkan oleh paket ini disebut CTree (Conditional Inference Trees).
- CTree mengatasi beberapa kelemahan dalam algoritma CART, terutama dalam menangani variabel kategori dengan banyak level.
- Lebih efisien dalam menangani variabel prediktor yang memiliki banyak level atau interaksi yang kompleks.
- Paket
- C5.0:
C5.0adalah algoritma pembelajaran mesin yang dikembangkan oleh Ross Quinlan.- Meskipun paket C5.0 tidak langsung tersedia di R, ada paket bernama
C50yang menawarkan antarmuka ke algoritma C5.0. link. - C5.0 menunjukkan kinerja yang baik dalam menangani variabel numerik dan kategori.
- Algoritma ini dapat menangani permasalahan klasifikasi dan regresi.
- C5.0 menggabungkan prinsip pembelajaran pohon keputusan dengan teknik pruning untuk menghindari overfitting.
- caret:
- Paket
caret(Classification And REgression Training) menyediakan antarmuka yang seragam untuk berbagai algoritma pembelajaran mesin, termasuk pohon keputusan. - Dengan caret, kita dapat melakukan proses pemodelan dengan mudah, termasuk preprocessing data, pemilihan fitur, penyetelan parameter, dan evaluasi model.
- Ini memungkinkan eksperimen dengan berbagai algoritma dan parameter untuk memilih model terbaik.
- Dengan caret, kita dapat membandingkan dan mengevaluasi performa berbagai algoritma pohon keputusan dengan konsistensi yang tinggi.
- Paket
Pemilihan algoritma pohon keputusan yang tepat tergantung pada karakteristik data, seperti jenis variabel, kompleksitas interaksi antar variabel, dan tujuan analisis (klasifikasi atau regresi).
Importing important libraries
|
|
Data Importing & Cleaning & Inspecting
Import dataset
Dataset Kebakaran Hutan Algeria dibaca menggunakan fungsi read_csv.
|
|
#> day month year Temperature RH Ws Rain FFMC DMC DC ISI BUI FWI Classes
#> 1 01 06 2012 29 57 18 0 65.7 3.4 7.6 1.3 3.4 0.5 not fire
#> 2 02 06 2012 29 61 13 1.3 64.4 4.1 7.6 1 3.9 0.4 not fire
#> 3 03 06 2012 26 82 22 13.1 47.1 2.5 7.1 0.3 2.7 0.1 not fire
#> 4 04 06 2012 25 89 13 2.5 28.6 1.3 6.9 0 1.7 0 not fire
#> 5 05 06 2012 27 77 16 0 64.8 3 14.2 1.2 3.9 0.5 not fire
#> 6 06 06 2012 31 67 14 0 82.6 5.8 22.2 3.1 7 2.5 fire
Dalam proyek yang saya lakukan ini, saya menggunakan dataset yang merupakan gabungan dari dua wilayah yang berbeda. Pada file CSV dataset ini, kolom-kolomnya sudah dibedakan berdasarkan wilayahnya. Namun, terdapat redundansi dalam judul kolom pada dataset kedua, yang sebenarnya menyebabkan duplikasi informasi. Untuk menghindari kebingungan dan mempermudah analisis, saya memutuskan untuk menghapus judul kolom pada dataset kedua dan menggabungkan dataset tersebut menjadi satu kesatuan.
Dengan menghapus judul kolom yang redundan, saya dapat menyederhanakan struktur dataset dan membuatnya lebih mudah dipahami. Langkah ini juga akan membantu saya dalam proses analisis data karena saya akan memiliki satu set data yang lebih bersih dan konsisten. Dengan demikian, langkah ini akan mempermudah proses pengolahan dan interpretasi data secara keseluruhan, serta meminimalkan kemungkinan kesalahan yang terjadi akibat duplikasi informasi.
|
|
#> day month year Temperature RH Ws Rain FFMC DMC DC ISI BUI FWI Classes
#> 1 01 06 2012 29 57 18 0 65.7 3.4 7.6 1.3 3.4 0.5 not fire
#> 2 02 06 2012 29 61 13 1.3 64.4 4.1 7.6 1 3.9 0.4 not fire
#> 3 03 06 2012 26 82 22 13.1 47.1 2.5 7.1 0.3 2.7 0.1 not fire
#> 4 04 06 2012 25 89 13 2.5 28.6 1.3 6.9 0 1.7 0 not fire
#> 5 05 06 2012 27 77 16 0 64.8 3 14.2 1.2 3.9 0.5 not fire
#> 6 06 06 2012 31 67 14 0 82.6 5.8 22.2 3.1 7 2.5 fire
Tabel 1: Tabel Kebakaran Hutan di Aljazair (sebelum cleansing)
Dalam proses pembuatan klasifikasi untuk memprediksi kebakaran atau tidak, keberadaan variabel tanggal seperti kolom day, month, year tidak selalu diperlukan secara langsung untuk tujuan prediksi. Variabel tanggal umumnya tidak memberikan informasi langsung tentang apakah kebakaran akan terjadi atau tidak, kecuali jika terdapat hubungan temporal yang sangat spesifik antara waktu dan kejadian kebakaran.
Namun demikian, variabel tanggal mungkin dapat memberikan informasi tambahan yang berguna melalui fitur rekayasa (feature engineering). Misalnya, variabel tanggal dapat diubah menjadi fitur tambahan seperti musim atau waktu dalam bentuk tertentu yang dapat mempengaruhi kemungkinan kebakaran, seperti musim panas atau musim hujan.
Sebelum menghapus variabel tanggal sepenuhnya, penting untuk melakukan analisis lebih lanjut atau eksplorasi data untuk memastikan apakah informasi apa pun dari tanggal dapat digunakan untuk meningkatkan kinerja model prediksi. Namun, dalam banyak kasus, variabel tanggal tidak secara langsung berkontribusi terhadap prediksi kebakaran dan mungkin tidak diperlukan dalam model klasifikasi tersebut. Sehingga saya memutuskan untuk tidak mengikutsertakannya, kembali lagi ketujuan awal saya yang ingin memprediksi kebakaran atau tidak berdasarkan murni dari faktor karakteristik cuaca.
Inspect dataset
|
|
#> day month year Temperature RH Ws
#> 0 0 0 0 0 0
#> Rain FFMC DMC DC ISI BUI
#> 0 0 0 0 0 0
#> FWI Classes
#> 0 0
Tidak terdapat nilai missing pada setiap kolom
|
|
#> Rows: 244
#> Columns: 14
#> $ day <chr> "01", "02", "03", "04", "05", "06", "07", "08", "09", "10"…
#> $ month <chr> "06", "06", "06", "06", "06", "06", "06", "06", "06", "06"…
#> $ year <chr> "2012", "2012", "2012", "2012", "2012", "2012", "2012", "2…
#> $ Temperature <chr> "29", "29", "26", "25", "27", "31", "33", "30", "25", "28"…
#> $ RH <chr> "57", "61", "82", "89", "77", "67", "54", "73", "88", "79"…
#> $ Ws <chr> "18", "13", "22", "13", "16", "14", "13", "15", "13", "12"…
#> $ Rain <chr> "0", "1.3", "13.1", "2.5", "0", "0", "0", "0", "0.2", "0",…
#> $ FFMC <chr> "65.7", "64.4", "47.1", "28.6", "64.8", "82.6", "88.2", "8…
#> $ DMC <chr> "3.4", "4.1", "2.5", "1.3", "3", "5.8", "9.9", "12.1", "7.…
#> $ DC <chr> "7.6", "7.6", "7.1", "6.9", "14.2", "22.2", "30.5", "38.3"…
#> $ ISI <chr> "1.3", "1", "0.3", "0", "1.2", "3.1", "6.4", "5.6", "0.4",…
#> $ BUI <chr> "3.4", "3.9", "2.7", "1.7", "3.9", "7", "10.9", "13.5", "1…
#> $ FWI <chr> "0.5", "0.4", "0.1", "0", "0.5", "2.5", "7.2", "7.1", "0.3…
#> $ Classes <chr> "not fire ", "not fire ", "not fire ", "not fire "…
Karakteristik cuaca pada dataset:
Temperature(Suhu): Merupakan suhu maksimum pada siang hari dalam derajat Celsius, dengan rentang nilai antara 22 hingga 42. Suhu ini menggambarkan tingkat panas yang dapat mempengaruhi potensi kebakaran hutan.RH(Kelembaban Relatif): Persentase kelembaban udara relatif dalam rentang 21 hingga 90 persen. Kelembaban udara mempengaruhi ketersediaan air dalam material pembakar dan dapat memengaruhi potensi kebakaran hutan.Ws(Kecepatan Angin): Kecepatan angin dalam kilometer per jam, dengan rentang dari 6 hingga 29 km/jam. Angin yang kuat dapat mempercepat penyebaran api pada kebakaran hutan.Rain(Curah Hujan): Jumlah curah hujan dalam milimeter selama satu hari. Curah hujan dapat mempengaruhi tingkat kelembaban dan potensi kebakaran hutan. rentang nilai 0 - 16.8 total hujan dalam mm.Fine Fuel Moisture Code (FFMC)(Indeks Kadar Air Material Bakar Halus): Indeks dari sistem FWI yang mencerminkan kekeringan dan kemampuan material bakar halus untuk terbakar. Rentang nilainya adalah 28.6 hingga 92.5.Duff Moisture Code (DMC)(Indeks Kadar Air Lapisan Tanduk): Indeks dari sistem FWI yang menilai kekeringan lapisan tanduk dan kemungkinan material bakar menyerap kelembaban. Rentang nilainya adalah 1.1 hingga 65.9.Drought Code (DC)(Indeks Kekeringan): Indeks dari sistem FWI yang menggambarkan kekeringan permukaan tanah. Nilainya berkisar dari 7 hingga 220.4.Initial Spread Index (ISI)(Indeks Penyebaran Awal): Indeks dari sistem FWI yang menunjukkan kecepatan dan intensitas penyebaran api setelah terjadi kebakaran. Rentang nilainya adalah 0 hingga 18.5.Buildup Index (BUI)(Indeks Pembangunan): Indeks dari sistem FWI yang menggambarkan akumulasi material bakar yang tersedia untuk terbakar. Rentang nilainya adalah 1.1 hingga 68.Fire Weather Index (FWI)(Indeks Cuaca Kebakaran): Indeks gabungan dari sistem FWI yang mencakup faktor-faktor seperti kekeringan, kelembaban, dan kecepatan angin yang mempengaruhi potensi kebakaran hutan.Classes(Kelas): Terdiri dari dua kelas, yaitu “fire” (kebakaran) dan “not fire” (bukan kebakaran), yang merupakan target prediksi dalam analisis kebakaran hutan.
Dataset ini merupakan kumpulan data pengamatan dan informasi kebakaran hutan yang terjadi di dua wilayah di Aljazair: wilayah Bejaia dan wilayah Sidi Bel-Abbes.
Data Cleansing
Tahapan membuang kolom yang tidak digunakan dan melakukan perubahan tipedata yang sesuai.
|
|
#> Temperature RH Ws Rain FFMC DMC DC ISI BUI FWI Classes
#> 1 29 57 18 0.0 65.7 3.4 7.6 1.3 3.4 0.5 not fire
#> 2 29 61 13 1.3 64.4 4.1 7.6 1.0 3.9 0.4 not fire
#> 3 26 82 22 13.1 47.1 2.5 7.1 0.3 2.7 0.1 not fire
#> 4 25 89 13 2.5 28.6 1.3 6.9 0.0 1.7 0.0 not fire
#> 5 27 77 16 0.0 64.8 3.0 14.2 1.2 3.9 0.5 not fire
#> 6 31 67 14 0.0 82.6 5.8 22.2 3.1 7.0 2.5 fire
|
|
#> [1] not fire fire fire fire not fire
#> [6] not fire not fire not fire
#> 9 Levels: fire fire fire not fire not fire not fire ... not fire
Kondisi kolom target seharusnya hanya memiliki dua level (“fire” dan “not fire”), tetapi dalam kenyataannya memiliki lebih dari dua level yang ternyata saat dicek terdapat spasi pada teks.
Pada tahapan berikut, saya memastikan bahwa kolom target memiliki dua level yang diharapkan, yang akan meningkatkan keakuratan dan keandalan model klasifikasi.
|
|
|
|
|
|
#> [1] not fire fire
#> Levels: fire not fire
|
|
#> [1] 2
|
|
#> Temperature RH Ws Rain
#> Min. :22.00 Min. :21.00 Min. : 6.00 Min. : 0.000
#> 1st Qu.:30.00 1st Qu.:52.50 1st Qu.:14.00 1st Qu.: 0.000
#> Median :32.00 Median :63.00 Median :15.00 Median : 0.000
#> Mean :32.15 Mean :62.04 Mean :15.49 Mean : 0.763
#> 3rd Qu.:35.00 3rd Qu.:73.50 3rd Qu.:17.00 3rd Qu.: 0.500
#> Max. :42.00 Max. :90.00 Max. :29.00 Max. :16.800
#> FFMC DMC DC ISI
#> Min. :28.60 Min. : 0.70 Min. : 6.90 Min. : 0.000
#> 1st Qu.:71.85 1st Qu.: 5.80 1st Qu.: 12.35 1st Qu.: 1.400
#> Median :83.30 Median :11.30 Median : 33.10 Median : 3.500
#> Mean :77.84 Mean :14.68 Mean : 49.43 Mean : 4.742
#> 3rd Qu.:88.30 3rd Qu.:20.80 3rd Qu.: 69.10 3rd Qu.: 7.250
#> Max. :96.00 Max. :65.90 Max. :220.40 Max. :19.000
#> BUI FWI Classes
#> Min. : 1.10 Min. : 0.000 fire :137
#> 1st Qu.: 6.00 1st Qu.: 0.700 not fire:106
#> Median :12.40 Median : 4.200
#> Mean :16.69 Mean : 7.035
#> 3rd Qu.:22.65 3rd Qu.:11.450
#> Max. :68.00 Max. :31.100
|
|
#> Temperature RH Ws Rain FFMC DMC DC ISI BUI FWI Classes
#> 1 29 57 18 0.0 65.7 3.4 7.6 1.3 3.4 0.5 not fire
#> 2 29 61 13 1.3 64.4 4.1 7.6 1.0 3.9 0.4 not fire
#> 3 26 82 22 13.1 47.1 2.5 7.1 0.3 2.7 0.1 not fire
#> 4 25 89 13 2.5 28.6 1.3 6.9 0.0 1.7 0.0 not fire
#> 5 27 77 16 0.0 64.8 3.0 14.2 1.2 3.9 0.5 not fire
#> 6 31 67 14 0.0 82.6 5.8 22.2 3.1 7.0 2.5 fire
Tabel 2: Tabel Kebakaran Hutan di Aljazair (sesudah cleansing)
Exploratory Data Analysis
Evaluasi Korelasi Antar Variabel
Korelasi antara variabel-variabel dalam dataset dievaluasi menggunakan fungsi chart.Correlation untuk memahami hubungan antara variabel-variabel dan memilih yang paling relevan untuk analisis lebih lanjut. Meskipun Decision Tree tidak bergantung pada asumsi korelasi linear seperti regresi, memahami korelasi antar variabel tetap penting untuk mengevaluasi potensi korelasi yang tinggi yang dapat mempengaruhi kinerja model secara keseluruhan.
Meskipun Decision Tree tidak terlalu bergantung pada korelasi antar-variabel seperti model lainnya, pemahaman korelasi antara variabel-variabel dapat membantu dalam pemilihan fitur dan pemahaman tentang struktur data secara keseluruhan. Dengan memilih variabel yang paling relevan, dapat meningkatkan interpretasi model dan mengurangi kompleksitasnya. Oleh karena itu, memeriksa korelasi tetap dapat menjadi langkah yang berguna dalam proses pembangunan model Decision Tree.
Berikut adalah visualisasi korelasi antar variabel menggunakan chart.Correlation:
|
|
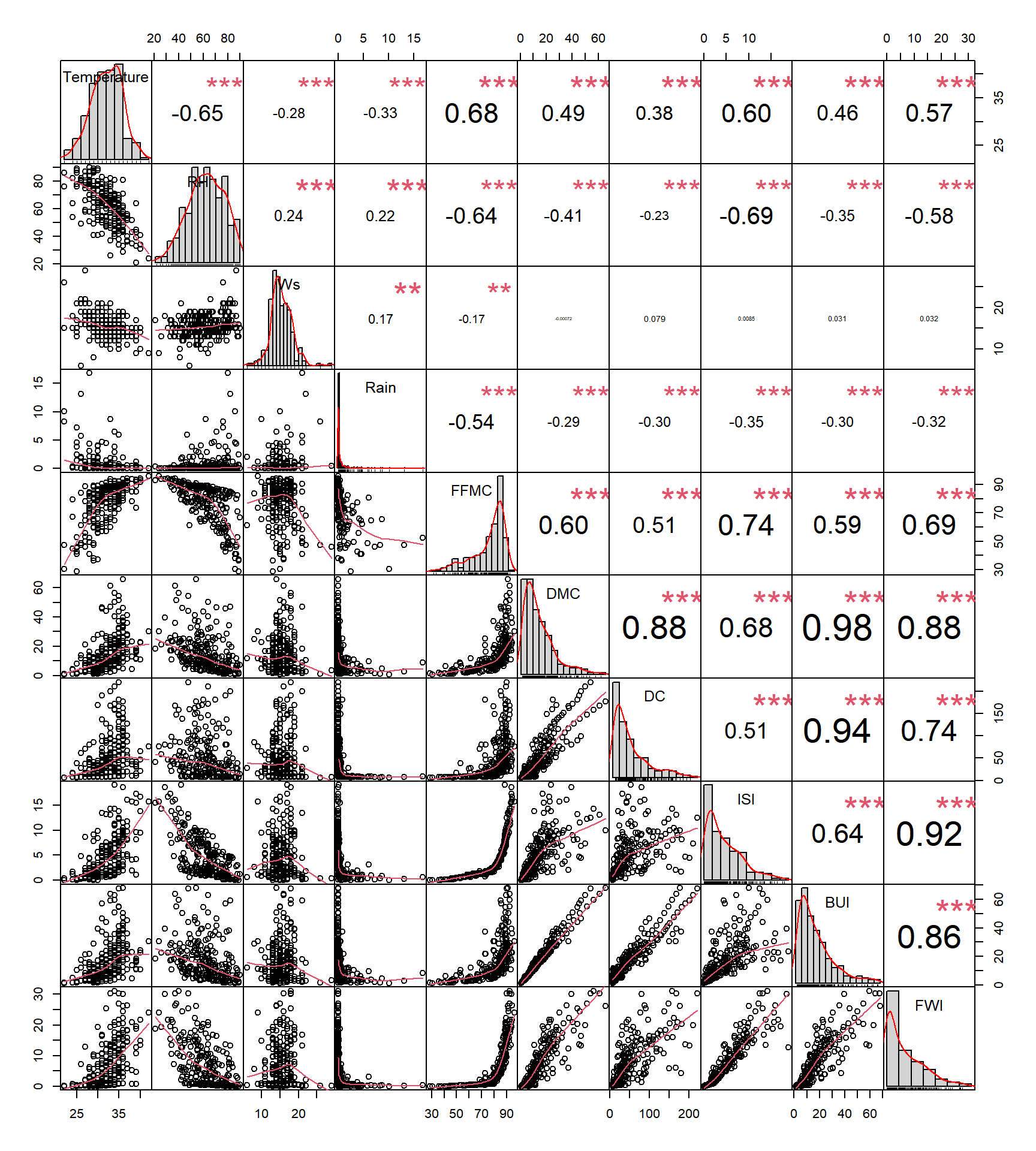 Plot `chart.Correlation` diatas merupakan representasi visual dari matriks korelasi antar variabel (numerik) dalam dataset. Setiap sel pada matriks menunjukkan korelasi antara dua variabel yang sesuai.
Plot `chart.Correlation` diatas merupakan representasi visual dari matriks korelasi antar variabel (numerik) dalam dataset. Setiap sel pada matriks menunjukkan korelasi antara dua variabel yang sesuai.
Interpretasi plot chart.Correlation diatas:
- Distribusi masing-masing variabel ditunjukkan secara diagonal.
- Di bagian bawah diagonal : ditampilkan scatterplot bivariat dengan garis fitted.
- Diagonal atas : nilai korelasi ditambah tingkat signifikansinya sebagai bintang.
Pada chart.Correlation, tanda bintang menunjukkan tingkat signifikansi dari korelasi antara pasangan variabel. Ini mengindikasikan seberapa kuat hubungan antara variabel-variabel tersebut, diukur dengan tingkat kepercayaan tertentu.
- Satu bintang (’*’) menunjukkan bahwa korelasi antara pasangan variabel tersebut signifikan pada tingkat 10%.
- Dua bintang (’**’) menunjukkan bahwa korelasi signifikan pada tingkat 5%.
- Tiga bintang (’***’) menunjukkan bahwa korelasi signifikan pada tingkat 1%.
Ketika sebuah variabel memiliki tanda bintang, itu menunjukkan bahwa hubungan antara variabel tersebut dengan variabel lain dalam dataset secara signifikan berbeda dari nol pada tingkat signifikansi yang sesuai. Hal ini membantu mengidentifikasi variabel-variabel yang memiliki korelasi yang kuat dan signifikan, yang dapat menjadi penting dalam analisis data dan pemodelan.
Hubungan antara setiap variabel (termasuk Kelas target)
Penggunaan chart.Correlation dan ggpairs untuk menganalisis korelasi antar variabel dalam dataset tidak selalu redundan, meskipun keduanya bertujuan untuk memberikan wawasan tentang hubungan antar variabel.
Perbedaan utama antara kedua pendekatan tersebut adalah dalam gaya visualisasi dan fungsionalitas tambahan yang disediakan.
Berikut adalah perbandingan antara keduanya:
- Gaya Visualisasi:
chart.Correlationbiasanya menghasilkan matriks korelasi yang berisi sel-sel warna untuk menunjukkan kekuatan dan arah korelasi antar variabel. Ini menyediakan representasi visual yang ringkas dan mudah dimengerti tentang korelasi dalam dataset. (cocok sebagai tujuan eksplorasi)ggpairs, di sisi lain, menghasilkan kumpulan scatterplots dan histogram untuk setiap pasangan variabel dalam dataset. Ini memberikan representasi visual yang lebih terperinci tentang hubungan antar variabel, termasuk distribusi dan pola korelasi. (cocok sebagai tujuan eksplanasi)
- Fungsionalitas Tambahan:
chart.Correlationbiasanya lebih sederhana dan fokus pada korelasi antar variabel tanpa banyak fungsionalitas tambahan.ggpairsmemungkinkan pengguna untuk menyesuaikan plot dan menambahkan lapisan visual tambahan, seperti garis regresi, pengelompokan berdasarkan variabel kategori, dan tampilan tambahan lainnya. Ini memberikan lebih banyak fleksibilitas dalam analisis dan visualisasi data.
|
|
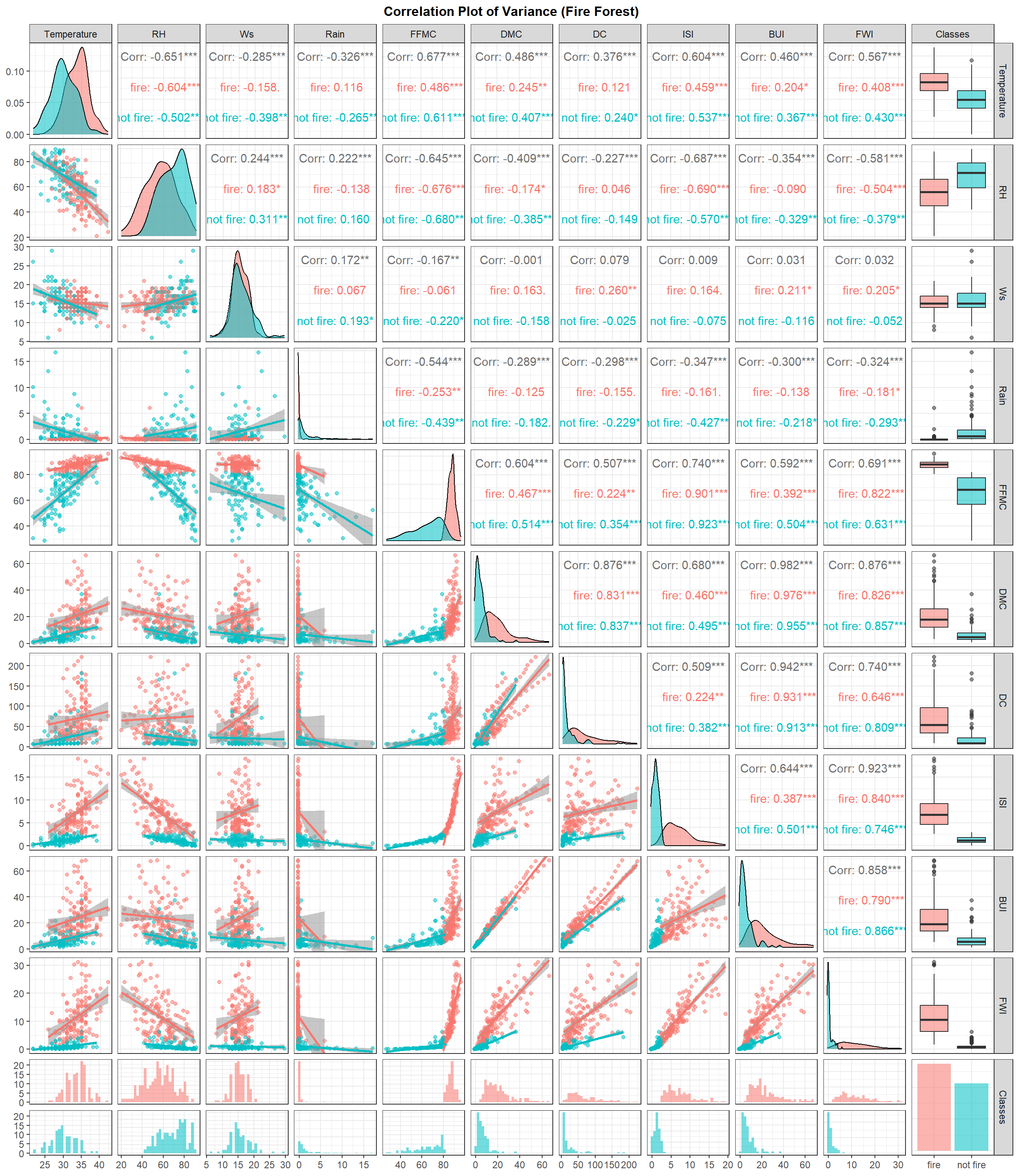
Plot diatas menampilkan berbagai jenis plot statistik, termasuk:
Scatterplot: menunjukkan hubungan bivariat antara dua variabel.- Kemiringan: menunjukkan arah hubungan linear (turun atau naik)
- Kepadatan: menunjukkan kekuatan hubungan, yang semakin mendekati garis linear (semakin kuat)
- Point-point: merupakan titik observasi
Histogram: menunjukkan distribusi marginal setiap variabel.- Distribusi normal berbentuk seperti bell curve, berdasarkan plot diatas per variable prediktor yang memiliki distribusi normal hanya
temperaturedanWind Speed.
- Distribusi normal berbentuk seperti bell curve, berdasarkan plot diatas per variable prediktor yang memiliki distribusi normal hanya
Boxplot: Hubungan distribusi antara prediktor dengan target. Contoh interpretasi: Pada variableFFMC, kelas target fire cenderung berada pada nilai-nilaiFFMCyang tinggi dan memiliki variasi yang seragam.
Plot Korelasi
Pada bagian ini, tujuannya jika nantinya kita hanya ingin fokus melihat nilai korelasinya saja. Perhitungan korelasi yang digunakan pada ketiga metode ini sama, yaitu menggunakan korelasi Pearson untuk data numerik. Korelasi Pearson mengukur kekuatan dan arah hubungan linear antara dua variabel numerik.
|
|
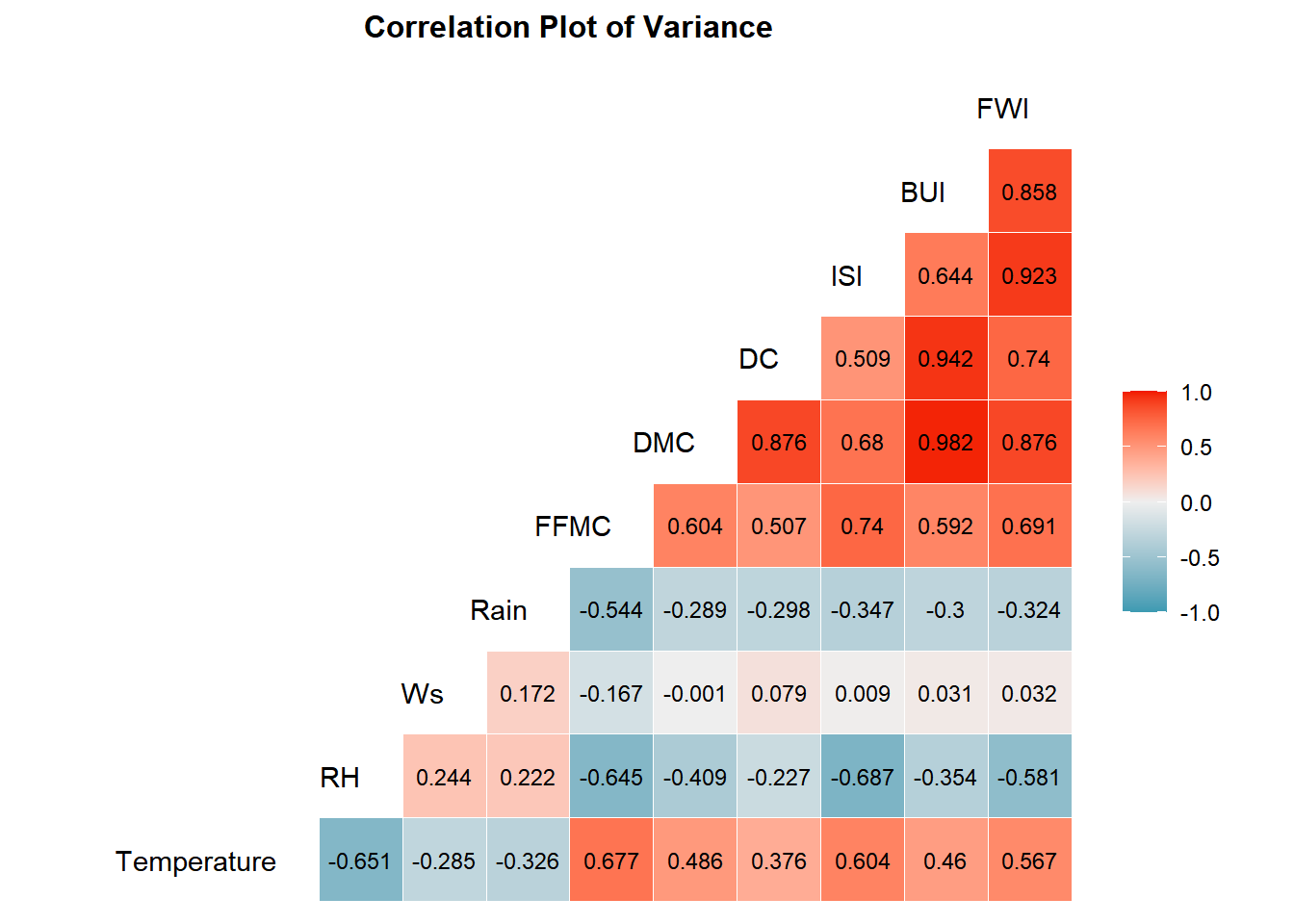
Berdasarkan plot diatas, nilai di dalam kotak menunjukkan koefisien korelasi Pearson dimana nilai beriksar dari -1 (korelasi negatif sempurna) hingga 1 (korelasi positif sempurna) dan Nilai 0 menunjukkan tidak ada korelasi.
Hampir semua prediktor memiliki korelasi yang tinggi antar prediktor. seperti DMC dengan BUI yang memiliki korelasi 1 kecuali prediktor Ws (Wind speed in km/h: 6 to 29). Hal ini dapat dijelaskan oleh beberapa faktor:
1. Sifat Faktor Cuaca:
Faktor cuaca, seperti temperatur, kelembaban, dan curah hujan, saling terkait erat. Peningkatan temperatur, misalnya, dapat menyebabkan penurunan kelembaban dan meningkatkan kemungkinan evaporasi, yang pada akhirnya dapat meningkatkan risiko kebakaran hutan.
2. Interaksi Antar Faktor:
Faktor-faktor cuaca tidak bekerja secara independen. Interaksi antar faktor dapat menghasilkan efek yang kompleks dan meningkatkan korelasi antar prediktor. Contohnya, kombinasi temperatur tinggi dan angin kencang dapat mempercepat penyebaran api dan meningkatkan intensitas kebakaran.
3. Multikolinearitas:
Ketika dua atau lebih prediktor memiliki korelasi yang tinggi, hal ini disebut multikolinearitas. Multikolinearitas dapat menyebabkan masalah dalam model prediksi, seperti inflasi varians, yang dapat membuat estimasi koefisien tidak stabil dan sulit diinterpretasikan.
4. Batasan Data:
Kualitas dan ketersediaan data dapat memengaruhi hasil analisis. Dataset yang terbatas atau tidak akurat dapat menghasilkan korelasi yang tidak realistis.
Kasus DMC dan BUI:
Korelasi 1 antara DMC (Duff Moisture Code) dan BUI (Build-Up Index) menunjukkan hubungan yang sangat kuat. Hal ini dapat dijelaskan karena kedua variabel tersebut terkait erat dengan tingkat kekeringan bahan bakar hutan. DMC mengukur kadar air di lapisan duff (lapisan organik di atas tanah), sedangkan BUI mengukur akumulasi bahan bakar mati yang tersedia untuk dibakar. Ketika bahan bakar hutan kering, risiko kebakaran hutan meningkat.
Korelasi tinggi antar prediktor dalam dataset “Forest Fire” mencerminkan hubungan kompleks antar faktor cuaca dan pengaruhnya terhadap risiko kebakaran hutan. Memahami korelasi ini penting untuk membangun model prediksi yang akurat dan mengambil langkah-langkah pencegahan yang efektif.
|
|
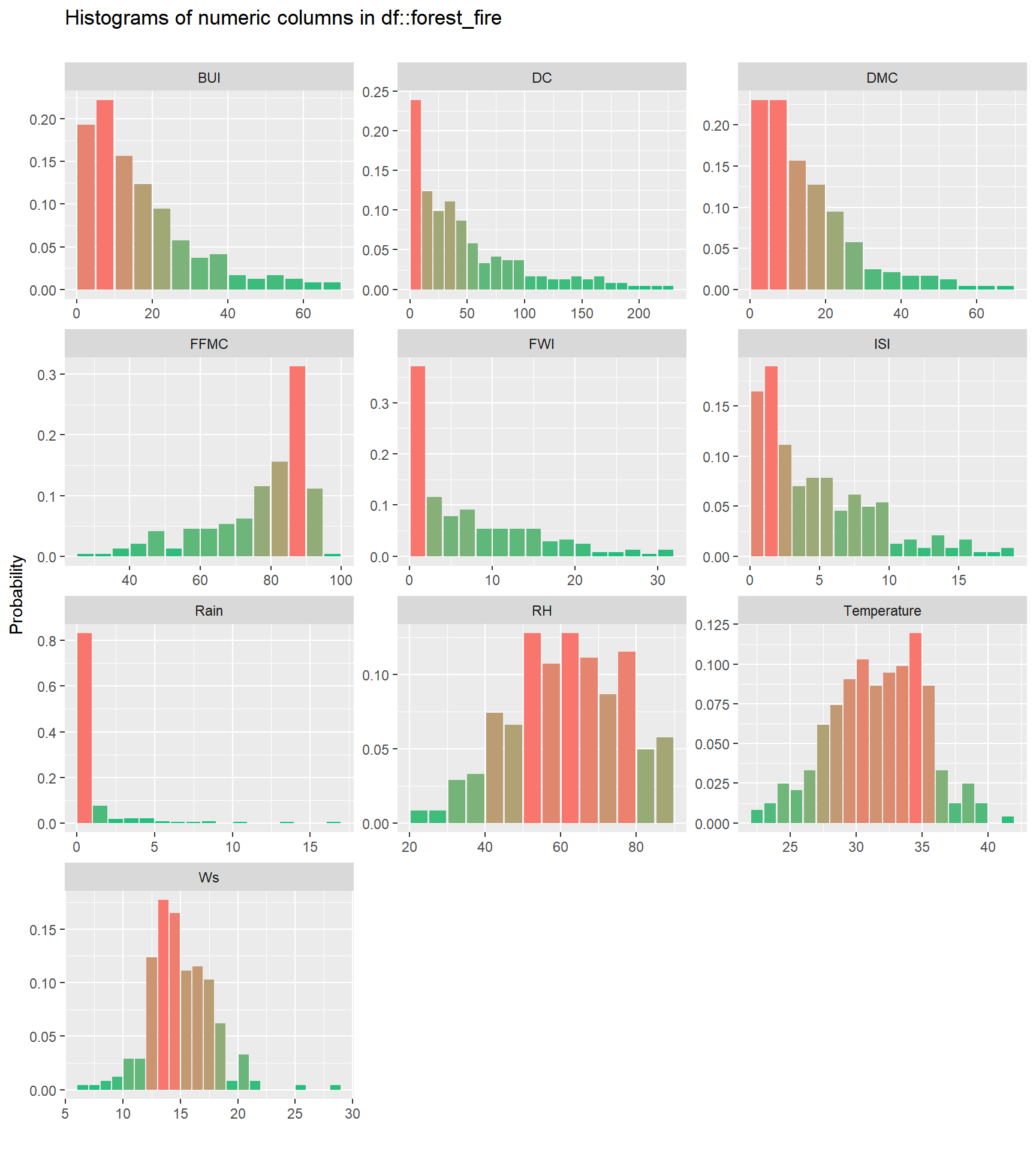 Untuk melihat lebih jelas apakah variable prediktor terdistribusi secara normal bisa dilihat menggunakan plot historgram diatas berdasarkan skewnessnya. `Skewness` adalah ukuran dari ketidaksimetrian sebuah distribusi. Sebuah distribusi dianggap tidak simetris ketika sisi kiri dan kanannya tidak mencerminkan gambaran yang sama.
Untuk melihat lebih jelas apakah variable prediktor terdistribusi secara normal bisa dilihat menggunakan plot historgram diatas berdasarkan skewnessnya. `Skewness` adalah ukuran dari ketidaksimetrian sebuah distribusi. Sebuah distribusi dianggap tidak simetris ketika sisi kiri dan kanannya tidak mencerminkan gambaran yang sama.
Sebuah distribusi bisa memiliki skewness positif (atau kanan), negatif (atau kiri), atau nol. Distribusi dengan skewness positif lebih panjang di sisi kanan puncaknya, sementara distribusi dengan skewness negatif lebih panjang di sisi kiri puncaknya.
- Normal : RH, Temperature, Ws
- Skewness positif: FFMC
- Skewness negatif: BUI, DC, DMC, FWI, ISI, Rain
|
|
#> # A tibble: 10 × 10
#> col_name min q1 median mean q3 max sd pcnt_na hist
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <named list>
#> 1 Temperature 22 30 32 32.2 35 42 3.63 0 <tibble>
#> 2 RH 21 52.5 63 62.0 73.5 90 14.8 0 <tibble>
#> 3 Ws 6 14 15 15.5 17 29 2.81 0 <tibble>
#> 4 Rain 0 0 0 0.763 0.5 16.8 2.00 0 <tibble>
#> 5 FFMC 28.6 71.8 83.3 77.8 88.3 96 14.3 0 <tibble>
#> 6 DMC 0.7 5.8 11.3 14.7 20.8 65.9 12.4 0 <tibble>
#> 7 DC 6.9 12.4 33.1 49.4 69.1 220. 47.7 0 <tibble>
#> 8 ISI 0 1.4 3.5 4.74 7.25 19 4.15 0 <tibble>
#> 9 BUI 1.1 6 12.4 16.7 22.6 68 14.2 0 <tibble>
#> 10 FWI 0 0.7 4.2 7.04 11.4 31.1 7.44 0 <tibble>
Selain melihat analisis nilai-nilai numerik pada dataset, terdapat analisis untuk melakukan inspeksi terhadap variable kategorikal dalam dataset yakni dengan fungsi inspect_cat. Fungsi ini berfungsi untuk membantu dalam memahami distribusi dan proporsi nilai unik pada setiap variable kategorik.
|
|
#> # A tibble: 1 × 5
#> col_name cnt common common_pcnt levels
#> <chr> <int> <chr> <dbl> <named list>
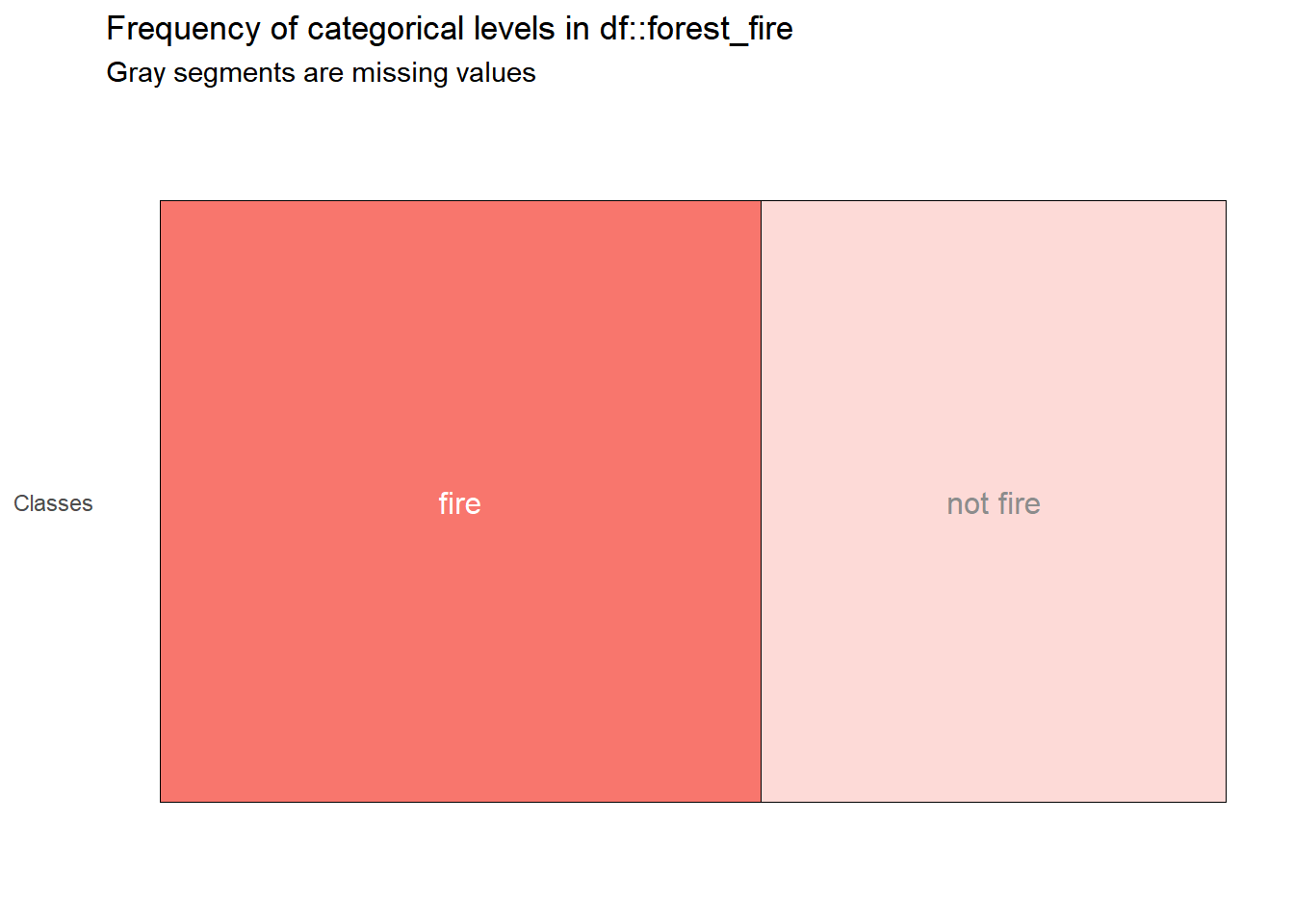
#> 1 Classes 2 fire 56.4 <tibble [2 × 3]>
|
|
#>
#> fire not fire
#> 0.563786 0.436214
Berdasarkan plot diatas, antara kelas fire dan not fire masih cukup balance/seimbang.
Data Pre-Processing
Train-test splitting
Train-test split adalah teknik yang sangat umum digunakan dalam machine learning untuk membagi dataset menjadi dua bagian: satu untuk melatih model (train set) dan yang lainnya untuk menguji kinerja model (test set). Tujuannya adalah untuk mengevaluasi seberapa baik model dapat menggeneralisasi pola dari data yang telah dilihat sebelumnya ke data yang belum pernah dilihat oleh model.

Yang dilakukan dalam proyek ini adalah membagi data menjadi train dan test, test yang dibuat masih sebatas dari data historis yang sama namun hasil pembagian dari data yang tidak diikut sertakan kedalam model fitting. Sedangkan saya tidak membagi menjadi validation.
Untuk memastikan model klasifikasi akurat, saya membagi data menjadi dua set: set pelatihan (training dataset) dan set pengujian (testing dataset). Saya sudah mengetahui sebelumnya kelas-kelas (Classes) untuk set pengujian, dan dengan menggunakan informasi ini saya dapat mengevaluasi akurasi pengklasifikasi dengan memprediksi set pelatihan dengan set pengujian, sehingga memiliki keyakinan yang lebih baik dalam memprediksi kemungkinan kebakaran hutan jika data baru dengan variabel serupa disajikan di masa depan.
Proporsi ditetapkan menjadi 80% karena dataset asli dinilai relatif kecil (244 entri). Dengan membagi menjadi 80%, saya dapat memberikan lebih banyak sampel dari data ke set pelatihan, yang menghasilkan peningkatan akurasi untuk data pengujian saya. Variabel target saya tetap Classes karena itulah variabel yang ingin saya prediksi.
|
|
Kode di atas digunakan untuk membagi dataset forest_fire menjadi dua bagian: set pelatihan (training set) dan set pengujian (testing set):
-
split <- initial_split(forest_fire, prop = 0.80, strata = Classes): Fungsiinitial_splitdari libraryrsampledigunakan untuk membagi datasetforest_fire. Parameterpropdigunakan untuk menentukan proporsi data yang akan dialokasikan ke dalam set pelatihan. Dalam contoh ini, proporsi yang dialokasikan adalah 80% (0.80). Parameterstratadigunakan untuk menentukan variabel yang akan dijadikan dasar bagi pembagian data, dalam hal ini variabelClasses. -
forest_fire_train <- training(split): Menggunakan fungsitraininguntuk mengekstraksi set pelatihan dari objeksplityang telah dibuat sebelumnya. Data yang diekstraksi akan disimpan dalam variabelforest_fire_train. -
forest_fire_test <- testing(split): Menggunakan fungsitestinguntuk mengekstraksi set pengujian dari objeksplit. Data yang diekstraksi akan disimpan dalam variabelforest_fire_test.
Cek data hasil cross validation
Jumlah Baris/Observasi
Untuk melihat jumlah baris antara set pelatihan dan set pengujian, Anda dapat menggunakan fungsi nrow() untuk menghitung jumlah baris (observasi) dalam setiap dataset. Berikut adalah contoh cara melakukannya:
|
|
#> [1] 193
|
|
#> [1] 50
Disini, saya memiliki 194 baris/observasi pada data training dan 50 baris pada data test, permasing-masing baris merepresentasikan data perharinya.
Cek Proporsi Train
|
|
#>
#> fire not fire
#> 0.5647668 0.4352332
Cek Proporsi Test
|
|
#>
#> fire not fire
#> 0.56 0.44
Apply Machine Learning methods
Training a Decision Tree — Using RPart
Rpart adalah singkatan dari Recursive Partitioning and Regression Trees. Ini adalah salah satu teknik paling populer dalam pemodelan prediktif yang digunakan untuk membangun pohon keputusan dalam analisis data. Pohon keputusan adalah model prediktif yang digunakan dalam pemrosesan data dan pembelajaran mesin. Mereka membagi populasi atau sampel menjadi beberapa sub-grup berdasarkan fitur-fitur yang paling penting dalam klasifikasi atau prediksi variabel target.
Ada beberapa alasan mengapa saya menggunakan rpart sebagai alat pemodelan:
-
Kemudahan Implementasi: Rpart sangat mudah diimplementasikan dalam R. Dengan menggunakan fungsi yang sederhana, Anda dapat membuat dan menyesuaikan model pohon keputusan dengan cepat.
-
Interpretasi yang Mudah: Model pohon keputusan dapat dengan mudah diinterpretasikan oleh manusia. Struktur pohon yang dihasilkan mudah dipahami, sehingga hasilnya dapat dijelaskan dengan mudah kepada pemangku kepentingan non-teknis.
-
Tidak Memerlukan Asumsi yang Kuat: Rpart tidak memerlukan asumsi yang kuat tentang distribusi data. Ini dapat digunakan dalam berbagai situasi, termasuk ketika hubungan antara variabel independen dan dependen kompleks atau tidak linier.
-
Penanganan Data yang Fleksibel: Rpart dapat menangani data yang bervariasi dalam jenis dan skala dengan baik. Ini dapat bekerja dengan baik dengan data kategorikal maupun numerik.
-
Performa yang Baik dalam Berbagai Kasus: Rpart sering kali memberikan hasil yang baik dalam pengujian praktis di berbagai bidang, termasuk kesehatan, keuangan, dan teknologi.
Dengan demikian, penggunaan rpart dalam pemodelan memberikan alat yang kuat dan mudah dipahami untuk memprediksi variabel target dari sekumpulan fitur atau variabel independen.
|
|
#> Temperature RH Ws Rain FFMC DMC DC ISI BUI FWI Classes
#> 1 30 73 15 0.0 86.6 12.1 38.3 5.6 13.5 7.1 fire
#> 2 31 65 14 0.0 84.5 12.5 54.3 4.0 15.8 5.6 fire
#> 3 30 78 14 0.0 81.0 6.3 31.6 2.6 8.4 2.2 fire
#> 4 32 62 18 0.1 81.4 8.2 47.7 3.3 11.5 3.8 fire
#> 5 32 66 17 0.0 85.9 11.2 55.8 5.6 14.9 7.5 fire
#> 6 31 64 15 0.0 86.7 14.2 63.8 5.7 18.3 8.4 fire
Tabel 3: Tabel Kebakaran Hutan di Aljazair (Data Training)
Model Fitting
|
|
Berikut penjelasan setiap kode yang digunakan pada fungsi rpart:
model_rpart <- rpart(formula = Classes ~ ., data = forest_fire_train, method = "class"):rpart()adalah fungsi yang digunakan untuk membangun model pohon keputusan.formula = Classes ~ .menunjukkan bahwa variabel target yang ingin diprediksi adalahClasses, dan.mengindikasikan semua variabel prediktor dalam dataset.data = forest_fire_trainmenentukan dataset yang digunakan untuk melatih model, yaituforest_fire_train.method = "class"menunjukkan bahwa saya ingin membangun model untuk klasifikasi kategori, bukan regresi.
Parameter pruning pada paramater control:
- mincriterion: Nilai uji statistik 1-$\alpha$. Saat mincriterion 0.95, P-value harus < 0.05 untuk suatu node dapat membuat cabang. Semakin tinggi nilainya, semakin sulit cabang terbentuk, sehingga menghasilkan cabang yang pendek (default: 0.95)
- minsplit: Jumlah minimal observasi di tiap cabang (internal node) setelah splitting. Bila tidak terpenuhi, tidak dilakukan percabangan. (default: 20)
- minbucket: Jumlah minimal observasi di simpul daun. Bila tidak terpenuhi, tidak dilakukan percabangan. Defaultnya adalah round(minsplit/3)
- maxdepth: Kedalaman maksimum dari setiap simpul pohon akhir, dengan simpul akar dihitung sebagai kedalaman 0. Defaultnya adalah 30.
|
|
#> Call:
#> rpart(formula = Classes ~ ., data = forest_fire_train, method = "class",
#> control = list(minsplit = 5, minbucket = 2))
#> n= 193
#>
#> CP nsplit rel error xerror xstd
#> 1 0.96428571 0 1.00000000 1.00000000 0.08199643
#> 2 0.01190476 1 0.03571429 0.04761905 0.02356150
#> 3 0.01000000 2 0.02380952 0.05952381 0.02627278
#>
#> Variable importance
#> FFMC ISI FWI DC BUI DMC
#> 21 20 18 14 13 13
#>
#> Node number 1: 193 observations, complexity param=0.9642857
#> predicted class=fire expected loss=0.4352332 P(node) =1
#> class counts: 109 84
#> probabilities: 0.565 0.435
#> left son=2 (112 obs) right son=3 (81 obs)
#> Primary splits:
#> FFMC < 80.15 to the right, improve=89.04154, (0 missing)
#> ISI < 2.55 to the right, improve=85.31943, (0 missing)
#> FWI < 3.5 to the right, improve=74.49211, (0 missing)
#> DC < 17.65 to the right, improve=47.00415, (0 missing)
#> BUI < 8.35 to the right, improve=46.10757, (0 missing)
#> Surrogate splits:
#> ISI < 2.45 to the right, agree=0.979, adj=0.951, (0 split)
#> FWI < 2.15 to the right, agree=0.938, adj=0.852, (0 split)
#> DC < 17.65 to the right, agree=0.855, adj=0.654, (0 split)
#> BUI < 7.75 to the right, agree=0.850, adj=0.642, (0 split)
#> DMC < 8.05 to the right, agree=0.845, adj=0.630, (0 split)
#>
#> Node number 2: 112 observations, complexity param=0.01190476
#> predicted class=fire expected loss=0.02678571 P(node) =0.5803109
#> class counts: 109 3
#> probabilities: 0.973 0.027
#> left son=4 (109 obs) right son=5 (3 obs)
#> Primary splits:
#> ISI < 2.65 to the right, improve=2.5243010, (0 missing)
#> FWI < 2.35 to the right, improve=1.8578040, (0 missing)
#> FFMC < 82.1 to the right, improve=1.6392860, (0 missing)
#> DC < 19.05 to the right, improve=0.8585165, (0 missing)
#> BUI < 8.15 to the right, improve=0.8585165, (0 missing)
#> Surrogate splits:
#> FWI < 2.35 to the right, agree=0.991, adj=0.667, (0 split)
#>
#> Node number 3: 81 observations
#> predicted class=not fire expected loss=0 P(node) =0.4196891
#> class counts: 0 81
#> probabilities: 0.000 1.000
#>
#> Node number 4: 109 observations
#> predicted class=fire expected loss=0.009174312 P(node) =0.5647668
#> class counts: 108 1
#> probabilities: 0.991 0.009
#>
#> Node number 5: 3 observations
#> predicted class=not fire expected loss=0.3333333 P(node) =0.01554404
#> class counts: 1 2
#> probabilities: 0.333 0.667
summary(model_rpart):- Fungsi
summary()digunakan untuk mendapatkan ringkasan statistik dari model yang telah dibuat. - Hasilnya akan menampilkan berbagai informasi, termasuk struktur pohon keputusan, akurasi model, dan ukuran lainnya yang dapat membantu dalam evaluasi kinerja model.
Hasil ringkasan model pohon keputusan (
model_rpart) menunjukkan beberapa informasi penting:
- Fungsi
-
Complexity parameter (CP): Parameter kompleksitas mengontrol kompleksitas pohon. Semakin rendah nilai CP, semakin kompleks modelnya. Dalam contoh ini, ada dua nilai CP yang ditunjukkan: 0.9529412 dan 0.01.
-
Variable importance: Menunjukkan pentingnya setiap variabel dalam mempengaruhi keputusan model. Variabel FFMC memiliki tingkat penting tertinggi (21), diikuti oleh ISI (20), FWI (18), BUI (14), DMC (14), dan DC (13).
-
Node information: Membagi node berdasarkan variabel dan nilai yang membagi data. Informasi ini mencakup jumlah observasi di setiap node, kelas yang diprediksi, dan probabilitas kelas.
Secara garis besar, pohon keputusan ini menggambarkan bagaimana data dibagi berdasarkan berbagai variabel prediktor, dan bagaimana pohon ini digunakan untuk membuat prediksi. Pohon ini memiliki dua cabang: satu untuk prediksi “fire” dan yang lainnya untuk prediksi “not fire”.
Untuk memvisualisasikan pohon keputusan ini dengan lebih mudah dipahami, Anda dapat menggunakan paket rpart.plot yang dapat menampilkan struktur pohon keputusan secara grafis. Dengan demikian, Anda dapat melihat bagaimana data dibagi dan bagaimana keputusan diambil berdasarkan variabel prediktor.
Visualisasi Model Rpart
Berikut adalah penjelasan yang lebih rapi mengenai pohon keputusan:
- Struktur Pohon Keputusan:
- Pohon keputusan terdiri dari beberapa bagian: simpul akar (root node), cabang, simpul internal (internal node), dan simpul daun (leaf node).
- Simpul akar adalah kotak pertama di bagian atas plot. Ini membagi data dengan aturan/rules tertentu.
- Setiap cabang berakhir dengan sebuah simpul, yang bisa menjadi simpul internal atau simpul daun, tergantung apakah cabang tersebut membagi data lebih lanjut atau tidak.
- Informasi yang Ditampilkan pada Setiap Simpul/Node:
- Kelas yang diprediksi (Fire/Not Fire).
- Probabilitas kelas Fire/Not Fire.
- Persentase pengamatan dalam simpul tersebut.
- Aturan pemisahan (variabel dengan ambang/bobot) untuk setiap simpul.
- Proses Pemilihan Akar, Pembagian Cabang, dan Pembentukan Simpul:
- Pohon membagi data sehingga simpul yang dihasilkan berisi data dengan kelas yang serupa (homogen) sebanyak mungkin.
- Homogenitas diukur dengan entropi, di mana nilai mendekati 0 menunjukkan homogenitas tinggi dan mendekati 1 menunjukkan heterogenitas.
- Pohon dibangun secara top-down, dimulai dari simpul akar yang dipilih berdasarkan variabel dan aturan kondisional dengan entropi tertinggi.
- Pembagian dilakukan untuk menghasilkan simpul dengan entropi yang berbeda, dengan preferensi terhadap variabel dan aturan yang menghasilkan informasi gain yang lebih tinggi.
- Karakteristik Model Pohon Keputusan:
- Mampu menangani baik variabel numerik maupun kategorikal.
- Semua prediktor diasumsikan berinteraksi.
- Tahan terhadap masalah multikolinieritas dan tidak sensitif terhadap outlier.
- Kelemahan Model Pohon Keputusan:
- Rentan terhadap overfitting jika tidak diprune dengan baik.
- Pruning bisa dilakukan sebelum (pre-pruning) atau setelah (post-pruning) pembangunan model.
- Beberapa parameter seperti
mincriterion,minsplit,minbucket, danmaxdepthdapat diatur untuk mengontrol percabangan pohon.
|
|
|
|
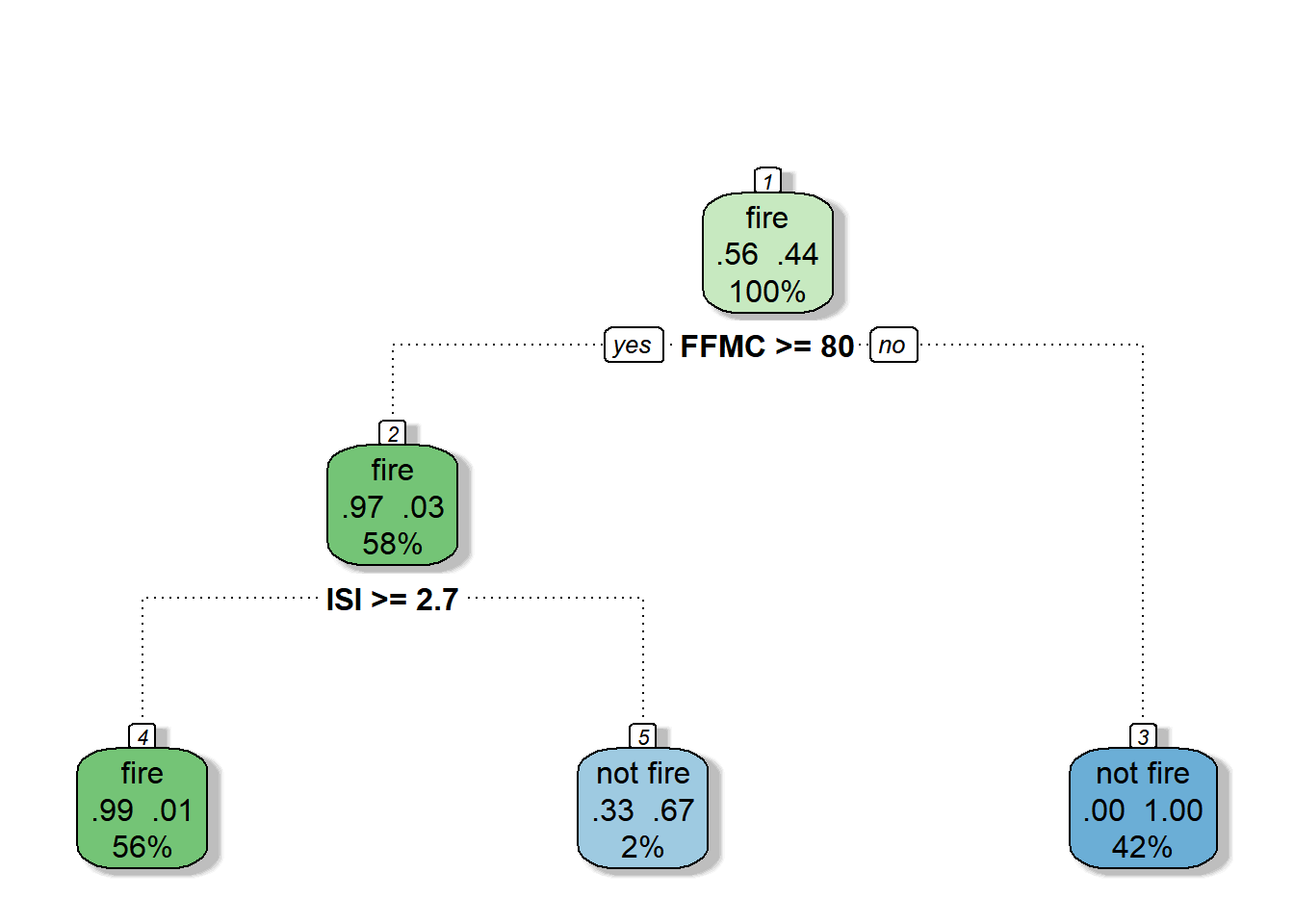
Pertama, interpretasi dimulai dengan melihat node akar (tingkat 0 dari 3, bagian atas grafik).
-
Di bagian atas node akar, menunjukkan probabilitas keseluruhan untuk terjadinya kebakaran (
fire). Ini menunjukkan proporsi terjadi kebakaran atau tidak. 56 % terjadi kebakaran dan 44 % tidak terjadi kebakaran. -
Node akar kemudian mengajukan pertanyaan apakah
Fine Fuel Moisture Code (FFMC)>= 80, Jika ya, maka diarahkan ke node anak kiri (kedalaman 2). Interpretasi menyatakan bahwa 58% FFMC yang nilainya >= 80, dengan probabilitas terjadinya kebakaran sebesar 97% dan FFMC yang nilainya >=80 tidak terjadi kebakaran sebesar 0.3%. -
Pada node kedua, jika aturannya apakah
ISI>= 2,7. Jika ya, maka peluang terjadi kebakaran jika ISI >=2,7 dan memiliki FFMC >= 80 sebesar 99% persen. -
Anda terus melanjutkan seperti itu untuk memahami fitur-fitur apa yang memengaruhi terjadinya kebakaran hutan.
Secara default, fungsi rpart() menggunakan ukuran ketidakmurnian Gini/Gini Impurity untuk membagi simpul/node. Semakin tinggi koefisien Gini, semakin berbeda instansi dalam simpul tersebut. Math behind gini impurity.
|
|
Model Prediction
Kita dapat melakukan prediksi berdasarkan data test. Untuk melakukan prediksi, bisa menggunakan fungsi predict(). Syntax pada R untuk Decision Tree sebagai berikut:
predict(fitted_model, df, type = 'class')
arguments:
fitted_model: Ini adalah objek yang disimpan setelah estimasi model.df: Kerangka dataframe yang digunakan untuk membuat prediksi.type: Jenis prediksi- ‘class’: untuk klasifikasi
- ‘prob’: untuk menghitung probabilitas dari setiap kelas
- ‘vector’: Memprediksi respons rata-rata pada tingkat node.
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 108 1
#> not fire 1 83
#>
#> Accuracy : 0.9896
#> 95% CI : (0.9631, 0.9987)
#> No Information Rate : 0.5648
#> P-Value [Acc > NIR] : <2e-16
#>
#> Kappa : 0.9789
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 0.9908
#> Specificity : 0.9881
#> Pos Pred Value : 0.9908
#> Neg Pred Value : 0.9881
#> Prevalence : 0.5648
#> Detection Rate : 0.5596
#> Detection Prevalence : 0.5648
#> Balanced Accuracy : 0.9895
#>
#> 'Positive' Class : fire
#>
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 28 0
#> not fire 0 22
#>
#> Accuracy : 1
#> 95% CI : (0.9289, 1)
#> No Information Rate : 0.56
#> P-Value [Acc > NIR] : 2.567e-13
#>
#> Kappa : 1
#>
#> Mcnemar's Test P-Value : NA
#>
#> Sensitivity : 1.00
#> Specificity : 1.00
#> Pos Pred Value : 1.00
#> Neg Pred Value : 1.00
#> Prevalence : 0.56
#> Detection Rate : 0.56
#> Detection Prevalence : 0.56
#> Balanced Accuracy : 1.00
#>
#> 'Positive' Class : fire
#>
Model memprediksi dari sekitar 50 kasus yang diprediksi terdapat 28 kasus diprediksi kebakaran, dan ternyata memang betul terjadi kebakaran. Sedangkan 22 kasus lainnya di prediksi tidak terjadi kebakaran, dan sebenarnya memang tidak terjadi kebakaran. Berdasarkan Confusion Matrix table diatas, kita bisa mengukur performance model dengan berbagai macam jenis perhitungan.

False Positive: ditebak sebagai Fire, ternyata No FireFalse Negative: ditebak sebagai No Fire, ternyata Fire
Meminimalisir: False Negative, karena jika terjadi kebakaran dan ditebak tidak ada kebakaran maka sulit untuk mengambil tindakan pencegahan yang tepat.
Untuk meminimalkan false negative, kita perlu fokus pada meningkatkan sensitivitas (recall) model. Sensitivitas adalah kemampuan model untuk mendeteksi semua kasus positif yang sebenarnya (dalam hal ini, mendeteksi kebakaran hutan dengan benar).
Pada model diatas, jika kita fokus pada sensitivitas/recall maka nilainya sebear 100%.
Training a Decision Tree — Using Party
Library party adalah salah satu library di R yang menyediakan algoritma untuk membangun model pohon keputusan dan metode analisis data lainnya.
Model Fitting
|
|
Visualisasi Model Ctree
|
|
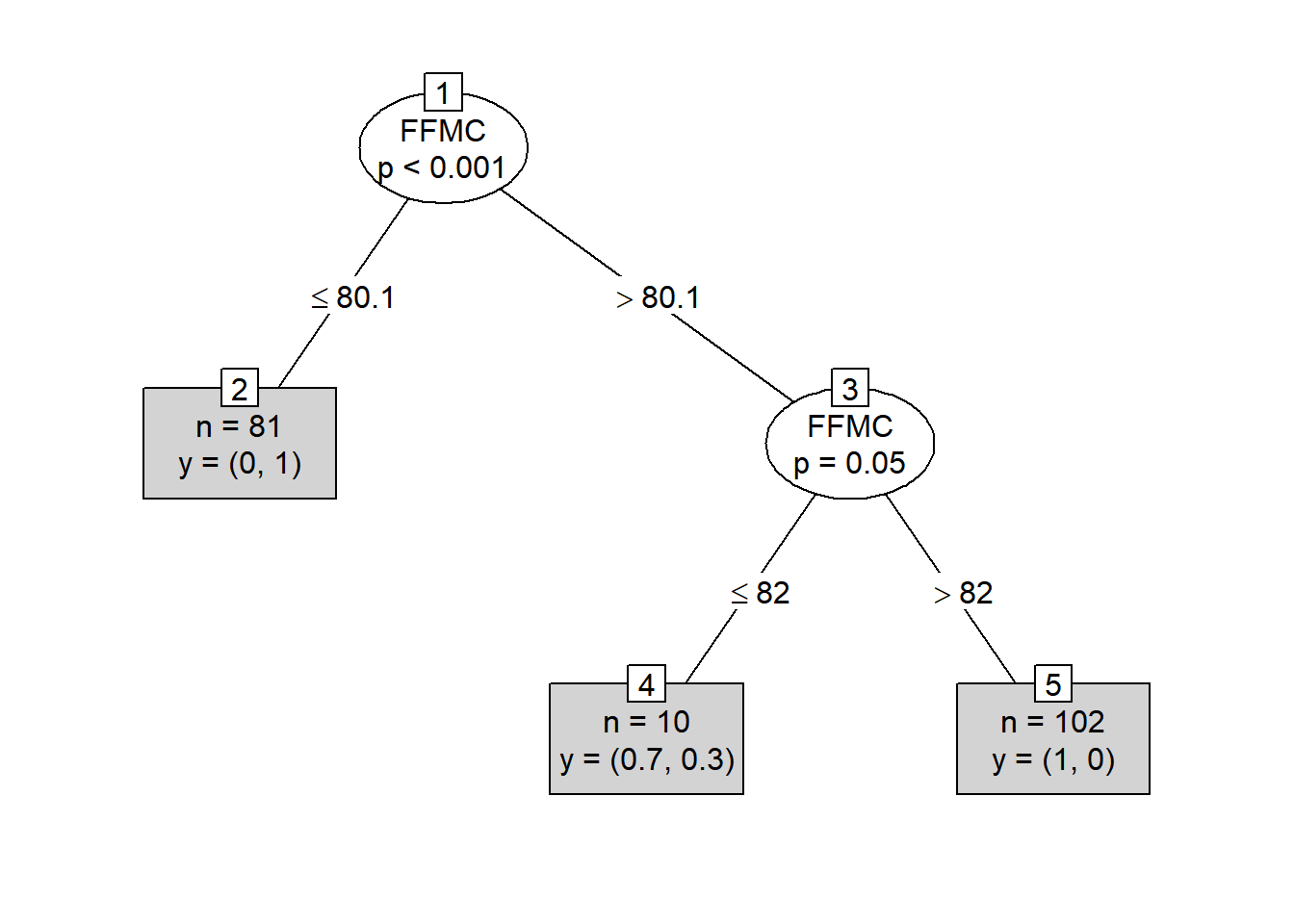
Model Prediction
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 109 3
#> not fire 0 81
#>
#> Accuracy : 0.9845
#> 95% CI : (0.9552, 0.9968)
#> No Information Rate : 0.5648
#> P-Value [Acc > NIR] : <2e-16
#>
#> Kappa : 0.9683
#>
#> Mcnemar's Test P-Value : 0.2482
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9643
#> Pos Pred Value : 0.9732
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5648
#> Detection Rate : 0.5648
#> Detection Prevalence : 0.5803
#> Balanced Accuracy : 0.9821
#>
#> 'Positive' Class : fire
#>
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 28 1
#> not fire 0 21
#>
#> Accuracy : 0.98
#> 95% CI : (0.8935, 0.9995)
#> No Information Rate : 0.56
#> P-Value [Acc > NIR] : 1.034e-11
#>
#> Kappa : 0.9592
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9545
#> Pos Pred Value : 0.9655
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5600
#> Detection Rate : 0.5600
#> Detection Prevalence : 0.5800
#> Balanced Accuracy : 0.9773
#>
#> 'Positive' Class : fire
#>
Training a Decision Tree — Using C5.0
Model Fitting
|
|
#>
#> Call:
#> C5.0.default(x = forest_fire_train[, -11], y = forest_fire_train[, 11])
#>
#>
#> C5.0 [Release 2.07 GPL Edition] Fri May 24 16:16:33 2024
#> -------------------------------
#>
#> Class specified by attribute `outcome'
#>
#> Read 193 cases (11 attributes) from undefined.data
#>
#> Decision tree:
#>
#> FFMC <= 80.1: not fire (81)
#> FFMC > 80.1:
#> :...ISI > 3: fire (102)
#> ISI <= 3:
#> :...DC <= 20.2: not fire (2)
#> DC > 20.2: fire (8/1)
#>
#>
#> Evaluation on training data (193 cases):
#>
#> Decision Tree
#> ----------------
#> Size Errors
#>
#> 4 1( 0.5%) <<
#>
#>
#> (a) (b) <-classified as
#> ---- ----
#> 109 (a): class fire
#> 1 83 (b): class not fire
#>
#>
#> Attribute usage:
#>
#> 100.00% FFMC
#> 58.03% ISI
#> 5.18% DC
#>
#>
#> Time: 0.0 secs
Summary model diatas memberikan informasi menganai model Decision Tree yang telah dibuat menggunakan algoritma C5.0 pada dataset latih (train). Berikut adalah poin-poin hasil summary tersebut:
- Model Decision Tree:
- Model Decision Tree telah dibuat menggunakan algoritma C5.0 dengan atribut
FFMC,ISI, danDCsebagai atribut pemisah. - Model tersebut digunakan untuk memprediksi kelas output, yaitu apakah suatu kebakaran akan terjadi (
fire) atau tidak (not fire).
- Model Decision Tree telah dibuat menggunakan algoritma C5.0 dengan atribut
- Struktur Pohon Keputusan:
- Pohon keputusan terdiri dari beberapa aturan keputusan yang diterapkan pada nilai-nilai atribut input.
- Setiap aturan keputusan berisi kondisi pemisahan dan prediksi kelas output.
- Evaluasi Model pada Data Latih:
- Dari 193 sampel dalam data latih, hanya terdapat 1 kesalahan klasifikasi, yang menyebabkan tingkat kesalahan sebesar 0.5%.
- Terdapat 109 kasus yang diklasifikasikan sebagai
firedan 83 kasus yang diklasifikasikan sebagainot fire.
- Penggunaan Atribut:
- Atribut
FFMCdigunakan dalam 100% aturan keputusan, menunjukkan signifikansi besar dalam memprediksi kelas output. - Atribut
ISIdigunakan dalam 58.03% aturan keputusan, sedangkanDChanya digunakan dalam 5.18% aturan keputusan.
- Atribut
- Waktu Komputasi:
- Proses pembuatan model berlangsung dalam waktu yang sangat cepat, selesai dalam 0.0 detik, hal ini dikarenakan observasi yang digunakan dalam dataset model sangat sedikit.
Hasil ringkasan ini memberikan gambaran tentang kinerja model Decision Tree dalam memprediksi kejadian kebakaran berdasarkan atribut-atribut yang diberikan. Meskipun hasil evaluasi pada data latih menunjukkan kinerja yang baik dengan tingkat kesalahan rendah, penting untuk menguji model pada data uji yang belum pernah dilihat sebelumnya untuk memastikan bahwa model tersebut dapat digeneralisasikan dengan baik pada data baru.
Attribut yang digunakan
Visualisasi Model C5.0
|
|
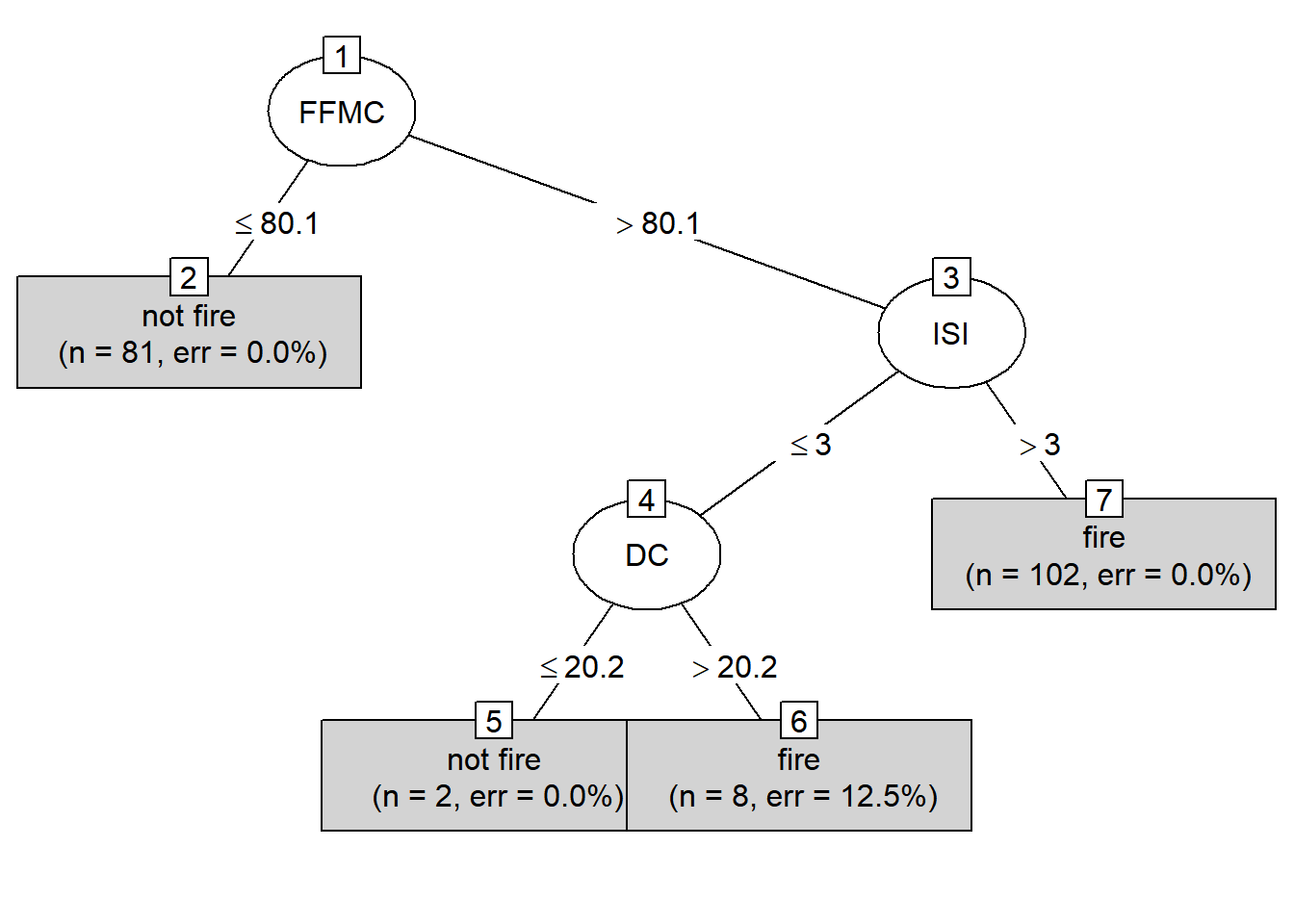
Model Prediction
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 109 1
#> not fire 0 83
#>
#> Accuracy : 0.9948
#> 95% CI : (0.9715, 0.9999)
#> No Information Rate : 0.5648
#> P-Value [Acc > NIR] : <2e-16
#>
#> Kappa : 0.9894
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9881
#> Pos Pred Value : 0.9909
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5648
#> Detection Rate : 0.5648
#> Detection Prevalence : 0.5699
#> Balanced Accuracy : 0.9940
#>
#> 'Positive' Class : fire
#>
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 28 1
#> not fire 0 21
#>
#> Accuracy : 0.98
#> 95% CI : (0.8935, 0.9995)
#> No Information Rate : 0.56
#> P-Value [Acc > NIR] : 1.034e-11
#>
#> Kappa : 0.9592
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9545
#> Pos Pred Value : 0.9655
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5600
#> Detection Rate : 0.5600
#> Detection Prevalence : 0.5800
#> Balanced Accuracy : 0.9773
#>
#> 'Positive' Class : fire
#>
Training a Decision Tree — Using Caret
Model Fitting
|
|
#> Conditional Inference Tree
#>
#> 243 samples
#> 10 predictor
#> 2 classes: 'fire', 'not fire'
#>
#> No pre-processing
#> Resampling: Cross-Validated (10 fold)
#> Summary of sample sizes: 219, 220, 218, 218, 219, 218, ...
#> Resampling results across tuning parameters:
#>
#> mincriterion Accuracy Kappa
#> 0.0100000 0.9791377 0.9568007
#> 0.1188889 0.9791377 0.9568007
#> 0.2277778 0.9791377 0.9568007
#> 0.3366667 0.9791377 0.9568007
#> 0.4455556 0.9791377 0.9568007
#> 0.5544444 0.9791377 0.9568007
#> 0.6633333 0.9791377 0.9568007
#> 0.7722222 0.9791377 0.9568007
#> 0.8811111 0.9791377 0.9568007
#> 0.9900000 0.9791377 0.9568007
#>
#> Accuracy was used to select the optimal model using the largest value.
#> The final value used for the model was mincriterion = 0.99.
Berikut adalah poin-poin hasil summary tersebut:
- Proses Pembuatan Model:
- Model Conditional Inference Tree dibuat tanpa melakukan pre-processing terlebih dahulu.
- Proses resampling dilakukan dengan metode cross-validated (10 fold), yang berarti data dibagi menjadi 10 lipatan/fold dan model diuji menggunakan 10 set data yang berbeda.
- Ringkasan Hasil Resampling:
- Resampling dilakukan dengan memvariasikan parameter tuning
mincriterion. - Dilaporkan hasil akurasi dan kappa untuk setiap nilai
mincriterionyang diuji. - Berbagai nilai mincriterion tidak mempengaruhi akurasi dan kappa, karena keduanya tetap sama (0.9793333 untuk akurasi dan 0.9571349 untuk kappa) di semua nilai
mincriterion.
- Resampling dilakukan dengan memvariasikan parameter tuning
- Seleksi Model:
- Akurasi digunakan sebagai kriteria untuk memilih model terbaik, dan nilai
mincriterionyang menghasilkan akurasi tertinggi dipilih sebagai nilai optimal untuk model. - Pada kasus ini, nilai
mincriterionyang terpilih sebagai model akhir adalah 0.99.
- Akurasi digunakan sebagai kriteria untuk memilih model terbaik, dan nilai
Glossary kappa : Kappa adalah metrik evaluasi yang mengukur tingkat kesepakatan/voting antara dua penilaian atau prediksi berbeda dalam konteks klasifikasi. Rentang nilai kappa adalah dari -1 hingga 1, di mana nilai positif menunjukkan tingkat kesepakatan yang lebih tinggi daripada yang diharapkan secara kebetulan, sementara nilai negatif menunjukkan tingkat kesepakatan yang lebih rendah.
Model Prediction
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 109 3
#> not fire 0 81
#>
#> Accuracy : 0.9845
#> 95% CI : (0.9552, 0.9968)
#> No Information Rate : 0.5648
#> P-Value [Acc > NIR] : <2e-16
#>
#> Kappa : 0.9683
#>
#> Mcnemar's Test P-Value : 0.2482
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9643
#> Pos Pred Value : 0.9732
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5648
#> Detection Rate : 0.5648
#> Detection Prevalence : 0.5803
#> Balanced Accuracy : 0.9821
#>
#> 'Positive' Class : fire
#>
|
|
#> Confusion Matrix and Statistics
#>
#> Reference
#> Prediction fire not fire
#> fire 28 1
#> not fire 0 21
#>
#> Accuracy : 0.98
#> 95% CI : (0.8935, 0.9995)
#> No Information Rate : 0.56
#> P-Value [Acc > NIR] : 1.034e-11
#>
#> Kappa : 0.9592
#>
#> Mcnemar's Test P-Value : 1
#>
#> Sensitivity : 1.0000
#> Specificity : 0.9545
#> Pos Pred Value : 0.9655
#> Neg Pred Value : 1.0000
#> Prevalence : 0.5600
#> Detection Rate : 0.5600
#> Detection Prevalence : 0.5800
#> Balanced Accuracy : 0.9773
#>
#> 'Positive' Class : fire
#>
Perhitungan metrik
Tujuan Decision Tree yaitu memisahkan data menjadi kelompok-kelompok kecil berdasarkan variable tertentu sehingga dihasilkan data yang homogen atau homogenitas tinggi. Ukuran homogenitas dapat dikuantifikasi dengan nilai entropy.
Entropy adalah ukuran ketidakteraturan (measure of disorder) dari sebuah kelompok data.

- Entropy = 1: tidak ada kelas yang dominan (proporsi seimbang, 50:50)
- Entropy = 0: salah satu kelas sangat dominan (proporsi 100:0)
Kelompok data yang diharapkan setelah dilakukan percabangan adalah kelompok yang memiliki entropy rendah.
Untuk memilih prediktor mana yang menjadi root node, dihitunglah perubahan entropy yaitu selisih antara entropy sebelum dan sesudah dilakukan percabangan menggunakan variable predictor.
Predictor yang dipilih adalah predictor yang menghasilkan penurunan entropy paling besar, berarti membuat data setelah pemisahan semakin homogen. Perubahan entropy inilah yang disebut Information Gain.
Prediktor yang dipilih pada setiap percabangan adalah predictor yang menghasilkan information gain terbesar. Berikut adalah perbedaan dalam perhitungan metrik seperti Gini impurity atau entropy di antara keempat model pohon keputusan yang umum digunakan:
rpart (Recursive Partitioning and Regression Trees)
- Algoritma CART (Classification and Regression Trees) yang digunakan oleh
rpartmenggunakan Gini impurity sebagai metrik untuk mengukur ketidakmurnian node. - Gini impurity mengukur seberapa seragam kelas target di dalam node. Semakin rendah nilai Gini impurity, semakin homogen kelasnya.
party
- Algoritma Conditional Inference Trees (CTree) yang digunakan oleh paket
partymenggunakan sebuah pendekatan yang disebut conditional inference framework. - CTree menggunakan uji statistik untuk menilai signifikansi pemisahan node.
- Metrik yang digunakan dalam CTree untuk memilih pemisah node biasanya adalah uji statistik seperti uji chi-square.
C5.0
- Algoritma C5.0, yang digunakan oleh paket
C50, menggunakan metrik gain information atau informasi gain. - Informasi gain mengukur pengurangan dalam ketidakpastian prediksi setelah pemisahan node.
- C5.0 memilih pemisah node yang memberikan penurunan entropi terbesar atau peningkatan informasi yang maksimum.
caret
- Paket
caretmemungkinkan pengguna untuk memilih algoritma pohon keputusan yang berbeda, termasukrpart,party, danC50. - Metrik yang digunakan untuk mengukur ketidakmurnian node dalam
caretbergantung pada algoritma yang dipilih. - Anda dapat menyesuaikan penggunaan Gini impurity, entropy, atau metrik lainnya tergantung pada algoritma yang Anda pilih dalam caret.
Perbedaan dalam perhitungan metrik ini mempengaruhi bagaimana model memutuskan pemisahan node dan pembentukan pohon keputusan. Setiap metode memiliki kelebihan dan kelemahan tergantung pada struktur data dan tujuan pemodelan yang spesifik. Sebagai pengguna, penting untuk memahami bagaimana metrik-metrik ini berfungsi dan memilih algoritma yang sesuai dengan kebutuhan analisis Anda.
Visualisasi untuk membandingkan keakuratan semua metode
|
|
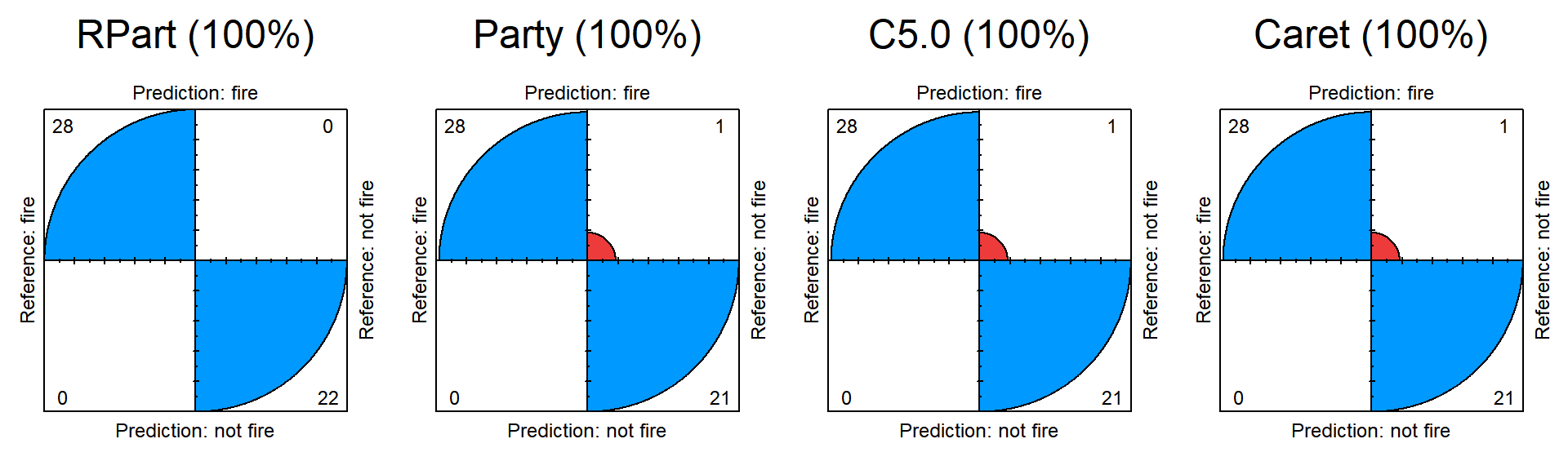
|
|
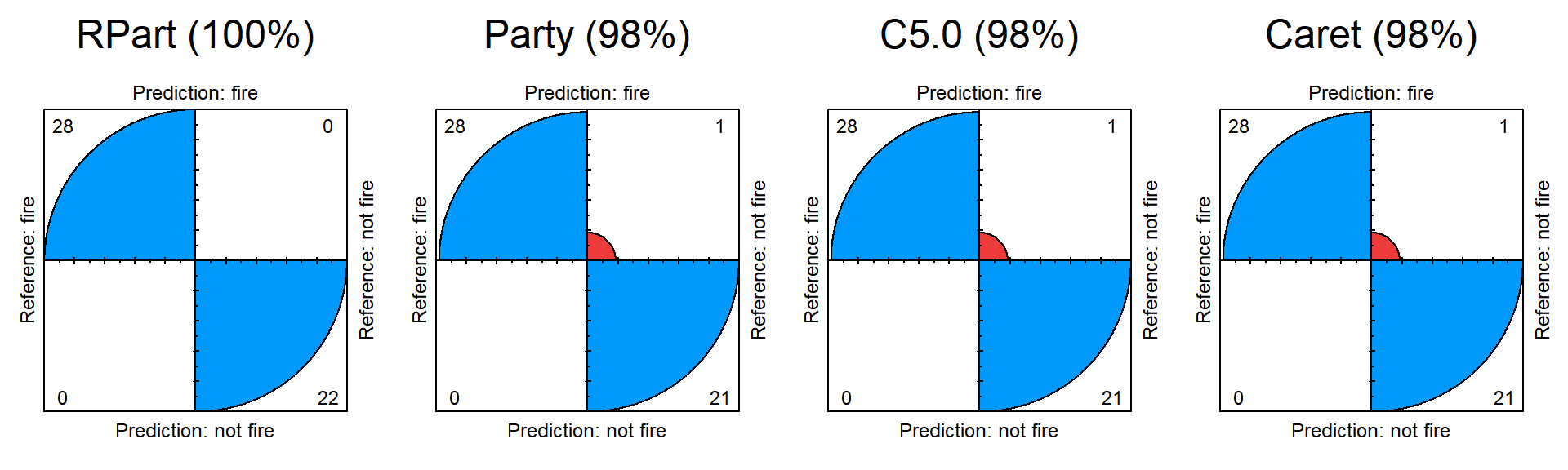
Best model: Model Rpart, recall 100% dan akurasi 100%
Model Evaluation - ROC AUC
|
|
#> [1] 0 0 1 1 1 0
|
|
|
|
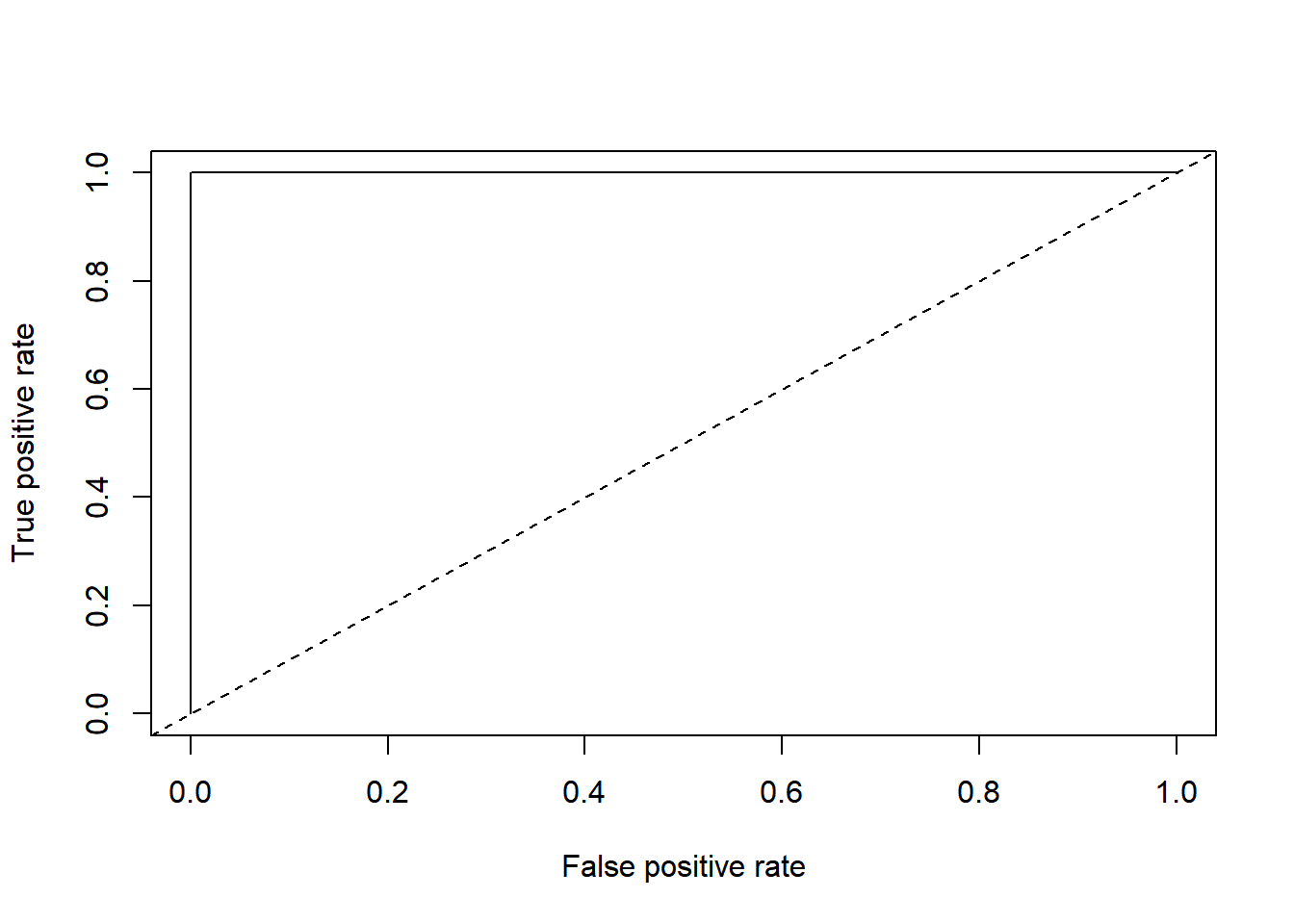
AUC menunjukkan luas area di bawah kurva ROC. Semakin mendekati 1, semakin baik performa model dalam memisahkan kelas positif dan negatif. Untuk mendapatkan nilai AUC, gunakan parameter measure = "auc" pada fungsi performance() kemudian ambil nilai y.values.
|
|
#> [[1]]
#> [1] 1
Interpretation
Pada machine learning model, terdapat trade-off antara sisi interpretability dan performance. Performance model dapat diunggulkan dibandingkan model yang lain, namun tidak terlalu dapat diinterpretasi karena banyak faktor random yang terlibat. Namun setidaknya kita dapat melihat prediktor apa saja yang paling penting dalam pembuatan Random Forest melalui variable importancenya:
|
|
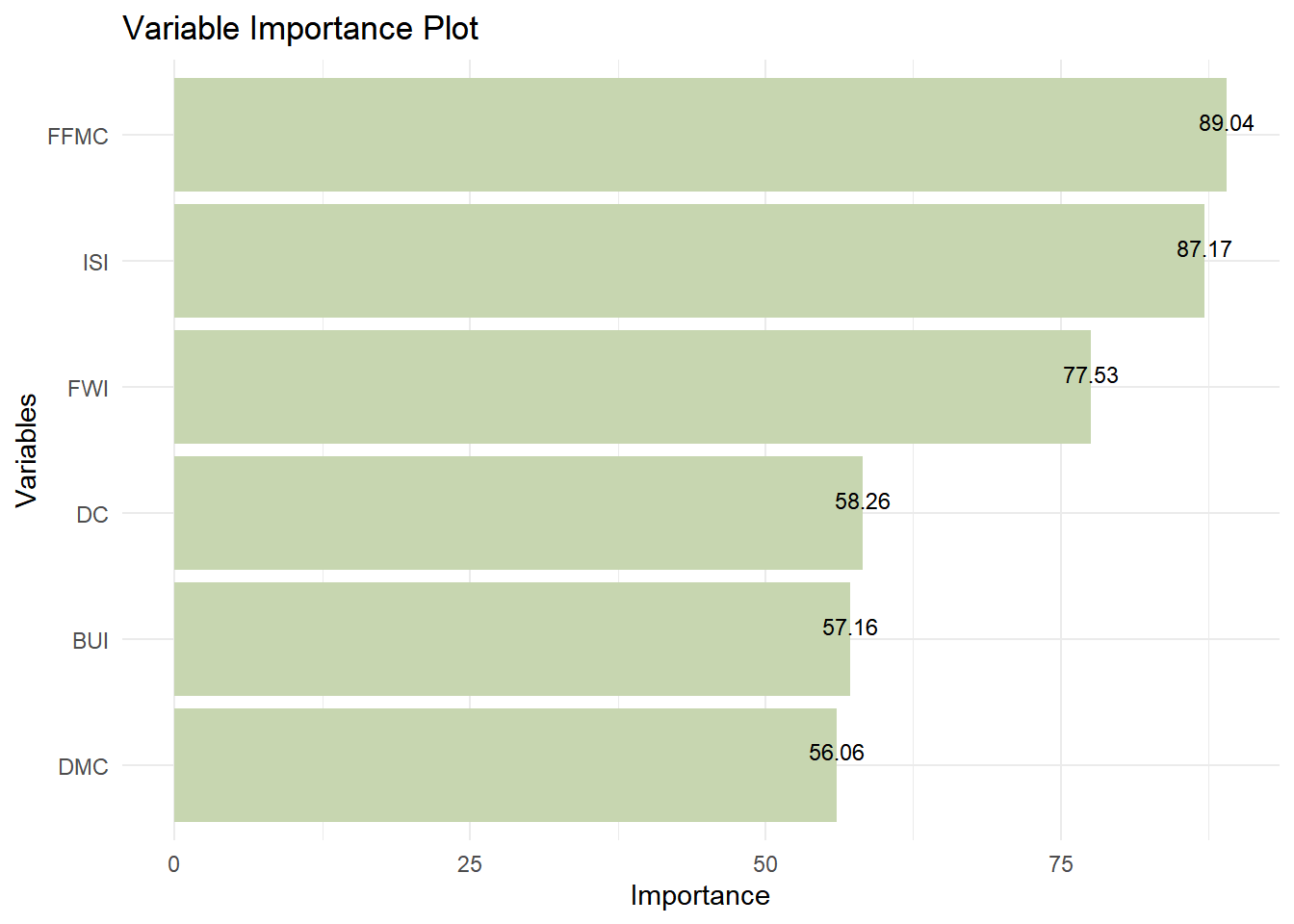
Pada model rpart: Fine Fuel Moisture Code (FFMC) memiliki kepentingan yang tinggi, mengapa? karena FFMC ini merupakan kode yang digunakan sebagai indikator potensi penyulutan api menjadi kebakaran. Nilai FFMC ditentukan dengan menggunakan hasil pengukuran parameter cuaca yaitu suhu udara, kelembaban udara, kecepatan angin, dan curah hujan. Dengan memanfaatkan sensor – sensor yang dapat mengukur parameter tersebut memiliki tingkat varimp paling besar karena faktor-faktor berikut:
-
Relevansi dalam Prediksi: FFMC adalah indikator penting dari tingkat kekeringan dan kemampuan material bakar halus untuk terbakar. Karena kekeringan sangat mempengaruhi risiko kebakaran hutan, variabel ini mungkin memiliki dampak signifikan dalam memprediksi kemungkinan terjadinya kebakaran.
-
Pengaruh Terhadap Hasil Model: Dalam dataset ini, FFMC mungkin menunjukkan korelasi yang kuat dengan variabel target atau kelas yang ingin diprediksi. Jika FFMC memiliki variasi yang signifikan di antara sampel-sampel, maka hal ini dapat mempengaruhi pemisahan simpul pada pohon keputusan.
-
Informasi yang Dapat Dipisahkan: FFMC mungkin memberikan informasi yang paling baik untuk memisahkan kelas-kelas target dalam model. Ini bisa terjadi jika FFMC memiliki tingkat varian yang tinggi di antara kelas-kelas yang berbeda, sehingga membuatnya menjadi kriteria pemisahan yang kuat dalam pohon keputusan.
Oleh karena itu, dalam konteks prediksi kebakaran hutan, FFMC mungkin menjadi salah satu variabel paling penting dalam model rpart karena perannya dalam mencerminkan kondisi kekeringan dan potensi material bakar halus untuk terbakar.
Conclusion
Berdasarkan tabel metrik yang dipilih berdasarkan kepentingan amatan adalah recall. Model yang dibuat yakni dengan membandingkan berbegai macam library yang mendukung klasifikasi untuk decision tree. yakni rpart, party, C5.0, dan caret.
Model prediksi yang dibangun menggunakan algoritma rpart memberikan hasil terbaik. Model tersebut memberikan recall tertinggi 100% sekaligus mempertahankan akurasi, spesifisitas, dan presisi di atas 100% untuk data test. Itu juga memberikan AUC tertinggi di 100%. Oleh karena itu model terbaik untuk memprediksi terjadi kebakaran hutan atau tidak berdasarkan karakteristik cuaca yang ada di kedua wilayah di Algerian yakni Model Rpart.
References
A.Pintoa, J.Espinosa-Prietoa, C. Rossaa, S.Matthewsb, C. Loureiroc, Et All. Modelling Fine Fuel Moisture Content And The Likelihood Of Fire Spread In Blue Gum (Eucalyptus Globulus) Litter. Vii International Conference On Forest Fire Research D. X. Viegas (Ed.), 2014.
Bruce, Peter, and Andrew Bruce. 2017. Practical Statistics for Data Scientists. O’Reilly Media.
James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2014. An Introduction to Statistical Learning: With Applications in R. Springer Publishing Company, Incorporated.
Stuart A. J. A. (2009). Fuel Moisture And Development Of Ignition And Fire Spread Thresholds In Gorse. University Of Canterbury.
Zhang, Zhongheng. 2016. “Decision Tree Modeling Using R.” Annals of Translational Medicine 4 (15).